In diesem Thema
Modell für Vollständig geschachtelte ANOVA
Das geschachtelte ANOVA-Modell für ein balanciertes Design mit zwei Zufallsfaktoren (A und B) wird wie folgt ausgedrückt:
yijk = μ .. + α i+ β j(i) +εijk
Hierbei sind α i, β j(i) und ε ijk unabhängige, normalverteilte Zufallsvariablen mit den Erwartungen 0 und den Varianzen σ2 α, σ2 β bzw. σ2.
Die Parameter werden wie folgt geschätzt:
μ .. = y̅...
α i = yi..− y̅...
β j(i) = yij.− y̅i..
wobei y̅... = Mittelwert aller Beobachtungen, yi.. = Mittelwert der Beobachtungen auf der i-ten Stufe von Faktor A, yij. = Mittelwert der Beobachtungen für die j-te Stufe von Faktor B auf der i-ten Stufe von Faktor A. Der Parameter β j(i) ist der spezifische Effekt von B, wenn sich A auf der i-ten Stufe befindet.
- J. Neter, W. Wasserman und M. H. Kutner (1985). Applied Linear Statistical Models. Second Edition. Irwin, Inc.
Sequenzielle Summe der Quadrate
Die Summe der quadrierten Distanzen. SS Gesamt gibt die Gesamtstreuung der Daten an. SS (A) und SS (B) stellen den Betrag der Streuung des geschätzten Mittelwerts der Faktorstufen um den Gesamtmittelwert dar. Gelegentlich werden sie auch als Summe der Quadrate für Faktor A bzw. Faktor B bezeichnet. SS Fehler ist der Betrag der Streuung der Beobachtungen in Bezug auf ihre angepassten Werte. Die Berechnungen lauten wie folgt:
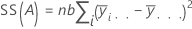
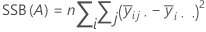
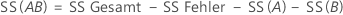


Minitab gibt die sequenzielle Summe der Quadrate aus, die von der Reihenfolge abhängt, in der die Faktoren in das Modell aufgenommen wurden. Es handelt sich um den eindeutigen Anteil der Summe der Quadrate der Regression, die durch einen Faktor erklärt wird, nachdem alle zuvor aufgenommenen Faktoren erklärt wurden.
Notation
| Begriff | Beschreibung |
|---|---|
| a | Anzahl der Stufen in Faktor A |
| b | Anzahl der Stufen in Faktor B |
| n | Gesamtzahl der Versuche |
| yi.. | Mittelwert der i-ten Faktorstufe von Faktor A |
| y... | Gesamtmittelwert aller Beobachtungen |
| y.j. | Mittelwert der j-ten Faktorstufe von Faktor B |
| yij. | Mittelwert der Beobachtungen auf der i-ten Stufe von Faktor A und der j-ten Stufe von Faktor B |
Freiheitsgrade (DF)
Für ein vollständig geschachteltes ANOVA-Modell mit den beiden Faktoren A und B werden die Freiheitsgrade wie folgt ausgedrückt:




Hierbei sind a = Anzahl der Stufen in Faktor A, b = Anzahl der Stufen in Faktor B und n = Anzahl der Versuche.
Mittel der Quadrate (MS)
Formeln

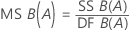

F
Im Folgenden werden die Formeln für F-Statistiken für ein Modell mit Zufallsfaktoren aufgeführt.
Formeln
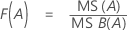

p-Wert – Tabelle der Varianzanalyse
Der p-Wert ist ein Wahrscheinlichkeitsmaß, das aus einer F-Verteilung mit den Freiheitsgraden (DF) wie folgt berechnet wird:
- DF des Zählers
- Summe der Freiheitsgrade für den Term oder die Terme im Test
- DF des Nenners
- Freiheitsgrade für Fehler
Formel
1 − P(F ≤ fj)
Notation
| Begriff | Beschreibung |
|---|---|
| P(F ≤ f) | kumulative Verteilungsfunktion für die F-Verteilung |
| f | F-Statistik für den Test |
Varianzkomponenten
Die Berechnung erfolgt für Zufallsfaktoren. Das geschachtelte Modell mit zwei Zufallsfaktoren sieht wie folgt aus:
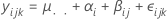
Hierbei sind αi, βj(i) und εijk unabhängige, normalverteilte Zufallsvariablen. Die Variablen sind normalverteilt mit dem Mittelwert null und Varianzen, die angegeben werden durch V(αi) = σ2α, V(βj) = σ2β und V(εijk) = σ2. Es wird angenommen, dass alle bj(i) die gleiche Varianz σ2β aufweisen; σ2α, σ2β, σ2αβ und σ2 werden als Varianzkomponenten bezeichnet.
Erwartetes Mittel der Quadrate
Für ein Modell mit den zwei Zufallsfaktoren A und B wird das erwartete Mittel der Quadrate wie folgt ausgedrückt:
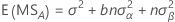


F-Statistik für Modelle mit Zufallsfaktoren
So wird die F-Statistik in der ANOVA-Ausgabe berechnet
Jede F-Statistik stellt ein Verhältnis von Mitteln der Quadrate dar. Der Zähler ist das Mittel der Quadrate für den Term. Der Nenner wird so gewählt, dass sich der erwartete Wert des Mittels der Quadrate im Zähler vom erwarteten Wert des Mittels der Quadrate im Nenner nur durch den relevanten Effekt unterscheidet. Der Effekt für einen Zufallsterm wird durch die Varianzkomponente des Terms dargestellt. Der Effekt für einen festen Term wird durch die Summe der Quadrate der diesem Term entsprechenden Modellkomponenten dividiert durch seine Freiheitsgrade dargestellt. Daher weist eine hohe F-Statistik auf einen signifikanten Effekt hin.
Wenn alle Terme im Modell fest sind, ist der Nenner für jede F-Statistik das mittlere Fehlerquadrat (MSE). Für Modelle, die Zufallsterme enthalten, ist MSE hingegen nicht immer das richtige Mittel der Quadrate. Anhand des erwarteten Mittels der Quadrate (EMS) kann bestimmt werden, welches für den Nenner geeignet ist.
Beispiel
| Quelle | Erwartetes Mittel der Quadrate für jeden Term |
|---|---|
| (1) Bildschirm | (4) + 2,0000(3) + Q[1] |
| (2) Techniker | (4) + 2,0000(3) + 4,0000(2) |
| (3) Bildschirm*Techniker | (4) + 2,0000(3) |
| (4) Fehler | (4) |
Eine Zahl in Klammern gibt einen Zufallseffekt an, der dem neben der Quellennummer aufgelisteten Term zugeordnet ist. (2) stellt den Zufallseffekt von „Techniker“ dar, (3) den Zufallseffekt der Wechselwirkung „Bildschirm*Techniker“ und (4) den Zufallseffekt von „Fehler“. Das EMS für „Fehler“ ist der Effekt des Fehlerterms. Zudem ist das EMS für „Bildschirm*Techniker“ der Effekt des Fehlerterms zuzüglich des doppelten Effekts der Wechselwirkung „Bildschirm*Techniker“.
Zum Berechnen der F-Statistik für „Folie*Tech“ wird das Mittel der Quadrate für „Folie*Tech“ durch das Mittel der Quadrate des Fehlers dividiert, sodass sich der erwartete Wert des Zählers (EMS für Folie*Tech = (4) + 2.0000(3)) vom erwarteten Wert des Nenners (EMS für Fehler = (4)) nur durch den Effekt der Wechselwirkung (2,0000(3)) unterscheidet. Daher zeigt eine hohe F-Statistik eine signifikante Wechselwirkung „Bildschirm*Techniker“ an.
Eine Zahl mit Q[ ] gibt den festen Effekt für den Term an, der neben der Quellennummer aufgelistet ist. So ist Q[1] beispielsweise der feste Effekt von „Bildschirm“. Das EMS für „Bildschirm“ ist der Effekt des Fehlerterms zuzüglich des doppelten Effekts der Wechselwirkung „Bildschirm*Techniker“ plus ein konstantes Vielfaches des Effekts von „Bildschirm“. Q[1] ist gleich (b*n * sum((Koeffizienten für Stufen von „Bildschirm“)**2)) dividiert durch (a – 1), wobei a und b die Anzahl der Stufen von „Bildschirm“ und „Techniker“ sind und n die Anzahl der Replikationen angibt.
Zum Berechnen der F-Statistik für „Bildschirm“ wird das Mittel der Quadrate für „Bildschirm“ durch das Mittel der Quadrate für „Bildschirm*Techniker“ dividiert, so dass sich der erwartete Wert des Zählers (EMS für „Bildschirm“ = (4) + 2,0000(3) + Q[1]) vom erwarteten Wert des Nenners (EMS für „Bildschirm*Techniker“ = (4) + 2,0000(3)) nur durch den Effekt von „Bildschirm“ (Q[1]) unterscheidet. Daher weist eine hohe F-Statistik auf einen signifikanten Effekt von „Bildschirm“ hin.
Weshalb enthält die ANOVA-Ausgabe ein „x“ neben einem p-Wert in der ANOVA-Tabelle sowie die Beschriftung „Kein genauer F-Test“?
In einem genauen F-Test für einen Term unterscheidet sich der erwartete Wert des Mittels der Quadrate für den Zähler vom erwarteten Wert des Mittels der Quadrate für den Nenner nur durch die Varianzkomponente bzw. den festen Faktor von Interesse.
Gelegentlich kann ein solches Mittel der Quadrate jedoch nicht berechnet werden. In einem solchen Fall verwendet Minitab ein Mittel der Quadrate, das zu einem annähernden F-Test führt, und zeigt ein „x“ neben dem p-Wert an, um anzugeben, dass der F-Test nicht genau ist.
| Quelle | Erwartetes Mittel der Quadrate für jeden Term |
|---|---|
| (1) Zusatz | (4) + 1,7500(3) + Q[1] |
| (2) See | (4) + 1,7143(3) + 5,1429(2) |
| (3) Zusatz*See | (4) + 1,7500(3) |
| (4) Fehler | (4) |
Die F-Statistik für „Zusatz“ ist das Mittel der Quadrate für „Zusatz“ dividiert durch das Mittel der Quadrate für die Wechselwirkung „Zusatz*See“. Wenn der Effekt für „Zusatz“ sehr klein ist, ist der erwartete Wert des Zählers gleich dem erwarteten Wert des Nenners. Dies ist ein Beispiel für einen genauen F-Test.
Beachten Sie jedoch, dass für einen sehr kleinen Effekt von „See“ kein Mittel der Quadrate vorliegt, bei dem der erwartete Wert des Zählers gleich dem erwarteten Wert des Nenners ist. Daher verwendet Minitab einen annähernden F-Test. In diesem Beispiel wird das Mittel der Quadrate für „See“ durch das Mittel der Quadrate für die Wechselwirkung „Zusatz*See“ dividiert. Dadurch wird ein erwarteter Wert des Zählers erhalten, der annähernd gleich dem des Nenners ist, wenn der Effekt von „See“ sehr klein ist.
Informationen zur Meldung „Nenner von F-Test ist null oder nicht definiert“
- Für den Fehler ist nicht mindestens ein Freiheitsgrad vorhanden.
-
Die korrigierten MS-Werte sind sehr klein, und damit ist keine ausreichende Genauigkeit zur Anzeige der F-Statistik und der p-Werte gegeben. Mögliche Problemumgehung: Multiplizieren Sie die Antwortspalte mit 10. Führen Sie anschließend dasselbe Regressionsmodell aus, wobei Sie jedoch diese neue Antwortspalte als Antwortvariable verwenden.
Hinweis
Das Multiplizieren der Werte der Antwortvariablen mit 10 wirkt sich nicht auf die F-Statistik und die p-Werte aus, die Minitab in der Ausgabe anzeigt. Die Position des Dezimalkommas in der übrigen Ausgabe ist jedoch betroffen, insbesondere die Spalten für die sequenzielle Summe der Quadrate, Kor SS, Kor MS, Anpassung, Standardfehler der Anpassungen und Residuen.
So wird die F-Statistik in der ANOVA-Ausgabe berechnet
Jede F-Statistik stellt ein Verhältnis von Mitteln der Quadrate dar. Der Zähler ist das Mittel der Quadrate für den Term. Der Nenner wird so gewählt, dass sich der erwartete Wert des Mittels der Quadrate im Zähler vom erwarteten Wert des Mittels der Quadrate im Nenner nur durch den relevanten Effekt unterscheidet. Der Effekt für einen Zufallsterm wird durch die Varianzkomponente des Terms dargestellt. Der Effekt für einen festen Term wird durch die Summe der Quadrate der diesem Term entsprechenden Modellkomponenten dividiert durch seine Freiheitsgrade dargestellt. Daher weist eine hohe F-Statistik auf einen signifikanten Effekt hin.
Wenn alle Terme im Modell fest sind, ist der Nenner für jede F-Statistik das mittlere Fehlerquadrat (MSE). Für Modelle, die Zufallsterme enthalten, ist MSE hingegen nicht immer das richtige Mittel der Quadrate. Anhand des erwarteten Mittels der Quadrate (EMS) kann bestimmt werden, welches für den Nenner geeignet ist.
Beispiel
| Quelle | Erwartetes Mittel der Quadrate für jeden Term |
|---|---|
| (1) Bildschirm | (4) + 2,0000(3) + Q[1] |
| (2) Techniker | (4) + 2,0000(3) + 4,0000(2) |
| (3) Bildschirm*Techniker | (4) + 2,0000(3) |
| (4) Fehler | (4) |
Eine Zahl in Klammern gibt einen Zufallseffekt an, der dem neben der Quellennummer aufgelisteten Term zugeordnet ist. (2) stellt den Zufallseffekt von „Techniker“ dar, (3) den Zufallseffekt der Wechselwirkung „Bildschirm*Techniker“ und (4) den Zufallseffekt von „Fehler“. Das EMS für „Fehler“ ist der Effekt des Fehlerterms. Zudem ist das EMS für „Bildschirm*Techniker“ der Effekt des Fehlerterms zuzüglich des doppelten Effekts der Wechselwirkung „Bildschirm*Techniker“.
Zum Berechnen der F-Statistik für „Folie*Tech“ wird das Mittel der Quadrate für „Folie*Tech“ durch das Mittel der Quadrate des Fehlers dividiert, sodass sich der erwartete Wert des Zählers (EMS für Folie*Tech = (4) + 2.0000(3)) vom erwarteten Wert des Nenners (EMS für Fehler = (4)) nur durch den Effekt der Wechselwirkung (2,0000(3)) unterscheidet. Daher zeigt eine hohe F-Statistik eine signifikante Wechselwirkung „Bildschirm*Techniker“ an.
Eine Zahl mit Q[ ] gibt den festen Effekt für den Term an, der neben der Quellennummer aufgelistet ist. So ist Q[1] beispielsweise der feste Effekt von „Bildschirm“. Das EMS für „Bildschirm“ ist der Effekt des Fehlerterms zuzüglich des doppelten Effekts der Wechselwirkung „Bildschirm*Techniker“ plus ein konstantes Vielfaches des Effekts von „Bildschirm“. Q[1] ist gleich (b*n * sum((Koeffizienten für Stufen von „Bildschirm“)**2)) dividiert durch (a – 1), wobei a und b die Anzahl der Stufen von „Bildschirm“ und „Techniker“ sind und n die Anzahl der Replikationen angibt.
Zum Berechnen der F-Statistik für „Bildschirm“ wird das Mittel der Quadrate für „Bildschirm“ durch das Mittel der Quadrate für „Bildschirm*Techniker“ dividiert, so dass sich der erwartete Wert des Zählers (EMS für „Bildschirm“ = (4) + 2,0000(3) + Q[1]) vom erwarteten Wert des Nenners (EMS für „Bildschirm*Techniker“ = (4) + 2,0000(3)) nur durch den Effekt von „Bildschirm“ (Q[1]) unterscheidet. Daher weist eine hohe F-Statistik auf einen signifikanten Effekt von „Bildschirm“ hin.
Weshalb enthält die ANOVA-Ausgabe ein „x“ neben einem p-Wert in der ANOVA-Tabelle sowie die Beschriftung „Kein genauer F-Test“?
In einem genauen F-Test für einen Term unterscheidet sich der erwartete Wert des Mittels der Quadrate für den Zähler vom erwarteten Wert des Mittels der Quadrate für den Nenner nur durch die Varianzkomponente bzw. den festen Faktor von Interesse.
Gelegentlich kann ein solches Mittel der Quadrate jedoch nicht berechnet werden. In einem solchen Fall verwendet Minitab ein Mittel der Quadrate, das zu einem annähernden F-Test führt, und zeigt ein „x“ neben dem p-Wert an, um anzugeben, dass der F-Test nicht genau ist.
| Quelle | Erwartetes Mittel der Quadrate für jeden Term |
|---|---|
| (1) Zusatz | (4) + 1,7500(3) + Q[1] |
| (2) See | (4) + 1,7143(3) + 5,1429(2) |
| (3) Zusatz*See | (4) + 1,7500(3) |
| (4) Fehler | (4) |
Die F-Statistik für „Zusatz“ ist das Mittel der Quadrate für „Zusatz“ dividiert durch das Mittel der Quadrate für die Wechselwirkung „Zusatz*See“. Wenn der Effekt für „Zusatz“ sehr klein ist, ist der erwartete Wert des Zählers gleich dem erwarteten Wert des Nenners. Dies ist ein Beispiel für einen genauen F-Test.
Beachten Sie jedoch, dass für einen sehr kleinen Effekt von „See“ kein Mittel der Quadrate vorliegt, bei dem der erwartete Wert des Zählers gleich dem erwarteten Wert des Nenners ist. Daher verwendet Minitab einen annähernden F-Test. In diesem Beispiel wird das Mittel der Quadrate für „See“ durch das Mittel der Quadrate für die Wechselwirkung „Zusatz*See“ dividiert. Dadurch wird ein erwarteter Wert des Zählers erhalten, der annähernd gleich dem des Nenners ist, wenn der Effekt von „See“ sehr klein ist.
Informationen zur Meldung „Nenner von F-Test ist null oder nicht definiert“
- Für den Fehler ist nicht mindestens ein Freiheitsgrad vorhanden.
-
Die korrigierten MS-Werte sind sehr klein, und damit ist keine ausreichende Genauigkeit zur Anzeige der F-Statistik und der p-Werte gegeben. Mögliche Problemumgehung: Multiplizieren Sie die Antwortspalte mit 10. Führen Sie anschließend dasselbe Regressionsmodell aus, wobei Sie jedoch diese neue Antwortspalte als Antwortvariable verwenden.
Hinweis
Das Multiplizieren der Werte der Antwortvariablen mit 10 wirkt sich nicht auf die F-Statistik und die p-Werte aus, die Minitab in der Ausgabe anzeigt. Die Position des Dezimalkommas in der übrigen Ausgabe ist jedoch betroffen, insbesondere die Spalten für die sequenzielle Summe der Quadrate, Kor SS, Kor MS, Anpassung, Standardfehler der Anpassungen und Residuen.