In diesem Thema
Systematische Messabweichung
Die systematische Messabweichung ist ein Maß für die Genauigkeit eines Messsystems. Die systematische Messabweichung wird als Differenz zwischen dem bekannten Standardwert eines Referenzteils und dem beobachteten Durchschnittsmesswert berechnet.
Interpretation
- Eine positive systematische Messabweichung bedeutet, dass das Messgerät zu hohe Messwerte liefert.
- Eine negative systematische Messabweichung bedeutet, dass das Messgerät zu niedrige Messwerte liefert.
Bei einem Messgerät, das präzise misst, ist die %systematische Messabweichung gering. Bestimmen Sie mit Hilfe des p-Werts, ob die systematische Messabweichung statistisch signifikant ist.
Wiederholbarkeit und Wiederholbarkeit vor Korrektur
Als Wiederholbarkeit wird der Streuungsgrad im Messsystem bezeichnet, der auf das Messgerät zurückzuführen ist. Bei einer Messsystemanalyse für attributive Daten wird eine Regression der Annahmewahrscheinlichkeit auf die Referenzwerte ausgeführt, um die Wiederholbarkeit zu ermitteln.
Die Wiederholbarkeit vor Korrektur ist die Wiederholbarkeit, die vor der Korrektur von Überschätzungen berechnet wird. Minitab dividiert die Schätzwerte der Wiederholbarkeit durch den Korrekturfaktur 1,08, um die korrigierte Wiederholbarkeit zu berechnen. Der Korrekturfaktor 1,08 stammt von der Automotive Industry Action Group (AIAG)1.
Interpretation
Ein niedriger Wiederholbarkeitswert bedeutet, dass das Messgerät beständig misst. Ein hoher Wiederholbarkeitswert zeigt eine zufällige Streuung oder Probleme wie eine unpassende Auswahl von Teilen oder ein unzureichendes Messgerät.
Minitab verwendet den korrigierten Wiederholbarkeitswert beim Testen der Nullhypothese, ob die systematische Messabweichung gleich 0 ist.
Wahrscheinlichkeitsnetz für Normalverteilung
Im Wahrscheinlichkeitsnetz für Normalverteilung wird der Prozentsatz der Annahmen für jeden Referenzwert dargestellt. Da keine tatsächlichen Messwerte vom Messsystem verfügbar sind, um die systematische Messabweichung und Wiederholbarkeit zu schätzen, berechnet Minitab die systematische Messabweichung und Wiederholbarkeit durch Anpassen der Normalverteilungskurve mit Hilfe der berechneten Annahmewahrscheinlichkeiten und dem bekannten Referenzwert für alle Teile.
Wenn die Messfehler einer Normalverteilung folgen, liegen die berechneten Wahrscheinlichkeiten entlang einer Geraden. Eine Regressionslinie wird an die Wahrscheinlichkeiten angepasst.
Interpretation
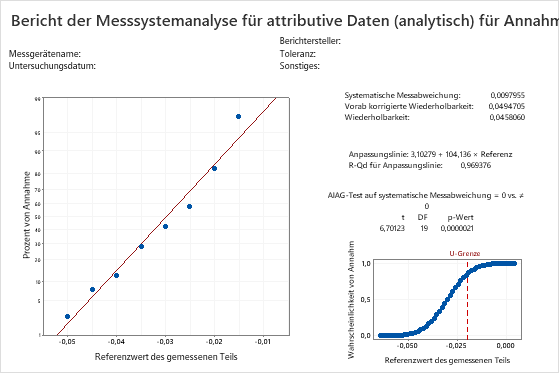
Anpassungslinie
Die Annahmewahrscheinlichkeit für jedes Teil wird berechnet und in einem Wahrscheinlichkeitsnetz für Normalverteilung dargestellt. In einem Wahrscheinlichkeitsnetz für Normalverteilung ist der y-Wert eines dargestellten Punktes = Φ–1(Annahmewahrscheinlichkeit), wobei Φ–1 die Umkehrung der kumulativen Verteilungsfunktion der Standardnormalverteilung ist.
Eine angepasste Regressionslinie wird durch die dargestellten Punkte gezeichnet.
Interpretation
Wenn die Anpassungslinie eine gute Anpassung für die dargestellten Punkte bietet, berechnet Minitab mit den Werten für den Schnittpunkt mit der y-Achse und die Steigung die Werte für die systematische Messabweichung und Wiederholbarkeit.
Diese Grafik zeigt, dass die Anpassungslinie gut an die Daten angepasst ist.
R-Qd für Anpassungslinie
Der R-Qd-Wert (R2) für die angepasste Regressionslinie gibt die prozentuale Streuung in den Werten der Antwortvariablen für die Annahmewahrscheinlichkeit an, die durch das Regressionsmodell erklärt wird.
Interpretation
R2 kann im Bereich von 0 bis 100 % liegen. Im Allgemeinen gilt: Je höher der R2-Wert, desto besser ist das Modell an die Daten angepasst. R2-Werte, die größer als 90 % sind, verweisen in der Regel auf eine sehr gute Anpassung an die Daten.
Für dieses Beispiel beträgt der R-Qd-Wert 0,969376. Die Anpassungslinie ist sehr gut an die Daten angepasst, und das Modell erklärt nahezu 97 % der Varianz.
t
t ist die t-Statistik für die Alternativhypothese, dass die systematische Messabweichung ≠ 0 ist.
Beim t-Test wird diese beobachtete t-Statistik mit einem kritischen Wert aus der t-Verteilung mit (n-1) Freiheitsgraden verglichen, um zu bestimmen, ob die systematische Messabweichung im Messsystem statistisch signifikant ist.
DF
Der Wert für die Freiheitsgrade (DF) wird verwendet, um den p-Wert zu ermitteln. Für die AIAG-Methode ist DF = Anzahl der Versuche – 1. Für die Regressionsmethode ist DF gleich der Anzahl der Punkte zum Erstellen der Anpassungslinie – 2.
p-Wert
Um zu bestimmen, ob die systematische Messabweichung des Messsystems statistisch signifikant ist, vergleichen Sie den p-Wert mit dem Signifikanzniveau. In der Regel ist ein Signifikanzniveau (als α oder Alpha bezeichnet) von 0,05 gut geeignet. Ein Signifikanzniveau von 0,05 bedeutet ein Risiko der Schlussfolgerung, dass eine signifikante systematische Messabweichung vorliegt, wenn dies tatsächlich nicht der Fall ist, von 5 %.
Interpretation
Ein kleinerer p-Wert liefert stärkere Anzeichen dafür, dass die Nullhypothese nicht zutrifft. Wenn der p-Wert kleiner als der α-Wert ist, können Sie die Nullhypothese zurückweisen, dass die systematische Messabweichung im Messsystem gleich 0 ist.
Leistungskurve des Messsystems
Die Leistungskurve des Messgeräts stellt die geschätzte Annahmewahrscheinlichkeit als Funktion des Referenzwerts für das Prüfobjekt dar. Die vertikale Referenzlinie zeigt die für die Analyse eingegebenen Grenzwerte an.
Interpretation
Wenn Sie eine untere Toleranzgrenze angeben, weisen die Referenzwerte und Annahmewahrscheinlichkeiten einen ansteigenden Trend auf. Wenn Sie eine obere Toleranzgrenze angeben, nehmen die Annahmewahrscheinlichkeiten bei höheren Referenzwerten ab.
Wenn für ein Messsystem eine obere und eine untere Spezifikationsgrenze vorhanden sind und Linearität und Gleichmäßigkeit des Fehlers angenommen werden können, können Sie auf der Leistungskurve des Messsystems sowohl die obere als auch die untere Toleranzgrenze anzeigen. Die Kurve wird als Spiegelbild dargestellt.
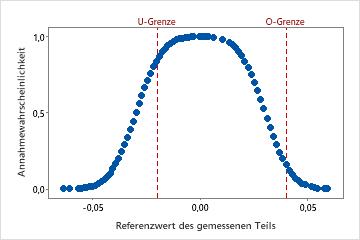
Für diese Daten besteht eine hohe Wahrscheinlichkeit, dass ein Prüfobjekt bei der unteren Toleranzgrenze (U-Grenze) von –0,020 angenommen wird. Die Annahmewahrscheinlichkeit nimmt mit dem Anstieg der Referenzwerte bis zum Referenzwert 0,01 zu. Anschließend nimmt die Annahmewahrscheinlichkeit ab. Die Annahmewahrscheinlichkeit bei der oberen Toleranzgrenze (O-Grenze) beträgt ca. 0,15.