In diesem Thema
Wahrscheinlichkeitsnetze
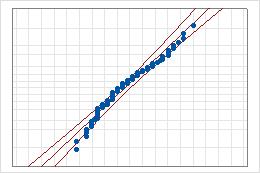
- Mittellinie
- Das erwartete Perzentil aus der Verteilung auf der Grundlage der geschätzten Maximum-Likelihood-Parameter.
- Linien der Konfidenzgrenzen
- Die gekrümmte Linie links bildet die Untergrenzen der Konfidenzintervalle für die Perzentile ab. Die gekrümmte Linie rechts bildet die Obergrenzen der Konfidenzintervalle für die Perzentile ab.
- Anderson-Darling-Teststatistik und p-Wert
- Die Ergebnisse eines Tests, mit dem ermittelt wird, ob die Daten der Verteilung folgen.
Interpretation
Verwenden Sie die Wahrscheinlichkeitsnetze, um zu ermitteln, wie gut die Nicht-Normalverteilung an jede Variable angepasst ist.
Wenn die Verteilung gut an die Daten angepasst ist, sollten die Punkte annähernd eine Gerade bilden. Abweichungen von dieser Geraden weisen darauf hin, dass die Anpassung nicht akzeptabel ist. Wenn der p-Wert größer als 0,05 ist, können Sie schlussfolgern, dass die Daten der für die Analyse verwendeten Nicht-Normalverteilung folgen.
Hinweis
Wenn die Verteilungen für mehrere Variablen voneinander abweichen, sollten Sie für jede Variable eine separate Prozessfähigkeitsanalyse mit einer anderen Verteilung ausführen.
Histogramm der Prozessfähigkeit
Interpretation
Verwenden Sie das Histogramm der Prozessfähigkeit, um die Stichprobendaten in Bezug auf die Verteilungsanpassung und die Spezifikationsgrenzen anzuzeigen.
- Suchen nach Anzeichen einer fehlenden Anpassung der ausgewählten Nicht-Normalverteilung für die Daten
-
Vergleichen Sie für jede Variable die Verteilungskurve mit den Balken des Histogramms, um zu untersuchen, ob die Daten der Verteilung folgen, die Sie für die Analyse ausgewählt haben. Wenn die Balken stark von der Kurve abweichen, folgen die Daten möglicherweise nicht der ausgewählten Verteilung, und die Schätzungen der Prozessfähigkeit für den Prozess sind u. U. nicht zuverlässig. Wenn Sie unsicher sind, welche Verteilung für Ihre Daten am besten geeignet ist, bestimmen Sie mit Hilfe von Identifikation der Verteilung eine geeignete Verteilung oder Transformation.
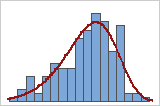
Gute Anpassung
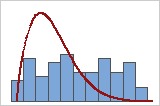
Schlechte Anpassung
Wichtig
Die Histogramme liefern nur eine ungefähre Abbildung der Anpassung der Verteilung. Verwenden Sie die Ergebnisse auf den Wahrscheinlichkeitsnetzen, um die Verteilungsanpassung eingehender zu beurteilen. Wenn die Verteilungen für mehrere Variablen voneinander abweichen, sollten Sie für jede Variable eine separate Prozessfähigkeitsanalyse mit einer anderen Verteilung ausführen.
- Untersuchen der Stichprobendaten in Bezug auf die Spezifikationsgrenzen
- Untersuchen Sie die Daten für jede Variable im Histogramm visuell in Bezug auf die untere und die obere Spezifikationsgrenze. Im Idealfall ist die Streubreite der Daten geringer als die Spezifikationsstreubreite, und alle Daten liegen innerhalb der Spezifikationsgrenzen. Daten, die außerhalb der Spezifikationsgrenzen liegen, stellen unzulängliche Teile dar. Im Idealfall liegen nur wenige oder überhaupt keine Teile außerhalb der Spezifikationsgrenzen.
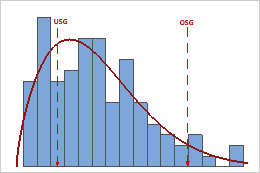
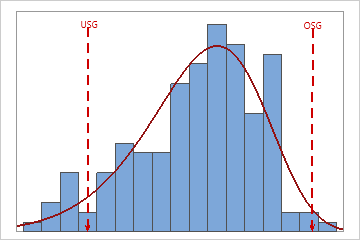
In diesen Ergebnissen ist die Prozessstreubreite größer als die Spezifikationsstreubreite, was auf eine unzureichende Prozessfähigkeit verweist. Obgleich viele Daten innerhalb der Spezifikationsgrenzen liegen, gibt es viele unzulängliche Einheiten unter der unteren Spezifikationsgrenze (USG) und über der oberen Spezifikationsgrenze (OSG).
Hinweis
Um die tatsächliche Anzahl der unzulänglichen Einheiten im Prozess zu ermitteln, verwenden Sie die Ergebnisse für PPM < USG, PPM > OSG und PPM Gesamt. Weitere Informationen finden Sie unter „Alle Statistiken und Grafiken“.
- Auswerten der Lage des Prozesses
-
Untersuchen Sie für jede Variable, ob der Prozess zwischen den Spezifikationsgrenzen oder auf den Sollwert (sofern vorhanden) zentriert ist. Durch die Spitze der Verteilungskurve wird ersichtlich, wo sich die meisten Daten befinden.
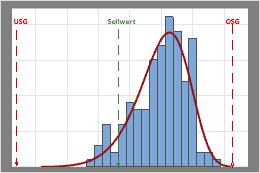
In diesen Ergebnissen liegen zwar sämtliche Stichprobenbeobachtungen innerhalb der Spezifikationsgrenzen, die Spitze der Verteilungskurve ist jedoch nicht auf den Sollwert zentriert. Die meisten Daten überschreiten den Sollwert und befinden sich dicht an der oberen Spezifikationsgrenze.