请选择您所选的方法。
精确方法的 p 值
Minitab 使用二项分布来计算数量高达 50 的样本 (n ≤ 50) 的 p 值。对于样本数量 n(省略了等于假设中位数值的任何观测值之后)和原假设下的发生概率 p = 0.5,对 p 值的计算取决于备择假设。
| 备择假设 | P 值 |
|---|---|
| H1:中位数 > 假设中位数 |  |
| H1:中位数 < 假设中位数 | 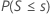 |
| H1:中位数 ≠ 假设中位数 | 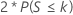 |
表示法
| 项 | 说明 |
|---|---|
| n | 在省略了等于假设中位数值的任何观测值之后,观测到的数据点个数 |
| s | 观测到的大于假设中位数的数据点个数 |
| S | 一个服从二项分布 B(n, 0.5) 的随机变量,该分布的试验次数为 n,事件的成功概率为 0.5。 |
| k | 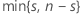 |
正态近似方法的 p 值
Minitab 使用二项分布的正态近似来计算大于 50 (n > 50) 的样本的 p 值。具体来说:
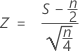 的分布与均值为 0 且标准差为 1 的正态分布 N(0,1) 近似。
的分布与均值为 0 且标准差为 1 的正态分布 N(0,1) 近似。
其中 S(大于中位数的观测值个数)具有二项分布,该分布的试验次数为 n,原假设 B(n, 0.5) 下的成功概率为 p = 0.5。
三个备择假设的正态近似 p 值使用连续校正值 0.5。
| 备择假设 | P 值 |
|---|---|
| H1:中位数 > 假设中位数 | 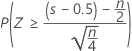 |
| H1:中位数 < 假设中位数 | 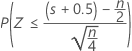 |
| H1:中位数 ≠ 假设中位数 | 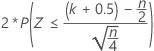 |
表示法
| 项 | 说明 |
|---|---|
| n | 在省略了等于假设中位数值的任何观测值之后,观测到的数据点个数 |
| s | 观测到的大于假设中位数的数据点个数 |
| S | 一个具有二项分布 B(n, 0.5) 的随机变量,该分布的试验次数为 n,成功概率为 p = 0.5 |
| k | 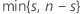 |
置信区间
单样本符号检验并不总是能够实现您指定的置信水平,这是因为符号检验统计量是离散的。因此,Minitab 会计算 3 个具有不同精确度等级的置信区间。
过程
- Minitab 对观测值进行排序,以便 X(1)< X(2)< ... < X(n),其中 X(i ) 是第 i 个最小观测值。
- 对于指定的置信区间 (γ),第一个区间是置信度 ≤ γ 的最接近的精确区间。第三个区间是置信度 ≥ γ 的最接近的精确区间。假设 d 是最大的整数,因此:
- P (B < d) < (1 – γ) / 2。
B 是参数样本数量为 n 且发生概率为 p = 0.5 的二项式分布。
- 第一个区间为 X(d + 1) 到 X(n – d),第三个区间为 X(d ) 到 X(n – d + 1)。
- Minitab 通过非线性插入 (NLI) 过程计算中间的置信区间,该过程是由 Hettmansperger 和 Sheather1 开发的。假设 γd + 1 为第一个区间的置信水平,γd 为第三个区间的置信水平。

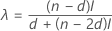
插入区间的下端点计算公式如下:
- X(d) + λ (X(d + 1)– X(d))
上端点计算公式如下:
- X(n – d + 1)– λ (X(n – d + 1)– X(n – d))
1 T.P. Hettmansperger 和 S.J. Sheather (1986)。“Confidence Intervals Based on Interpolated Order Statistics”(基于插入顺序统计量的置信区间),《Statistics and Probability Letters》(统计学和概率论通讯),4(2),第 75-79 页。