原假设和备择假设
- 原假设
- 原假设声明所有的数据值均来自同一个正态分布。
- 备择假设
- 备择假设声明最小数据值或最大数据值为异常值。
显著性水平
显著性水平(用 α 或 alpha 表示)是在原假设为真时否定原假设(类型 I 错误)的风险的最大可接受水平。默认值为 0.05。
解释
使用显著性水平可以确定是否定原假设还是无法否定原假设 (H0)。如果事件的发生概率小于显著性水平,则通常的解释是结果在统计意义上显著,并且可以否定 H0。
- 选择较高的显著性水平(如 0.10)可以更确定地检测到可能存在的任何差值。例如,一位质量工程师将新滚珠轴承的稳定性与当前轴承的稳定性进行比较。该工程师必须高度确信新滚珠轴承的稳定性,因为不稳定的滚珠轴承会导致灾难性后果。该工程师选择 0.10 的显著性水平,以更确定地检测到滚珠轴承稳定性方面任何可能的差异。
- 选择较低的显著性水平(如 0.01)可以更确定地仅检测到一个实际存在的差异。例如,一家制药公司的科学家必须十分确信公司的新药可以显著减轻症状的声明。该科学家选择 0.001 的显著性水平以更加确信任何显著的症状差异的确存在。
N
样本数量 (N) 是样本中的观测值总数。
均值
均值是数据的平均值,即所有观测值之和除以观测值的个数。
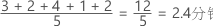
解释
使用均值来描述具有表示数据中心的单个值的样本。很多统计分析使用均值作为数据分布中心的一个标准度量。
对称
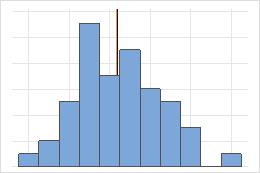
非对称
对于对称分布,均值(蓝线)和中位数(橙线)非常相似,以至于您很难区分这两条线。但是,非对称分布会向右偏斜。
标准差
标准差是离差的最常用度量,即数据从均值展开的程度。符号 σ(西格玛)通常用于表示总体的标准差,而 s 用于表示样本的标准差。对某一过程而言随机或合乎自然规律的变异通常称为噪声。对某一过程而言随机或合乎自然规律的变异通常称为噪声。
由于标准差与数据采用相同的单位,因此它通常比方差更易于解释。
解释
使用标准差可以确定数据从均值扩散的程度。 标准差值越大,数据越分散。 对于正态分布来说,好的经验法则是大约 68% 的值位于均值的一个标准差范围内,95% 的值位于两个标准差范围内,99.7% 的值位于三个标准差范围内。
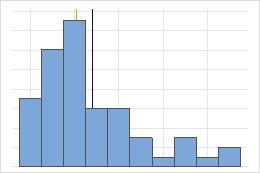
医院 1
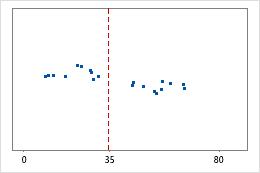
医院 2
医院出院时间
管理员对两家医院急诊部所治疗的患者的出院时间进行跟踪。尽管平均出院时间大致相同(35 分钟),但标准差显著不同。医院 1 的标准差大约为 6。平均而言,患者的出院时间大约偏离均值(虚线)6 分钟。医院 2 的标准差大约为 20。
最大值
最大值是指最大的数据值。
在这些数据中,最大值为 19。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解释
使用最大值可以标识可能的异常值或数据输入错误。评估数据散布最简单的方法之一就是比较最小值和最大值。如果最大值非常高,甚至要考虑数据的中心、散布和形状,请调查出现极端值的原因。
最小值
最小值是最小的数据值。
在这些数据中,最小值为 7。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解释
使用最小值可以标识可能的异常值或数据输入错误。评估数据散布最简单的方法之一就是比较最小值和最大值。如果最小值非常低,甚至要考虑数据的中心、散布和形状,请调查出现极端值的原因。
异常值
异常值是异常大或异常小的观测值。尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除异常、单次事件(也称为特殊原因)的数据值。然后,重新执行分析。
行
工作表中包含异常值的行。只有当存在异常值时,Minitab 才显示此值。
x[i] 和 x[N-i]
在使用某个 Dixon 比值检验时,除了最小值和最大值外,Minitab 还会在检验表中显示多个观测值。中括号中的值表示观测值相对于其他值的大小。例如,x[2] 表示第二小的观测值,[N-1] 表示第二大的观测值。
G
Grubbs 检验统计量 (G) 等于样本均值与最小数据值或最大数据值之间的差值除以标准差。Minitab 使用 Grubbs 检验统计量计算 p 值(即,当原假设为真时否定原假设的概率)。
P
P 值是一个概率,用来度量否定原假设的证据。P 值越小,否定原假设的证据越充分。
解释
使用 p 值可确定是否存在异常值。
- P 值 ≤ α:存在异常值(否定 H0)
- 如果 p 值小于或等于显著性水平,则决策为否定原假设并得出存在异常值的结论。尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除与异常的单次事件(也称为特殊原因)相关联的数据值。
- P 值 > α:您无法得出存在异常值的结论(无法否定 H0)
- 如果 p 值大于显著性水平,则决策为无法否定原假设,因为您没有足够的证据得出存在异常值的结论。您应该确保检验具有用于检测异常值的足够功效。有关更多信息,请转到提高功效。
异常值图
异常值图与单值图类似。可使用异常值图直观地确定数据中的异常值。 如果存在一个异常值,Minitab 会在图上将其显示为一个红色方块。 尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除异常、单次事件(也称为特殊原因)的数据值。然后,重新执行分析。
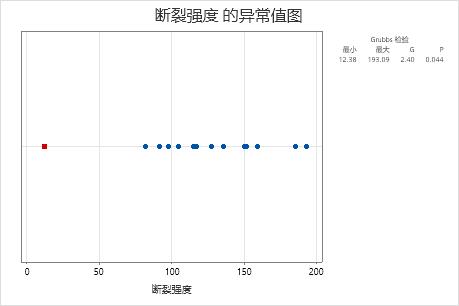
在这些结果中,最小值 12.38 是异常值。