均值
均值描述用单个值表示数据中心的样本。均值是数据的平均数,等于所有观测值之和除以观测值个数。
N
样本数量 (N) 是样本中的观测值总数。
解释
样本数量影响检验功效。
通常,样本数量越大,对于样本数据和正态分布之间差值的检验功效越大。也就是说,当实际存在差值时,样本数量越大,检测到差值的概率越大。
标准差
标准差是离差的最常用度量,即数据从均值扩散的程度。较大样本标准差表示您的数据在均值周围扩散得较为广泛。
AD
Anderson-Darling 拟合优度统计量 (AD) 度量拟合线(基于正态分布)和经验分布函数(基于数据点)之间的面积。Anderson-Darling 统计量是在分布的尾部施加更大权重的平方距离。
解释
Minitab 使用 Anderson-Darling 统计量计算 p 值。P 值是一个概率,用来度量否定原假设的证据。P 值越小,否定原假设的证据越充分。如果 Anderson-Darling 统计量的值较大,则表明数据不服从正态分布。
KS
Kolmogorov-Smirnov 检验将样本数据的 ECDF(经验累积分布函数)与数据为正态时所预期的分布进行比较。
解释
Minitab 使用 Kolmogorov-Smirnov 统计量计算 p 值。P 值是当数据为正态时获得至少与从样本计算得出的值一样极端的检验统计量(如 Kolmogorov-Smirnov 统计量)的概率。如果 Kolmogorov-Smirnov 统计量较大,则表明数据不服从正态分布。
RJ
Ryan-Joiner 统计量通过计算数据和数据的正态评分之间的相关性来度量数据对正态分布的服从程度。如果相关系数接近 1,则总体有可能是正态的。此检验与 Shapiro-Wilk 正态性检验相似。
解释
Minitab 使用 Ryan-Joiner 统计量计算 p 值。P 值是当数据为正态时获得至少与从样本计算得出的值一样极端的检验统计量(如 Ryan-Joiner 统计量)的概率。如果 Ryan-Joiner 统计量较大,则表明数据不服从正态分布。
P 值
P 值是一个概率,用来度量否定原假设的证据。P 值越小,否定原假设的证据越充分。
解释
使用 p 值可确定数据是否不服从正态分布。
- P 值 ≤ α:数据不服从正态分布(否定 H0)
- 如果 p 值小于或等于显著性水平,则决策为否定原假设并得出数据不服从正态分布的结论。
- P 值 > α:您无法得出数据不服从正态分布的结论(无法否定 H0)
- 如果 p 值大于显著性水平,则决策为无法否定原假设。您没有足够的证据得出数据不服从正态分布的结论。
概率图
概率图通过根据其估计累积概率标绘每个观测值,从样本创建估计的累积分布函数 (CDF)。
解释
使用概率图可视化您数据与正态分布的拟合程度。
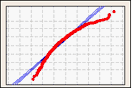
右偏斜数据
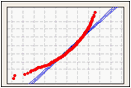
左偏斜数据
提示
在 Minitab 中,将鼠标指针移到拟合分布线上并按住将可看到百分位数和值的控制图。