关于本主题
Anderson-Darling 统计量 (A2)
A2 度量拟合线(基于所选分布)与非参数步骤函数(基于标绘点)之间的面积。统计量是在分布的尾部施加更大权重的平方距离。如果 Anderson-Darling 值较小,则表明分布与数据拟合得更好。
Anderson-Darling 正态性检验的定义如下:
H0:数据服从正态分布
H1:数据不服从正态分布
公式

表示法
| 项 | 说明 |
|---|---|
| F(Yi) |  ,即标准正态分布的累积分布函数 ,即标准正态分布的累积分布函数 |
| Yi | 排序数据 |
Anderson-Darling 正态性检验的 p 值
P 值是用来报告 Anderson-Darling 正态性检验结果的定量度量。如果 p 值较小,则表示原假设为假。
如果您知道 A 2,则可以计算 p 值。
设
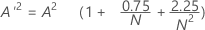
- 如果 13 > A'2 > 0.600,则 p = exp(1.2937 - 5.709 * A'2 + 0.0186(A'2)2)
- 如果 0.600 > A'2 > 0.340,则 p = exp(0.9177 - 4.279 * A'2 – 1.38(A'2)2)
- 如果 0.340 > A'2 > 0.200,则 p = 1 – exp(–8.318 + 42.796 * A'2 – 59.938(A'2)2)
- 如果 A'2 < 0.200,则 p = 1 – exp(–13.436 + 101.14 * A'2 – 223.73(A'2)2)
N 非缺失 (N)
样本中非缺失值的个数。
标准差 (StDev)
样本标准差用来度量数据的散布。它等于样本方差的平方根。
公式
 ,则样本的标准差为:
,则样本的标准差为:
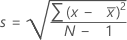
表示法
| 项 | 说明 |
|---|---|
| x i | 第 i 个观测值 |
 | 观测值的均值 |
| N | 非缺失观测值个数 |
方差
方差度量数据围绕其均值的分散程度。方差等于标准差的平方。
公式
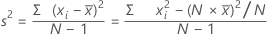
表示法
| 项 | 说明 |
|---|---|
| xi | 第 i 个观测值 |
 | 观测值的均值 |
| N | 非缺失观测值个数 |
偏度
偏度用来度量不对称度。负值表示向左偏斜,正值表示向右偏斜。零值不一定表示对称。
公式
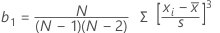
表示法
| 项 | 说明 |
|---|---|
| xi | 第 i 个观测值 |
 | 观测值的均值 |
| N | 非缺失观测值个数 |
| s | 样本的标准差 |
峰度
峰度可用来度量某个分布与正态分布的差异程度。正值通常表示,相比于正态分布,该分布的波峰更陡。负值表示,相比于正态分布,该分布的波峰更平坦。
公式

表示法
| 项 | 说明 |
|---|---|
| xi | 第 i 个观测值 |
 | 观测值的均值 |
| N | 非缺失观测值个数 |
| s | 样本的标准差 |
均值
一批数字的中心的常用度量。均值又称为平均数。均值是由所有观测值之和除以(非缺失)观测值个数得来的。
公式
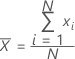
表示法
| 项 | 说明 |
|---|---|
| xi | 第 i 个观测值 |
| N | 非缺失观测值个数 |
最小值
数据集中的最小值。
最大值
数据集中的最大值。
第一个四分位数 (Q1)
25% 的样本观测值小于或等于第一个四分位数的值。因此,第一个四分位数又称为第 25 个百分位数。
公式

表示法
| 项 | 说明 |
|---|---|
| 是 | w 的整数截断值 |
| w | 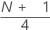 |
| z | w 的已被截断的分数分量 |
| xj | 样本数据列表中的第 j 个观测值,按从小到大的顺序排列 |
注意
当 w 是整数时,y = w、z = 0、Q1 = xy。
中位数
样本中位数位于数据的中间:至少有一半的观测值小于或等于它,至少有一半的观测值大于或等于它。
假设您有一个包含 N 个值的列。要计算中位数,首先按照从小到大的顺序对数据值进行排序。如果 N 为奇数,则样本中位数是位于中间的值。如果 N 为偶数,则样本中位数是两个中间值的平均数。
例如,当 N = 5 且您有数据 x1、x2、x3、x4 和 x5 时,中位数 = x3。
当 N = 6 且您有排序数据 x1、x2、x3、x4、x5 和 x6 时:

其中 x3 和 x4 是第三个和第四个观测值。
第三个四分位数 (Q3)
75% 的样本观测值小于或等于第三个四分位数的值。因此,第三个四分位数又称为第 75 个百分位数。
公式

表示法
| 项 | 说明 |
|---|---|
| 是 | w 的截断值 |
| w |
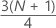 |
| z | w 的已被截断的分数分量 |
| xj | 样本数据列表中的第 j 个观测值,按从小到大的顺序排列 |
注意
当 w 是整数时,y = w、z = 0、Q3 = xy。
均值的置信区间
公式

表示法
| 项 | 说明 |
|---|---|
 | 均值 |
| s | 样本的标准差 |
| N | 非缺失数字 |
| t N, α | 自由度为 N – 1 的 t 分布在 1 – α / 2 处的逆累积概率;α = 1 – 置信水平/100 |
中位数的置信区间
Minitab 使用非线性差值来计算实际中位数的置信区间。1此方法是适用于众多对称分布(包括正态分布、Cauchy 分布和统一分布)的绝佳近似。非对称分布的示例显示足够多的结果,这些结果始终比线性差值结果更准确。
标准差的置信区间
Minitab 为总体标准差 σ 计算 (1 – α) 100% 置信区间。置信区间对于数据服从正态分布这一假设非常敏感。即使稍微偏离正态性,也会生成会产生误解的置信区间。
公式
置信区间:
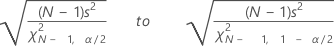
表示法
| 项 | 说明 |
|---|---|
| s | 标准差 |
| N | 非缺失数字 |
| χ2N, α | χ2 的逆累积概率,在 1 – α / 2 下自由度为 N;α = 1 – 置信水平 / 100 |