原假设和备择假设
- 原假设
- 原假设声明总体参数(如均值、标准差等)等于假设值。原假设通常是基于先前分析或专业知识的初始声明。
- 备择假设
- 备择假设声明总体参数小于、大于或不同于原假设中的假设值。备择假设是可能相信为真实或有望证明为真实的内容。
解释
在输出中,原假设和备择假设可帮助您验证是否为假设标准差或假设方差输入了正确的值。
N
样本数量 (N) 是样本中的观测值总数。
标准差
标准差是离差的最常用度量,即数据从均值展开的程度。符号 σ(西格玛)通常用于表示总体的标准差,而 s 用于表示样本的标准差。对某一过程而言随机或合乎自然规律的变异通常称为噪声。对某一过程而言随机或合乎自然规律的变异通常称为噪声。
标准差与数据采用相同的单位。
解释
样本数据的标准差是对总体标准差的估计值。
由于标准差基于样本数据而不是整个总体,因此样本标准差通常不等于总体标准差。使用置信区间可以更好地估计总体标准差。
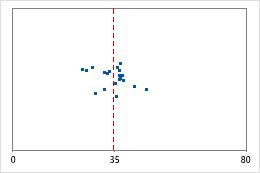
医院 1
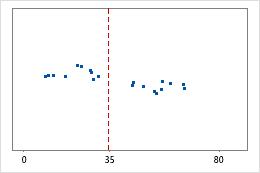
医院 2
医院出院时间
管理员对两家医院急诊部所治疗的患者的出院时间进行跟踪。尽管平均出院时间大致相同(35 分钟),但标准差显著不同。医院 1 的标准差大约为 6。平均而言,患者的出院时间大约偏离均值(虚线)6 分钟。医院 2 的标准差大约为 20。
方差
方差度量数据围绕其均值的分散程度。方差等于标准差的平方。
解释
样本数据的方差是对总体方差的估计值。
由于方差基于样本数据而不是整个总体,因此样本方差通常不等于总体方差。使用置信区间可以更好地估计总体方差。
置信区间 (CI) 和界限
置信区间提供总体标准差或总体方差的可能值范围。由于样本的随机性,来自总体的两个样本不可能生成相同的置信区间。但是如果将样本重复许多次,则所获得的特定百分比的置信区间或限值会包含未知的总体标准差或总体方差。这些包含标准差或方差的置信区间或限值的百分比是区间的置信水平。例如,95% 置信水平表明,如果从总体中随机抽取 100 个样本,则大约 95 个样本将产生包含总体标准差或总体方差的区间。
上限定义可能大于总体标准差或总体方差的值。下限定义可能小于总体标准差或总体方差的值。
置信区间有助于评估结果的实际意义。使用您的专业知识可以确定置信区间是否包括对您的情形有实际意义的值。如果区间因太宽而毫无用处,请考虑增加样本数量。有关更多信息,请转到获得更加精确的置信区间的方法。
注意
当输入一列数据时,Minitab 仅计算标准差的置信区间。
注意
Minitab 无法使用汇总数据计算 Bonett 方法。
描述性统计量
| N | 标准差 | 方差 | 使用 Bonett 的 σ 的 95% 置信区间 | 使用卡方的 σ 的 95% 置信 区间 |
|---|---|---|---|---|
| 50 | 0.871 | 0.759 | (0.704, 1.121) | (0.728, 1.085) |
在这些结果中,梁长度的总体标准差估计值为 .871,且总体方差估计值为 .759。因为数据没有通过正态性检验,所以使用 Bonett 方法。总体标准差介于 0.704 和 1.121 之间的可信度为 95%。
检验统计量
检验统计量是卡方检验的统计量,用来度量观测方差和假设方差之间的比值。
解释
可以通过将检验统计量与卡方分布的临界值进行比较来确定是否要否定原假设。但是,使用检验的 p 值做出相同的决定通常更实际且更方便。对于所有的大小检验来说,p 值的含义都相同,但相同的卡方统计量可能指示相反的结论,具体取决于样本数量。
- 对于双侧检验,临界值为
 和
和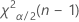 。如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于两者之间,则无法否定原假设。
。如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于两者之间,则无法否定原假设。 - 对于具有“小于”备择假设的单侧检验,临界值为
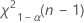 。如果检验统计量小于该值,则否定原假设。否则,无法否定原假设。
。如果检验统计量小于该值,则否定原假设。否则,无法否定原假设。 - 对于“大于”单侧检验,临界值为
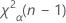 。如果检验统计量大于该值,则否定原假设。否则,无法否定原假设。
。如果检验统计量大于该值,则否定原假设。否则,无法否定原假设。
检验统计量可用于计算 p 值。由于 Bonnet 方法没有检验统计量,因此 Minitab 使用由置信限值定义的否定区域来计算 p 值。
自由度
自由度 (DF) 指示数据提供的信息量,您可以使用这些信息来估计未知参数的值并计算这些估计值的变异性。对于单方差检验,自由度由样本中的观测值个数来确定。
解释
Minitab 使用自由度来确定检验统计量。自由度由样本数量确定。增加样本数量可提供有关总体的更多信息,从而增加自由度。
P 值
P 值是一个概率,用来度量否定原假设的证据。P 值越小,否定原假设的证据越充分。
解释
使用 p 值可确定总体方差或标准差在统计意义上是否不同于假设方差或标准差。
- P 值 ≤ α:方差或标准差的差值在统计意义上显著(否定 0)
- 如果 p 值小于或等于显著性水平,则决策为否定原假设。您可以得出总体方差或标准差与假设方差或标准差的差值在统计意义上显著的结论。请使用您的专业知识确定差值在实际意义上是否显著。有关更多信息,请转到统计显著性和实际显著性。
- P 值 > α:方差或标准差的差值在统计意义上不显著(无法否定 H0)
- 如果 p 值大于显著性水平,则决策为无法否定原假设。您没有足够的证据得出总体方差或标准差与假设方差或标准差的差值在统计意义上显著的结论。您应该确保检验具有足够的功效来检测到在实际意义上显著的差值。有关更多信息,请转到单方差的功效和样本数量。
注意
当您具有汇总数据时,Minitab 无法为 Bonett 方法计算 P 值。