查找定义和解释指南,了解随增强型 Dickey-Fuller 检验提供的每个统计量和图形。
方法表
方法表显示分析的设置和选定的滞后顺序。
在这些结果中,分析评估的最大滞后顺序为 9。分析使用滞后顺序最高为 4 的模型来计算测试结果。
方法
| 回归模型中项的最大滞后阶数 | 9 |
|---|---|
| 滞后阶数的选择标准 | 最小 AIC |
| 其他项 | 常量 |
| 选定的滞后阶数 | 4 |
| 已使用的行数 | 36 |
增强型迪基-富勒测试台
增强型 Dickey-Fuller 检验表提供了假设、检验统计量、p 值以及关于是否考虑微分以使序列平稳的建议。
检验统计量提供了一种评估原假设的方法。小于或等于临界值的检验统计量可提供反对原假设的证据。
P 值是一个概率,用来测量否定原假设的证据。概率越低,否定原假设的证据越充分。
要确定是否要对数据进行差异化,请将检验统计量与临界值或 p 值与显著性水平进行比较。由于 p 值包含更多近似值,因此当显著性水平为 0.01、0.05 或 0.10 时,分析中的建议使用临界值来评估原假设。通常,临界值和 p 值的结论是相同的。原假设是数据是非平稳的,这意味着差分是尝试使数据平稳的合理步骤。
- P 值≤显著性水平
- ≤临界值的测试统计量
- 如果 p 值小于或等于显著性水平,或者检验统计量小于或等于临界值,则决定否定原假设。由于数据提供了数据静止的证据,因此分析的建议是继续进行,不进行差异。
- P 值>显著性水平
- >临界值的测试统计量
- 如果 p 值大于显著性水平,或者检验统计量大于临界值,则决定不否定原假设。由于数据不能提供数据是平稳的证据,因此分析的建议是确定差异是否使数据的平均值静止。
在这些结果中,检验统计量 2.29045 大于临界值约为 -2.96053。由于结果无法否定数据为非平稳的原假设,因此检验的建议是考虑差异以使数据平稳。
增强的 Dickey-Fuller 检验
| 原假设: | 数据不稳定 |
|---|---|
| 备择假设: | 数据稳定 |
| 检验统计量 | P 值 | 建议 |
|---|---|---|
| 2.29045 | 0.999 | 检验统计量 > -2.96053 的临界值。 |
| 显著性水平 = 0.05 | ||
| 未能否定原假设。 | ||
| 考虑进行差值处理以使数据保持稳定。 |
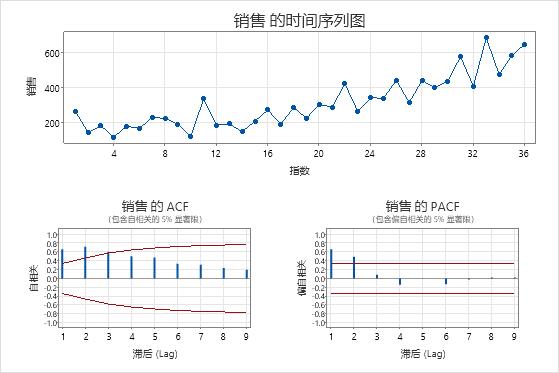
原版系列的情节
- 时间序列图
- 使用原始序列的时间序列图可以检查原始数据的特征。趋势是指示非平稳均值的形态的示例。使用差分法尝试使平均值静止。
- ACF 图
- 使用原始数据中的自相关函数 (ACF) 查找指示数据均值不平稳的模式。一种常见的模式是滞后的大峰值,这些峰值会非常缓慢地消失。
- PACF 图
- 通常,您可以使用固定数据的偏自相关函数 (PACF) 来查找指示 ARIMA 模型中存在自回归项的模式。如果原始数据不是平稳的,请使用差分序列的 PACF 图查找 ARIMA 模型的候选项。
在这些结果中,数据显示时间序列图呈递增趋势。ACF 图上的第一个滞后显示一个超过 5% 显著性极限的大峰值,然后非常缓慢地减小。这些模式表明数据的均值不是平稳的。
由于销售额与解释确定性趋势的预测变量没有关系,并且分析师希望使用 ARIMA 模型来预测销售额,因此对数据进行差异化是尝试使序列的平均值保持平稳的合理方法。
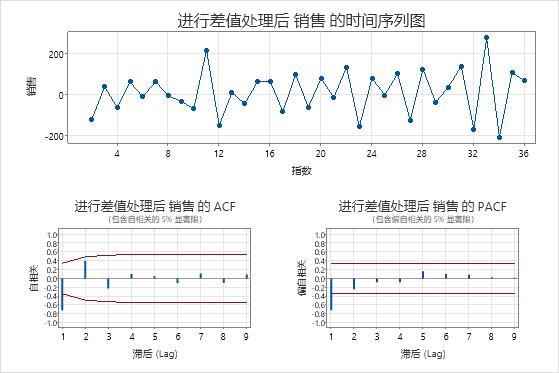
差分序列的绘图
- 差分后的时间序列图
- 使用差分数据的时间序列图来验证差分是否使数据的均值平稳。时间序列图显示连续观测值之间的差异。具有平稳均值的数据沿时间序列图上的水平路径运行。
- ACF 图和 PACF 图在差异化后
- 使用差分数据的 ACF 来验证差分是否使数据的均值平稳。峰值快速下降的图是静止数据的特征。
在这些结果中,时间序列图显示差分数据的均值和方差近似恒定。数据似乎是静止的。
在差分数据的 ACF 图中,唯一与 0 显著不同的峰值滞后为 1。此模式还表明数据是静止的。