回归方程
使用回归方程来描述模型中响应和项之间的关系。回归方程是回归线的代数表示。线性模型的回归方程采取如下形式:Y= b0 + b1x1。在回归方程中,Y 是响应变量,b0 是常量或截距,b1 是线性项的估计系数(也称为直线斜率),x1 是项值。
具有多个项的回归方程采取以下形式:
y = b0 + b1X1 + b2X2 + ... + bkXk
- y 是响应变量
- b0 是常量
- b1, b2, ..., bk 是系数
- X1, X2, ..., Xk 是项值
如果模型同时包含连续变量和类别变量,则回归方程表可能会显示类别变量的每个水平组合的方程。要使用这些方程进行预测,您必须基于类别变量值选择正确的方程,然后输入连续变量的值。
变量设置
模型使用变量设置计算预测值。如果变量设置异常(相对于 Minitab 用于估计模型的数据的变量设置),Minitab 会在预测值下方显示一条警告。
拟合值
拟合值又称拟合或 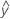 。拟合值是对于给定预测变量值的均值响应的点估计。预测变量值又称 x 值。
。拟合值是对于给定预测变量值的均值响应的点估计。预测变量值又称 x 值。
解释
拟合值是通过将数据集内每个观测值的特定 x 值输入到模型方程中来计算的。
例如,如果方程为 y = 5 + 10x,则 x 值 2 的拟合值为 25 (25 = 5 + 10(2))。
Minitab 会标注使用异常预测值(相对于数据值)的预测。只有使用较老的样本进行进一步检验才能确认保质期的估计值是精确的。
拟合值标准误
拟合值标准误(拟合值 SE)用于估计指定变量设置的估计平均响应中的变异。将使用拟合值标准误来计算平均响应的置信区间。标准误始终为非负值。分析计算菜单中的 统计 模型以及 中的 二值 Logistic 回归 预测分析模块模型 线性回归 的标准误差。
解释
使用拟合值标准误可度量平均响应估计值的精确度。标准误越小,预测平均响应越精确。例如,一位分析人员设计了一个用于预测交货时间的模型。对于一组变量设置,该模型预测平均交货时间为 3.80 天。这些设置的拟合值标准误为 .0.08 天。对于第二组变量设置,模型生成了相同的平均交货时间,但是拟合值标准误为 .0.02 天。该分析人员可以确信:第二组变量设置的平均交货时间更接近 3.80 天。
您可以将拟合值标准误与拟合值结合使用,从而创建平均响应的置信区间。例如,根据自由度的数量,95% 置信区间将大约从预测均值上方和下方展开两个标准误。对于交货时间,当标准误为 0.08 时,预测均值 3.80 天的 95% 置信区间为 (3.64, 3.96) 天。总体均值在此范围内的置信度为 95%。当标准误为 .0.02 时,95% 置信区间为 (3.76, 3.84) 天。第二组变量设置的置信区间更窄,因为其标准误较小。
拟合值的置信区间(95% 置信区间)
这些置信区间 (CI) 是可能包含总体的平均响应的值范围,该总体在模型中具有预测变量或因子的观测值。
由于样本的随机性,来自总体的两个样本不可能生成相同的置信区间。但是如果将样本重复许多次,则所获得的特定百分比的置信区间会包含未知的总体参数。这些包含参数的置信区间的百分比是区间的置信水平。
置信区间由以下两部分组成:
解释
使用置信区间可以为变量的实测值评估拟合值的估计值。
例如,当置信水平为 95% 时,模型中包含预测变量或因子特定值的总体均值的置信区间的置信度为 95%。置信区间有助于评估结果的实际意义。利用您的专业知识可以确定置信区间是否包含对您的情形有实际意义的值。较宽的置信区间表明,有关未来值的均值的置信度可能较低。如果区间因为太宽而无效,请考虑增加样本数量。
95% PI
预测区间是可能包含变量设置的选定组合的一个未来响应变量的范围。预测区间总是要比对应的置信区间大。
解释
例如,一位质量工程师确定了一种新药物的保质期为 54.79 个月。此分析的保质期定义为工程师认为最差批次的浓度是预期浓度 90% 的可信度不再是 95% 时。这位工程师想要预测最差批次在 54.79 个月时的平均浓度。
在这些结果中,均值响应的预测值约为 91.36%。但是,这位工程师还想要估计批次 2 中的单颗药的值范围。预测区间表明批次 2 中的单颗药在第 54.79 个月时的预测浓度大约介于 89.3217% 到 93.4001% 之间的可信度为 95%。
设置
| 变量 | 设置 |
|---|---|
| 月 | 54.79 |
| 批次 | 2 |
预测
| 拟合值 | 拟合值标准误 | 95% 置信区间 | 95% 预测区间 | |
|---|---|---|---|---|
| 91.3609 | 0.801867 | (89.7233, 92.9986) | (89.3217, 93.4001) | XX |