请选择您所选的方法或公式。
拟合值
预测的 Y 或  是使用估计回归方程的给定预测变量值的平均响应值。
是使用估计回归方程的给定预测变量值的平均响应值。
交叉验证的拟合值
交叉验证的拟合值表示模型预测数据的准确程度。这些值与表示模型对数据的拟合优度的普通拟合值相似。为获得观测值的交叉验证的拟合值,必须将该观测值从用于计算模型的数据中删除,然后使用与该观测值无关的系数向量计算拟合值。交叉验证的拟合值的公式如下所示:
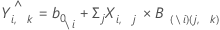
表示法
| 项 | 说明 |
|---|---|
| \i | 表示计算模型时忽略了观测值 i |
| b0\i | 不包括观测值 i 的模型的截距 |
| X | 预测变量值 |
| B(\i)(j, k) | 不包括观测值 i 的模型的系数 |
残差
残差是观测值与相应拟合值之间的差分。该模型不解释这部分观测值。观测值的残差为:
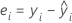
表示法
| 项 | 说明 |
|---|---|
| yi | 观测的第 i 个响应值 |
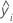 | 第 i 个响应拟合值 |
交叉验证的残差
交叉验证的残差可度量模型的预测能力,并用于计算 PRESS 统计量。PLS 和最小二乘回归中的交叉验证的残差在概念上相似,但计算方法不同。
公式
在 PLS 中,交叉验证的残差是实际响应变量与交叉验证拟合值之间的差。
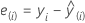
交叉验证的残差值会根据交叉验证期间每次重新计算模型时忽略的观测值数的不同而有所不同。
在最小二乘回归中,交叉验证的残差可直接根据普通残差进行计算。
表示法
| 项 | 说明 |
|---|---|
| (i) | 计算模型时忽略的观测值 |
| yi | 响应值 |
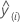 | 交叉验证的拟合值 |
标准化残差
标准化残差也称为“内部 t 化残差”。
公式

表示法
| 项 | 说明 |
|---|---|
| ei | 第 i 个残差 |
| hi | X(X'X)–1X' 的第 i 个对角线元素 |
| s2 | 均方误 |
| X | 设计矩阵 |
| X' | 转置设计矩阵 |
拟合值的标准误(拟合值 SE)
具有一个预测变量的回归模型中拟合值的标准误为:

具有多个预测变量的回归模型中拟合值的标准误为:

对于加权回归,在公式中包括权重矩阵:

当数据具有测试数据集或 K 折交叉验证时,公式相同。的值 s2 是从培训数据。设计矩阵和重量矩阵也来自训练数据。
表示法
| 项 | 说明 |
|---|---|
| s2 | mean square error |
| n | number of observations |
| x0 | new value of the predictor |
 | mean of the predictor |
| xi | i(序号) predictor value |
| x0 | vector of values that produce the fitted values, one for each column in the design matrix, beginning with a 1 for the constant term |
| x0 | transpose of the new vector of predictor values |
| X | design matrix |
| W | weight matrix |
置信区间
置信区间是一组给定预测变量值的估计均值响应将落入的极差。该区间由下限和上限共同定义,它们可由拟合值的置信水平和标准误计算得出。
公式
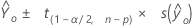
表示法
| 项 | 说明 |
|---|---|
| α | Alpha 值 |
| n | 观测值数 |
| p | 预测变量数 |
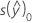 |  |
| s2 | 均方误 |
| S2(b) | 系数的方差-协方差矩阵 |
预测区间
预测区间是新观测值的拟合响应预计将落入的范围。
公式
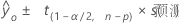
Notation
| 项 | 说明 |
|---|---|
| s(Pred) |  |
 | 一组给定预测变量值的拟合响应值 |
| α | 显著性水平 |
| n | 观测值个数 |
| p | 模型参数个数 |
| s 2 | 均方误 |
| X | 预测变量矩阵 |
| X0 | 给定预测变量值的矢量,具有 1 列和 p 行 |
| X'0 | 具有 1 行和 p 列的预测变量值的新矢 量的转 置 |