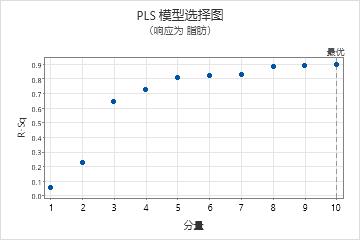
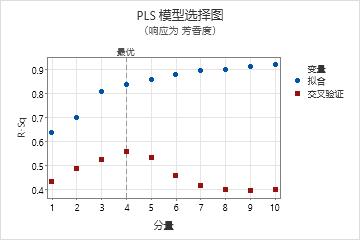
模型选择图
模型选择图作为拟合或交叉验证的分量数的函数,是 R2 和预测的 R2 值的散点图。它是模型选择和验证表的图形化显示。如果不使用交叉验证,则图上不会显示预测的 R2 值。Minitab 为每个响应提供一个模型选择图。
解释
使用此图比较不同模型的建模和预测功效,以确定在模型中要保留的相应分量数。图上的垂直线表示 Minitab 为 PLS 模型所选择的分量数。
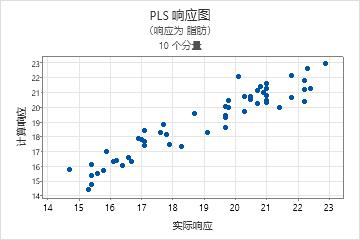
响应图
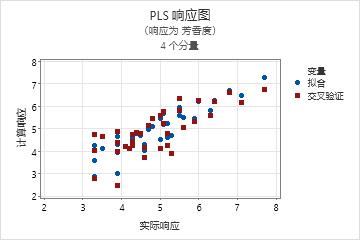
响应图是拟合值与实际响应的散点图。执行交叉验证时,图上还会包括拟合值与交叉验证的拟合值。Minitab 为每个响应提供一个响应图。
解释
- 这些点中的非线性模式,表明模型不能很好地拟合或预测数据。
- 执行交叉验证时,如果拟合值与交叉验证的值之间存在较大差异,则表明存在杠杆率点。
预测能力优秀的模型的斜率通常为 1,并且该模型与 Y 轴在 0 处相交。
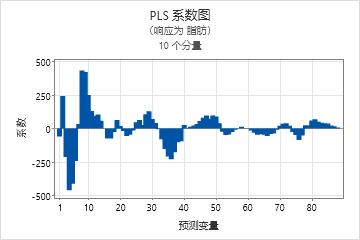
系数图
此系数图是一种投影散点图,它显示每个预测变量的非标准化系数。Minitab 为每个响应提供一个系数图。
解释
将系数图与回归系数的输出结合使用,以比较每个预测变量的系数的符号和量值。使用此图更容易快速地确定模型中可能重要或不重要的预测变量。
由于此图显示非标准化系数,因此只有预测变量规模相同(例如,光谱数据)时才能在预测变量之间关系的量值以及响应之间进行比较。否则,使用标准化系数图或使用载荷图来比较用于计算分量的预测变量的权重。
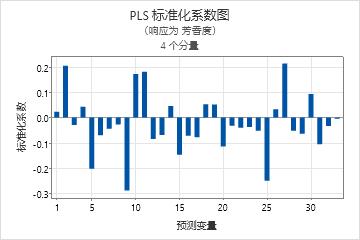
标准系数图
此系数图是一种投影散点图,它显示每个预测变量的标准化系数。Minitab 为每个响应提供一个标准化系数图。
解释
将此图与回归系数的输出结合使用,以比较每个预测变量的系数的符号和量值。使用此图更容易快速地确定模型中可能重要或不重要的预测变量。
由于此图显示非标准化系数,因此即使预测变量规模不同,也可以在预测变量之间关系的量值以及响应之间进行比较。
如果您的预测变量的规模都相同,则标准化和非标准化图中系数的模式看上去相似。但是这些图有可能看上去不同,原因是预测变量高度相关,从而导致系数不稳定,以及样本标准差和总体标准差之间存在差异。
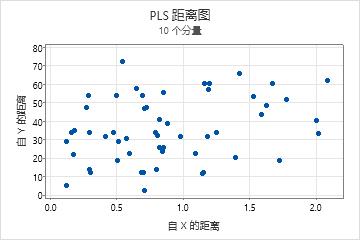
距离图
距离图是每个观测值距 x 模型和 y 模型的距离的散点图。距 y 模型的距离度量 y 空间中观测值的拟合优度。距 x 模型度量 x 空间中观测值的拟合优度。
解释
检查此图时,请查找 x 轴或 y 轴上距离大于其他点的点。距 y 模型距离较远的观测值可能是异常值,距 x 模型距离较远的观测值可能是杠杆率点。
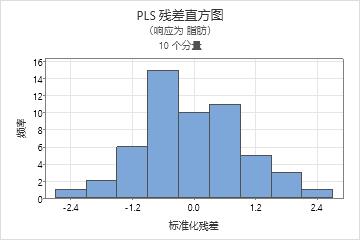
残差的直方图
标准化残差的直方图显示所有观测值的标准化残差分布。
解释
| 形式 | 模式的含义 |
|---|---|
| 朝着一个方向的长尾 | 偏度 |
| 远离其他条形的条形 | 异常值 |
由于直方图的外观取决于用来对数据分组的区间数,因此在评估残差的正态性时不要使用直方图,而是改用正态概率图。在具有大约 20 个或更多个数据点时,直方图效果最明显。如果样本数量较少,则直方图上的每个条形无法包含足够的数据点,因而无法可靠地显示偏度或异常值。
残差的正态概率图
残差的正态概率图会在分布遵循正态分布时显示标准化残差与预期值。
解释
使用残差正态概率图可验证残差呈正态分布的假设。残差的正态概率图应该大致为一条直线。
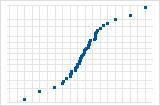
S 曲线表示长尾分布。
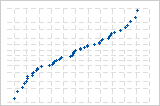
反向 S 曲线表示短尾分布。
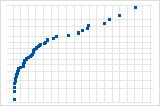
向下的曲线表示右偏斜分布。
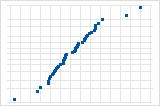
远离线的几个点表示分布中有异常值。
如果发现非正态模式,请使用其他残差图检查该模型是否存在其他问题,例如,缺失项或时间顺序效应。如果残差不遵循正态分布,则置信区间和 P 值可能不准确。
残差与拟合值
残差与拟合值图在 Y 轴上标绘标准化残差,在 X 轴上标绘拟合值。
解释
使用残差与拟合值图可验证残差随机分布和具有常量方差的假设。理想情况下,点应当在 0 的两端随机分布,点中无可辨识的模式。
| 模式 | 模式的含义 |
|---|---|
| 残差相对拟合值呈扇形或不均匀分散 | 异方差 |
| 曲线 | 缺少高阶项 |
| 远离 0 的点 | 异常值 |
| 在 X 方向远离其他点的点 | 有影响的点 |

含异常值的图
其中一个点比所有其他点大得多。因此,该点是异常值。如果异常值过多,则模型可能不可接受。您应该尝试找出导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除与异常的单次事件(也称为特殊原因)相关联的数据值。然后,重新执行分析。
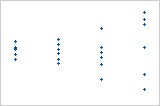
含异方差的图
残差的方差随拟合值增加。请注意,随着拟合值增大,残差之间的散布变宽。此模式表示残差的方差不相等(非恒定)。
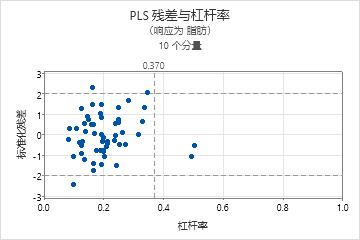
残差与杠杆率图
残差与杠杆率图是每个观测值的标准化残差与杠杆率的散点图。
解释
- 异常值:标准化残差大于 +/- 2 的观测值,它在图中位于水平参考线之外。
- 杠杆率点:杠杆率值大于 2m/n(其中 m = 分量数,且 n = 观测值数)的观测值,该观测值被视为极值。它们的 x 分值远离 0 并且位于垂直参考线(位于 x 轴上 2m / n 值处)右侧。如果 2m / n 大于 1,则图上不会显示参考线,因为杠杆率值始终在 0 和 1 之间。
残差与顺序
残差与顺序图按照数据的收集顺序显示标准化残差。
解释
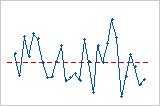
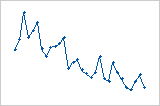
趋势
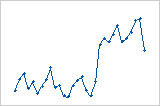
偏移
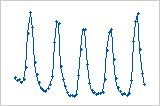
周期
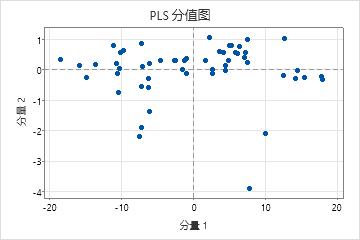
分值图
分值图是模型中第一个和第二个分量的 X 分值的散点图。
解释
如果前两个分量解释预测变量的大多数方差,则此图中点的配置近似反映数据的原始多维配置。要检查预测变量中由模型解释的方差数量,请检查模型选择和验证表中的 x 方差值。如果 x 方差值很高,那么模型解释预测变量中的显著性方差。
- 杠杆率点:图中远离大部分点的点可能是杠杆率点,且可能对结果具有显著效应。
- 聚类:聚集在一起的点可能表示数据中有两种或更多种不同的分布,可以通过不同的模型来更好地描述。
注意
如果模型包含 2 个以上的分量,您可能想要使用散点图来标绘其他分量的 X 分值。为此,请存储 X 分值矩阵,然后使用将该矩阵复制到列。如果模型只有一个分量,那么输出中不会显示此图。
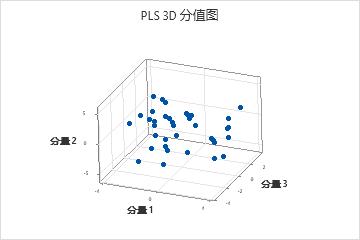
3D 分值图
3D 分值图是模型中的第一个、第二个和第三个分量的 X 分值的三维散点图。如果前三个分量解释预测变量中的大多数方差,则此图中点的配置便可以近似反映数据的原始多维配置。要检查由模型解释的方差的数量,请检查模型选择和验证表中的 X 方差值。如果 X 方差值很高,那么模型解释预测变量中的显著性方差。
解释
- 杠杆率点:图中远离大部分点的点可能是杠杆率点,且可能对结果具有显著效应。
- 聚类:聚集在一起的点可能表示数据中有两种或更多种不同的分布,可以通过不同的模型来更好地描述。
您还可以使用 3D 图形工具,那样您可以旋转图以便从不同的角度进行查看。这样您可以得到一个更完整的数据图片,并可以更准确地标识杠杆率点和点的聚类。
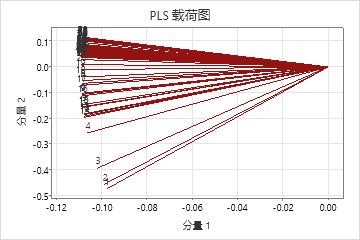
载荷图
载荷图是投影到模型中第一个和第二个分量上的预测变量的散点图。它显示对第一个分量的 X 载荷标绘的第二个分量的 X 载荷。图中每个点代表一个预测变量,都连接到了 (0,0)。
解释
载荷图说明了预测变量对于前两个分量的重要性,当预测变量处于不同的尺度上时此图尤其有帮助。如果该分量解释了模型选择和验证表中显示的绝大多数 X 方差,那么载荷图可以表明 X 空间中预测变量的重要性。当考虑预测变量在整个模型中的重要性时,您也必须考虑响应中由该分量解释的方差数量。要检查此值,请检查模型选择和验证表中的 R2 和预测的 R2 值。
- 线之间的角度,表示预测变量之间的相关性。较小的角度表示预测变量高度相关。
- 线比较长的预测变量,在第一个或第二个分量中具有较大的载荷,且在模型中比较重要。
注意
如果模型包含 2 个以上的分量,您可能想要使用散点图来标绘其他分量的 X 载荷。为此,请存储 X 载荷矩阵,然后使用将该矩阵复制到列。
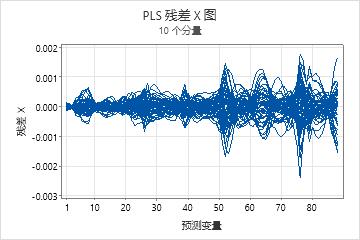
残差 X 图
残差 X 图是 X 方差与预测变量的线条图。每条线代表一个观测值,且具有和预测变量一样多的点。
解释
使用 X 残差矩阵图可以标识模型无法很好地描述的观测值或预测变量。预测变量处于相同尺度上时,此图最有帮助。
- 当这些线在 X 轴上的相同点处断开时,模型无法很好地描述该点处的预测变量。
- 当图中某条线偏离其他线时,模型无法很好地描述由该线表示的观测值。
使用 X 残差矩阵图来检查残差中的一般模式并标识出存在问题的区域。然后,检查输出中显示的 X 残差以确定模型无法很好地描述的观测值和预测变量。
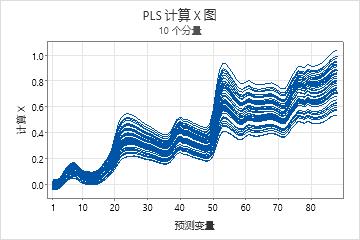
计算 X 图
计算 X 图是 X 计算值与预测变量的线图。每条线代表一个观测值,且具有和预测变量一样多的点。
解释
使用此图来识别出模型无法很好地描述的观测值或预测变量。预测变量处于相同尺度上时,此图最有帮助。
计算 X 图是 X 残差图的补充。两个图结合可以形成原始预测变量值的图。具有比原始的 X 值小或大很多的 X 计算值的预测变量无法由模型很好地描述。