链接函数
Minitab 提供三种链接函数:Logit(默认)、Normit 和 Gompit。链接函数可用于拟合各种顺序响应模型。Logit 是标准累积 Logistic 分布函数的反函数。Normit 函数又称 Probit,是标准累积正态分布函数的反函数。Gompit 函数又称互补对数 - 对数,是 Gompertz 分布函数的反函数。
公式
g(χk) = θk +x'β, k = 1, ..., K-1
链接函数是分布函数的反函数。链接函数及其对应的分布汇总如下:
| 名称 | 链接函数 | 分布 |
|---|---|---|
| Logit | g(χ) = loge(χ/ (1 – χ)) | Logistic |
| Normit (Probit) |
g(χ) = Φ–1(χ) |
正态 |
| Gompit(互补对数 - 对数) | g(χ) =loge (–loge(1 – χ)) | Gompertz |
表示法
| 项 | 说明 |
|---|---|
| K | 响应的可区分类别的数量 |
| χk | 达到并包括类别 k 的累积概率,(π1+ ...+ πk) |
| g(χk) | 预测变量的向量 |
| θk | 与第 k 个可区分响应类别相关的常量 |
| x | 预测变量的向量 |
| β | 与预测变量相关的系数的向量 |
因子/协变量模式
描述数据集中的一组因子/协变量值。Minitab 会为每种因子/协变量模式计算事件概率、残差及其他诊断度量标准。
例如,如果数据集包含性别和民族(因子)以及年龄(协变量),则这些预测变量的组合可能包含与对象一样多的不同的协变量模式。如果数据集仅包含民族和性别两个因子,且每个因子有两个编码水平,则仅存在四种可能的因子/协变量模式。如果您将输入的数据作为频率、成功、试验或失效数据,则每行包含一个因子/协变量模式。
事件概率
事件概率为 k = 1、2、...、K 的 πk。
公式
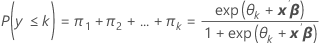
表示法
| 项 | 说明 |
|---|---|
| k | 等于 1、...、K – 1 |
| θk | 常量 |
| β | Logit 方程中系数的向量 |
累积事件概率
响应落在每个可能的类别 k 或其下类别的概率。第 k 个累积概率为:
公式
P(y k) = p1 + ... + pk,k = 1, ... , K
k) = p1 + ... + pk,k = 1, ... , K
累积概率反映响应的顺序。对于具有 k 个响应类别的模型:
P(y 1) <P(y
1) <P(y 2)
2)  …
… P(y
P(y K) = 1
K) = 1

系数
Minitab 会使用比例优势模型,在该模型中,预测变量的向量 x 有一个参数 β,该参数描述 x 对类别 k 或其下类别中响应的对数优势的效应。Minitab 假设所有 K – 1 类别的 x 效应相同,因此,只会为每个预测变量计算 1 个系数。预测变量的系数表示当预测变量处于相较于参考水平的某个水平时,任何固定 k 的响应的 Logit 中的估计变化。
Minitab 会为每个 K – 1 类别估计一个常量。在累积概率模型中,使用参数估计值为每个类别计算估计概率:
公式
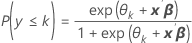
使用与最大似然估计等效的迭代重加权最小二乘方法计算估计系数。1,2
参考资料
- D.W. Hosmer 和 S. Lemeshow (2000)。Applied Logistic Regression(应用的 Logistic 回归)。第 2 版。John Wiley & Sons, Inc.
- P. McCullagh 和 J.A. Nelder (1992)。Generalized Linear Model(广义线性模型)。Chapman & Hall。
系数的标准误
渐进标准误,表示估计系数的精确度。标准误越小,估计值越精确。
有关详细信息,请参见 [1] 和 [2]。
- A. Agresti (1990)。Categorical Data Analysis(类别数据分析)。John Wiley & Sons, Inc.
- P. McCullagh 和 J.A. Nelder (1992)。Generalized Linear Model(广义线性模型)。Chapman & Hall。
Z
Z 用于确定预测变量是否与响应变量显著相关。Z 的绝对值越大,表示关系越显著。P 值表示 Z 落在正态分布上的位置。
公式
Z = βi/标准误
常量的公式为:
Z = θk /标准误
对于数量较少的样本,似然比率检验可能是更可靠的显著性检验。
P 值
用于假设检验,可帮助您确定是要否定原假设还是无法否定原假设。如果原假设成立,P 值就是获得至少与实际计算值一样极端的检验统计量的概率。P 值常用的截止值为 0.05。例如,如果检验统计量的计算的 P 值小于 0.05,您可以否定原假设。
优势比
Minitab 会将比例优势模型用于顺序 Logistic 回归。只会为每个预测变量计算一个参数和一个优势比。优势比使用累积概率及其补数。对于有 2 个水平 x1 和 x2 的预测变量,累积优势比为:
公式
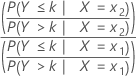
置信区间
公式
βi 的大样本置信区间为:
β i + Zα /2*(标准误)
要获得优势比的置信区间,请对置信区间的上下限取指数。该区间为预测变量的每个单位变化提供几率可能会落入的范围。
表示法
| 项 | 说明 |
|---|---|
| α | 显著性水平 |
对数似然
从单独的概率密度函数中导出的表达式经最大化得出最优值 β。由于对数似然取决于样本数量,因此它们不能单独作为拟合的度量标准使用,但可以用来比较两个模型。
对于顺序 Logistic 回归,存在 n 个独立的多项向量,每个向量有 k 个类别。这些观测值可表示为 y1、...、yn,其中,yi = (yi1、...、yik) 和 Σjyij = mi 是每个 i 的固定值。第 i 个观测值 yi 对于对数似然的贡献为:
公式
L(πi ; yi) = Σkyik log πik
总对数似然为 n 个观测值中每个观测值的贡献的和:
L(π ; y) = Σi L(πi; yi)
表示法
| 项 | 说明 |
|---|---|
| πik | 第 k 个类别的第 i 个观测值的概率 |
方差-协方差矩阵
维度为 p + K – 1 的正方形矩阵。每个系数的方差在对角线单元中,每对系数的协方差在相应的非对角线单元中。方差是系数标准误的平方。
方差-协方差矩阵是渐近矩阵,来自信息矩阵的逆矩阵的最后一次迭代。
表示法
| 项 | 说明 |
|---|---|
| p | 预测变量数 |
| K | 响应中类别的数量 |
Pearson
基于 Pearson 残差的汇总统计量,可表示模型对数据的拟合优度。当协变量的可区分值的数量近似于观测值的数量时,Pearson 不适用,但当同一个协变量水平上存在重复的观测值时,Pearson 适用。较大的 χ2 检验统计量和较小的 P 值表示模型无法很好地与数据拟合。
计算公式为:
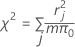
其中,r = Pearson 残差,m = 第 j 个因子/协变量模式中试验的数量,π0 = 比率的假设值。
偏差
基于残差偏差的汇总统计量,可表示模型对数据的拟合优度。当协变量的可区分值的数量近似于观测值的数量时,偏差不适用,但在同一协变量水平上存在重复的观测值时,偏差适用。较大的 D 值和较小的 P 值表示模型无法很好得与数据拟合。检验的自由度为 (k - 1)*J − (p),其中,k 为响应中类别的数量,J 为可区分因子/协变量模式的数量,p 为系数的数量。
计算公式为:
D =2 Σ yik log p ik− 2 Σ yik log π ik
其中,πik = 第 k 个类别的第 i 个观测值的概率。
相关性度量
一致和不一致对表示模型对数据的预测优度。一致对越多,模型的预测能力越好。
一致对、不一致对及结对表通过形成具有不同响应值的所有可能的观测值计算得出。假设响应值为 1、2 和 3。Minitab 会将每个观测值与响应值 1 配对,将每个观测值与响应值 2 和 3 配对,然后将每个观测值与响应值 2 配对,将每个观测值与响应值 1 和 3 配对。总对数等于具有响应值 1 的观测值数乘以具有响应值 2 的观测值数,加上具有响应值 1 的观测值数乘以具有响应值 3 的观测值数,再加上具有响应值 2 的观测值数乘以具有响应值 3 的观测值数。
要确定对是一致对还是不一致对,Minitab 计算每个观测值的累积预测概率并比较每对观测值的累积预测概率值。
- 一致
- 对于包含最小响应值(在上例中,该值为 1)的对,如果具有最小响应值的观测值的达到最小响应值的累积概率比具有较高响应值的观测值的大,那么此对为一致对。对于包含最高响应值的对(在上例中,具有响应值 2 和 3 的对),如果具有响应值 2 的观测值的达到 2 的累积概率比具有响应值 3 的观测值的大,那么此对为一致对。
- 不一致
- 对于包含最小响应值(在上例中,该值为 1)的对,如果具有较高响应值的观测值的达到最小响应值的累积概率比具有较小响应值的观测值的大,那么此对为不一致对。对于包含最高响应值的对(在上例中,具有响应值 2 和 3 的对),如果具有响应值 3 的观测值的达到 2 的累积概率比具有响应值 2 的观测值的大,那么此对为不一致对。
- 结
- 如果观测值的累积概率相等,那么对为结对。
公式
在一致、不一致和结对表中,Minitab 将计算以下汇总度量标准:



表示法
| 项 | 说明 |
|---|---|
| nc | 一致对的数量 |
| nd | 不一致对的数量 |
| nt | 结对的数量 |
| N | 观测值总数 |