指数族和链接函数
从经典线性模型扩展到广义线性模型包含两部分:指数族分布和链接函数。
指数族
第一部分会将线性模型扩展到作为大型分布族(称为指数族)成员的响应变量。分布的指数族成员具有已观测响应变量的概率分布函数,这些函数的一般形式为:
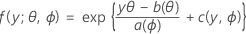
其中,a(∙)、b(∙) 和 c(∙) 取决于响应变量的分布。参数 θ 是位置参数,通常称为典范参数,ϕ 称为离差参数。通常情况下,函数 a(ϕ) 的形式为 a(ϕ)= ϕ/ ω,其中,ω 是已知常量或因观测值而异的权重。(在 Minitab 中,当为权重指定函数 a(ϕ) 时,会进行相应调整。)
指数族的成员可以是离散分布或连续分布。作为指数族成员的连续分布的示例包括正态分布和 Gamma 分布。作为指数族成员的离散分布的示例包括二项分布和 Poisson 分布。下表列出了其中一些分布的特征。
| 分布 | ϕ | b(θ) | a(φ) | c(y, ϕ) |
| 正态 | σ2 | θ2/2 | φω |  |
| 二项 | 1 | 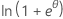 |
φ/ω | -ln(y!) |
| Poisson | 1 | exp(θ) | φ/ω |  |
链接函数
第二部分是链接函数。链接函数将第 i 个观测值中的响应变量的均值与如下形式的线性预测变量相关:
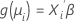
经典线性模型是此一般公式的特殊案例,其中,链接函数是恒等函数。
第二部分中链接函数的选择取决于第一部分的指数族的特定分布。特别是,指数族中的每个分布都有一个叫典范链接函数的特殊链接函数。此链接函数满足方程 g (μi) = Xi'β= θ,其中,θ 是典范参数。典范链接函数会生成一些需要的模型统计属性。可以使用拟合优度统计量比较使用不同链接函数的拟合。使用某些链接函数可能是出于历史原因或因为其在规律方面有特殊意义。例如,Logit 链接函数的优势之一就是它提供优势比的估计值。另一个示例是 Normit 链接函数,它假设存在一个基础变量,该变量遵循具有二元类别的正态分布。
Minitab 为每类模型提供三种链接函数。可以使用不同的链接函数确定能够充分拟合各种数据的模型。
对于二项模型,链接函数是 Logit、Normit(又称 Probit)和 Gompit(又称互补对数-对数)函数。这些函数是逆累积标准 Logistic 分布函数 (Logit)、逆累积标准正态分布函数 (Normit) 和逆 Gompertz 分布函数 (Gompit)。Logit 函数是二项模型的典范链接函数,因此 Logit 函数是默认的链接函数。
对于 Poisson 模型,链接函数是自然对数、平方根和恒等。自然对数函数是 Poisson 模型的典范链接函数,因此自然对数函数是默认的链接函数。
链接函数汇总如下:
| 模型 | 名称 | 链接函数,g(μi) |
| 二项 | Logit | 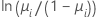 |
| 二项 | Normit (Probit) | 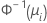 |
| 二项 | Gompit(互补对数 - 对数) |  |
| Poisson | 自然对数 | 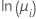 |
| Poisson | 平方根 |  |
| Poisson | 恒等 | 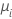 |
表示法
| 项 | 说明 |
|---|---|
| μi | 第 i 行的均值响应 |
| g(μi) | 链接函数 |
| X | 预测变量的向量 |
| β | 与预测变量相关的系数的向量 |
 | 正态分布的逆累积分布函数 |
因子/协变量模式
描述数据集中的一组因子/协变量值。Minitab 会为每种因子/协变量模式计算事件概率、残差及其他诊断度量标准。
例如,如果数据集包含性别和民族(因子)以及年龄(协变量),则这些预测变量的组合可能包含与对象一样多的不同的协变量模式。如果数据集仅包含民族和性别两个因子,且每个因子有两个编码水平,则仅存在四种可能的因子/协变量模式。如果您将输入的数据作为频率、成功、试验或失效数据,则每行包含一个因子/协变量模式。
Minitab 如何从拟合 Poisson 模型中的回归方程中删除高度相关的预测变量
使 rij 为与 Xi 和 Xj 相关联的当前扫掠矩阵中的元素。
一次输入或删除一个变量。对于当前不在其 rkk ≥ 1(默认值为 0.0001 的公差) 的模型中的独立变量,以及当前位于符合以下条件的模型中的每个变量 Xj,可以输入 Xk:

- Minitab 针对相关矩阵 R 执行 SWEEP 方法,并将 X1 … Xp 作为随机变量进行处理。
- 对于任何连续的预测变量,Minitab 将元素 rkk 与公差进行比较;rkk ≥ 公差,其中 k = 1 到 p。
- 对于当前位于模型中的每个变量 Xj,Minitab 检查 (rjj – rjk * (rkj / rkk)) * 公差是否 ≤ 1。
注意
其中,rkk、rjk、rjj 是在执行 k step SWEEP 操作之后,Xj 和 Xk 变量相应的对角和非对角元素。
- 否则,预测变量将无法通过检验并被从模型中删除。
注意
默认的公差值为 8.8e–12。
注意
您可以使用 GZLM 会话命令的 TOLERANCE 子命令来强制 Minitab 将某个预测变量保留在与另一个预测变量高度关联的模型中。但是,降低公差会很危险,可能会产生不准确的数字结果。