请选择您所选的方法或公式。
偏差
偏差可以度量当前模型和全模型之间的不一致。全模型是具有 n 个参数的模型,每个观测值对应一个参数。全模型可以最大化对数似然函数。全模型为少于 n 个参数的模型提供比较点。全模型比较使用尺度化的偏差。

对每个单独数据点的尺度化偏差的贡献取决于模型。
| 模型 | 偏差 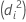 |
|---|---|
| 二项 | 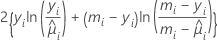 |
| Poisson | 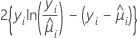 |
检验的自由度取决于样本数量和模型中的项数:

表示法
| 项 | 说明 |
|---|---|
| Lf | 全模型的对数似然 |
| Lc | 具有全模型中项的子组的模型的对数似然 |
| yi | 数据中第 i 行的事件数 |
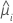 | 数据中第 i 行的估计均值响应 |
| mi | 数据中第 i 行的试验数 |
| n | 数据行数 |
| p | 回归自由度 |
Pearson
广义 Pearson 卡方统计量可以评估观测值和拟合值之间的相对差分。
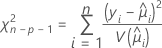
检验的自由度取决于样本数量和模型中的项数。Pearson 统计量具有用于正态数据的确切卡方分布。对于非正态数据(如二项分布和 Poisson 分布),统计量接近于渐近分布。
表示法
| 项 | 说明 |
|---|---|
| n | 数据行数 |
| p | 回归自由度 |
| yi | 第 i 个因子/协变量模式的响应值 |
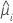 | 第 i 行的估计均值响应 |
| V(·) | 模型的方差函数,定义如下 |
方差函数取决于模型:
| 模型 | 方差函数 |
|---|---|
| 二项 | 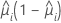 |
| Poisson | 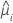 |
Hosmer-Lemeshow
基于以估计概率为基础的分组数据的二元响应模型的拟合优度检验。它是观测和估计的预期频率的 2 × g 表中的卡方统计量,其中,g 是组数。检验的自由度为 g − 2。
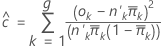
计算公式为:
要形成组,Minitab 会调整估计概率,然后尝试创建 10 个数量相等的组。
组的预期事件数为:
预期事件数 = 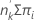
非事件数的预期值为:
预期的非事件数 = 
表示法
| 项 | 说明 |
|---|---|
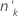 | 第 k 组的试验数 |
| ok | 中的事件数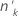 因子/协变量模式 因子/协变量模式 |
 | 每组的平均估计概率 |
| πi | 一个组中各个因子/协变量模式的拟合概率 |