关于本主题
Pearson 残差
Pearson 卡方的元素,可用于检测未能良好拟合的因子/协变量模式。Minitab 会存储第 i 个因子/协变量模式的 Pearson 残差。公式为:
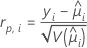
表示法
| 项 | 说明 |
|---|---|
| yi | 第 i 个因子/协变量模式的响应值 |
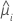 | 第 i 个因子/协变量模式的拟合值 |
| V | 在 处的模型方差函数 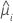 |
方差函数取决于模型:
| 模型 | 方差函数 |
| 二项 | 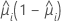 |
| Poisson | 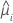 |
标准化和删后 Pearson 残差
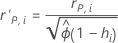
表示法
| 项 | 说明 |
|---|---|
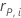 | 第 i 个因子/协变量模式的 Pearson 残差 |
 | 1,用于二项和 Poisson 模型 |
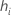 | 第 i 个因子/协变量模式的杠杆率 |
标准化 Pearson 残差并验证
公式
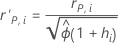
表示法
| 项 | 说明 |
|---|---|
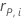
| the Pearson residual for the i(序号) validation row |

| 1, for the binomial and Poisson models |
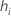 | the leverage for the i(序号) validation row |
偏差量残差
偏差量残差基于模型偏差,并且适用于标识未能良好拟合的因子/协变量模式。模型偏差是基于对数似然函数的拟合优度统计量。为第 i 个因子/协变量模式定义的偏差量残差为:

表示法
| 项 | 说明 |
|---|---|
| yi | 第 i 个因子/协变量模式的响应值 |
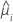 | 第 i 个因子/协变量模式的拟合值 |
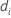 | 第 i 个因子/协变量模式的偏差 |
标准化偏差量残差

表示法
| 项 | 说明 |
|---|---|
| rD,i | 第 i 个因子/协变量模式的偏差量残差 |
| hi | 第 i 个因子/协变量模式的杠杆率 |
标准化残差偏差并验证
公式

表示法
| 项 | 说明 |
|---|---|
| rD,i | The deviance residual for the i(序号) validation row |
| hi | The leverage for the i(序号) validation row |
删后偏差量残差

表示法
| 项 | 说明 |
|---|---|
| yi | 第 i 个因子/协变量模式的响应值 |
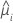 | 第 i 个因子/协变量模式的拟合值 |
| hi | 第 i 个因子/协变量模式的杠杆率 |
| r'D,i | 第 i 个因子/协变量模式的标准化偏差量残差 |
| r'P,i | 第 i 个因子/协变量模式的标准化 Pearson 残差 |
1. Pregibon, D. (1981)。“Logistic Regression Diagnostics”(Logistic 回归诊断), The Annals of Statistics(统计学年刊),第 9 卷第 4 期,第 705 至 724 页。
Delta 卡方
Minitab 会计算由于删除所有包含第 j 个因子/协变量模式的观测值而导致的 Pearson 卡方变化。Minitab 会针对数据中的每个可区分因子/协变量模式存储一个 Delta 卡方值。您可以使用 Delta 卡方检测未能良好拟合的因子/协变量模式。Delta 卡方的公式为:
公式
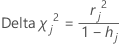
表示法
| 项 | 说明 |
|---|---|
| hj | 杠杆率 |
| rj | Pearson 残差 |
Delta 偏差
Minitab 会通过删除所有包含第 j 个因子/协变量模式的观测值来计算偏差统计量变化。Minitab 会针对数据中的每个可区分因子/协变量模式存储一个值。您可以使用 Delta 偏差检测未能良好拟合的因子/协变量模式。偏差统计量变化为:
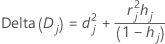
表示法
| 项 | 说明 |
|---|---|
| hj | 杠杆率 |
| rj | Pearson 残差 |
| dj | 偏差量残差 |
Delta beta(标准化)
Minitab 会通过删除所有包含第 j 个因子/协变量模式的观测值来计算该变化。会针对数据中的每个可区分因子/协变量模式存储一个值。您可以使用标准化 delta β 来检测严重影响系数估计值的因子/协变量模式。该值基于标准化 Pearson 残差。
公式
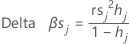
表示法
| 项 | 说明 |
|---|---|
| hj | 杠杆率 |
| rs j | 标准化 Pearson 残差 |
Delta beta
Minitab 会通过删除所有包含第 j 个因子/协变量模式的观测值来计算该变化。会针对数据中的每个可区分因子/协变量模式存储一个值。您可以使用 Delta β 来检测严重影响系数估计值的因子/协变量模式。该值基于 Pearson 残差。
公式
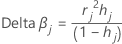
表示法
| 项 | 说明 |
|---|---|
| hj | 杠杆率 |
| rj | Pearson 残差 |
杠杆率
杠杆率是广义帽子矩阵的对角线元素。杠杆率可用于检测可能对结果有显著影响的因子/协变量模式。
公式
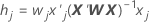
表示法
| 项 | 说明 |
|---|---|
| wj | 与系数拟合的权重矩阵的第 j 个对角线元素 |
| xj | 设计矩阵的第 j 行 |
| X | 设计矩阵 |
| X' | x 的转置 |
| W | 系数估计值的权重矩阵 |
杠杆率并验证
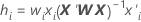
表示法
| 项 | 说明 |
|---|---|
| wi | the internal weight for the i(序号) validation row |
| xi | the row of the design matrix for the predictors in the i(序号) validation row |
| X | the design matrix for the training data set |
| X' | the transpose of X |
| W | the diagonal matrix of internal weights for the training data set |
Cook 距离
公式
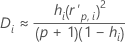
表示法
| 项 | 说明 |
|---|---|
| hi | 第 i 个因子/协变量模式的杠杆率 |
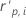 | 第 i 个因子/协变量模式的标准化 Pearson 残差 |
| p | 回归自由度 |
DFITS
度量一次删除对拟合值的影响。DFITS 值较大的观测值可能是异常值。Minitab 会计算 DFITS 的近似值。
公式

表示法
| 项 | 说明 |
|---|---|
| hi | 数据点的杠杆率 |
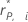 | 数据点的删后 Pearson 残差 |
方差膨胀因子 (VIF)

表示法
| 项 | 说明 |
|---|---|
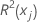 | 将 xj 的判定系数作为响应变量,将模型中的其他项作为预测变量 |
1. P. McCullagh 和 J. A. Nelder (1989),Generalized Linear Models(广义线性模型),第 2 版,出版机构为伦敦的 Chapman & Hall/CRC。