指数族和链接函数
从经典线性模型扩展到广义线性模型包含两部分:指数族分布和链接函数。
指数族
第一部分会将线性模型扩展到作为大型分布族(称为指数族)成员的响应变量。分布的指数族成员具有已观测响应变量的概率分布函数,这些函数的一般形式为:
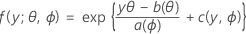
其中,a(∙)、b(∙) 和 c(∙) 取决于响应变量的分布。参数 θ 是位置参数,通常称为典范参数,ϕ 称为离差参数。通常情况下,函数 a(ϕ) 的形式为 a(ϕ)= ϕ/ ω,其中,ω 是已知常量或因观测值而异的权重。(在 Minitab 中,当为权重指定函数 a(ϕ) 时,会进行相应调整。)
指数族的成员可以是离散分布或连续分布。作为指数族成员的连续分布的示例包括正态分布和 Gamma 分布。作为指数族成员的离散分布的示例包括二项分布和 Poisson 分布。下表列出了其中一些分布的特征。
| 分布 | ϕ | b(θ) | a(φ) | c(y, ϕ) |
| 正态 | σ2 | θ2/2 | φω |  |
| 二项 | 1 | 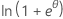 |
φ/ω | -ln(y!) |
| Poisson | 1 | exp(θ) | φ/ω |  |
链接函数
第二部分是链接函数。链接函数将第 i 个观测值中的响应变量的均值与如下形式的线性预测变量相关:
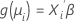
经典线性模型是此一般公式的特殊案例,其中,链接函数是恒等函数。
第二部分中链接函数的选择取决于第一部分的指数族的特定分布。特别是,指数族中的每个分布都有一个叫典范链接函数的特殊链接函数。此链接函数满足方程 g (μi) = Xi'β= θ,其中,θ 是典范参数。典范链接函数会生成一些需要的模型统计属性。可以使用拟合优度统计量比较使用不同链接函数的拟合。使用某些链接函数可能是出于历史原因或因为其在规律方面有特殊意义。例如,Logit 链接函数的优势之一就是它提供优势比的估计值。另一个示例是 Normit 链接函数,它假设存在一个基础变量,该变量遵循具有二元类别的正态分布。
Minitab 为每类模型提供三种链接函数。可以使用不同的链接函数确定能够充分拟合各种数据的模型。
对于二项模型,链接函数是 Logit、Normit(又称 Probit)和 Gompit(又称互补对数-对数)函数。这些函数是逆累积标准 Logistic 分布函数 (Logit)、逆累积标准正态分布函数 (Normit) 和逆 Gompertz 分布函数 (Gompit)。Logit 函数是二项模型的典范链接函数,因此 Logit 函数是默认的链接函数。
对于 Poisson 模型,链接函数是自然对数、平方根和恒等。自然对数函数是 Poisson 模型的典范链接函数,因此自然对数函数是默认的链接函数。
链接函数汇总如下:
| 模型 | 名称 | 链接函数,g(μi) |
| 二项 | Logit | 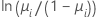 |
| 二项 | Normit (Probit) | 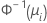 |
| 二项 | Gompit(互补对数 - 对数) |  |
| Poisson | 自然对数 | 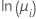 |
| Poisson | 平方根 |  |
| Poisson | 恒等 | 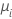 |
表示法
| 项 | 说明 |
|---|---|
| μi | 第 i 行的均值响应 |
| g(μi) | 链接函数 |
| X | 预测变量的向量 |
| β | 与预测变量相关的系数的向量 |
 | 正态分布的逆累积分布函数 |
系数
[1] P. McCullagh 和 J. A. Nelder (1989)。Generalized Linear Models(广义线性模型),第 2 版,Chapman & Hall/CRC, London。
系数的标准误
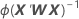
W 是对角矩阵,其中通过以下公式可以得出对角线元素的:
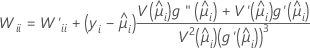
其中

此方差-协方差矩阵基于与 Fisher 的信息矩阵相对的已观测的 Hessian 矩阵。Minitab 使用已观测的 Hessian 矩阵,因为针对任何条件均值错误设定,该矩阵生成的模型更稳健。
如果使用规范链接,则已观测的 Hessian 矩阵与 Fisher 的信息矩阵相同。
表示法
| 项 | 说明 |
|---|---|
| yi | 第 i 行的响应值 |
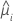 | 第 i 行的估计均值响应 |
| V(·) | 下表列出的方差函数 |
| g(·) | 链接函数 |
| V '(·) | 方差函数的一阶导数 |
| g'(·) | 链接函数的一阶导数 |
| g''(·) | 链接函数的二阶导数 |
方差函数取决于模型:
| 模型 | 方差函数 |
| 二项 | 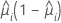 |
| Poisson | 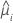 |
有关详细信息,请参见 [1] 和 [2]。
[1] A. Agresti (1990)。Categorical Data Analysis(类别数据分析)。John Wiley & Sons, Inc.
[2] P. McCullagh 和 J.A. Nelder (1992)。Generalized Linear Model(广义线性模型)。Chapman & Hall。
二元 Logistic 回归的优势比
仅当您为具有二元响应的模型选择 logit 链接函数时才提供优势比。在这种情况下,优势比可用于解释预测变量与响应之间的关系。
优势比 (τ) 可以是任何非负数。优势比 = 1 时可用作比较的基线。如果 τ = 1,则响应和预测变量之间不存在关联。如果 τ < 1,则因子的参考水平(或连续预测变量的更低水平)的事件优势较高。如果 τ > 1,则因子的参考水平(或连续预测变量的更低水平)的事件优势较小。值距离 1 越远表示关联度越大。
注意
对于具有一个协变量或因子的二元 Logistic 回归模型,估计的成功几率为:
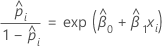
指数关系可为 β 提供解释:x 每增加一个单位,优势就成倍增加 eβ1。优势比等于 exp(β1)。
例如,如果 β 为 0.75,则优势比为 exp(0.75),即 2.11。这意味着 x 每增加一个单位,成功优势就增加 111%。
表示法
| 项 | 说明 |
|---|---|
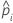 | 数据中第 i 行的估计成功概率 |
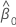 | 估计的截距系数 |
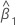 | 预测变量 x 的估计系数 |
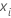 | 第 i 行的数据点 |
方差-协方差矩阵
d x d 矩阵,其中,d 为预测变量数加一。每个系数的方差在对角线单元中,每对系数的协方差在相应的非对角线单元中。方差是系数标准误的平方。
方差-协方差矩阵来自信息矩阵的逆矩阵的最后一次迭代。方差-协方差矩阵具有以下形式:
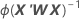
W 是对角矩阵,其中通过以下公式可以得出对角线元素:

其中

此方差-协方差矩阵基于与 Fisher 的信息矩阵相对的已观测的 Hessian 矩阵。Minitab 使用已观测的 Hessian 矩阵,因为针对任何条件均值错误设定,该矩阵生成的模型更稳健。
如果使用规范链接,则已观测的 Hessian 矩阵与 Fisher 的信息矩阵相同。
表示法
| 项 | 说明 |
|---|---|
| yi | 第 i 行的响应值 |
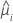 | 第 i 行的估计均值响应 |
| V(·) | 下表列出的方差函数 |
| g(·) | 链接函数 |
| V '(·) | 方差函数的一阶导数 |
| g'(·) | 链接函数的一阶导数 |
| g''(·) | 链接函数的二阶导数 |
方差函数取决于模型:
| 模型 | 方差函数 |
| 二项 | 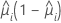 |
| Poisson | 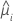 |
有关详细信息,请参见 [1] 和 [2]。
[1] A. Agresti (1990)。Categorical Data Analysis(类别数据分析)。John Wiley & Sons, Inc.
[2] P. McCullagh 和 J.A. Nelder (1992)。Generalized Linear Model(广义线性模型)。Chapman & Hall。