注意
此命令适用于 预测分析模块。单击此处了解更多关于如何激活模块的信息。
单预测变量部分依赖图
假设训练数据集中有 m 个预测变量,表示为 x1、x2、...、xm。首先,按升序对训练数据集中预测变量 x1 的可区分值进行排序。将 x11 表示为 x 1 的第一个可区分值。则 x11 是图最左端的 x 坐标。
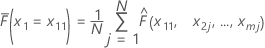
| 项 | 说明 |
|---|---|
| N | 训练数据集中的总行数 |
 | 为
观测到的值 在训练数据集中
在训练数据集中 |
| j | J 行的每一行 |
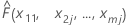 | 在 x1 = x11、x2 = x2j、....、xm = xmj 时,模型的拟合值 |
以 x1 的每个可区分值替换 x11,我们可获得图上其余点的 y 坐标。采用类似方式完成其余预测变量的计算。
使用大型数据集计算 x 的所有可区分值的所有 y 坐标可能非常耗时。对于 TreeNet® 模型,有更快的计算方法。请参考 Friedman, J. H. (2001)。Greedy function approximation: A gradient boosting machine(贪婪函数近似:梯度推进机)。The Annals of Statistics(统计学年刊),第 29 卷(第 5 期),第 1221 页。
多项式响应案例的计算相似。这里的拟合值来自每个单独类别的模型。
双预测变量部分依赖图
假设训练数据集中有 m 个预测变量,表示为 x1、x2、...、xm。首先,按升序对训练数据集中预测变量 x1、x2 的可区分值进行排序。将 x11、x21 表示为不同的配对之一。然后,每对在曲面图上绘制一个点的 x 和 y 坐标。
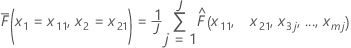
| 项 | 说明 |
|---|---|
| N | 全部共享 x1 = x11、x2 = x21 公因子方差的训练数据集中的总行数 |
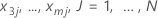 | 为
观测到的值 在训练数据集中
在训练数据集中 |
| j | J 行的每一行 |
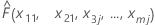 | 当 x1 = x11、x2 = x21、x3 = x3j....、xm = xmj 时,模型的拟合值 |
完成 x 1 和 x2 的所有可区分值组合的计算,可生成等值线图或曲面图的所有 z 坐标。对于大型数据集,计算所有可区分的 x 和 y 对都很耗时。对于 TreeNet® 模型,有更快的计算方法。请参考 Friedman, J. H. (2001)。Greedy function approximation: A gradient boosting machine(贪婪函数近似:梯度推进机)。The Annals of Statistics(统计学年刊),第 29 卷(第 5 期),第 1221 页。