注意
此命令适用于 预测分析模块。单击此处了解更多关于如何激活模块的信息。
一组研究人员希望利用注塑成型过程的数据来研究可将塑料部件的一种强度最大化的机器的设置。变量包括对机器、不同的塑料配方和注塑机的控制。
作为对数据的初始探索的一部分,研究人员决定通过按顺序删除不重要的预测变量来识别关键预测变量,从而使用 发现关键预测变量 来比较模型。研究人员希望找出对响应影响最大的关键预测变量,并进一步深入了解响应与关键预测变量之间的关系。
- 打开样本数据集注射过程.MWX。
- 选择 。
- 在响应中,输入强度。
- 在 连续预测变量中,输入 '注射压力' – '测量温度'。
- 在 类别预测变量 中,输入 机器 和 公式。
- 单击 确定。
解释结果
对于此分析,Minitab Statistical Software 比较了 20 个模型。模型评估表的模型列中的星号显示,具有交叉验证 R2 统计量的最大值的模型是模型 16。模型 16 包含 5 个重要预测变量。模型评估表之后的结果适用于模型 16。
虽然模型 16 具有交叉验证 R2 统计量的最大值,但其他模型具有类似的值。团队可以单击 选择备择模型,以从模型评估表中生成其他模型的结果。
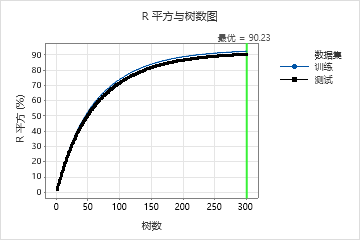
在模型 16 的结果中,R 平方与树数图显示,最优树数等于分析中的树数 300。团队可以单击 调整超参数 以增加树数,并查看其他超参数的更改是否提高了模型的性能。
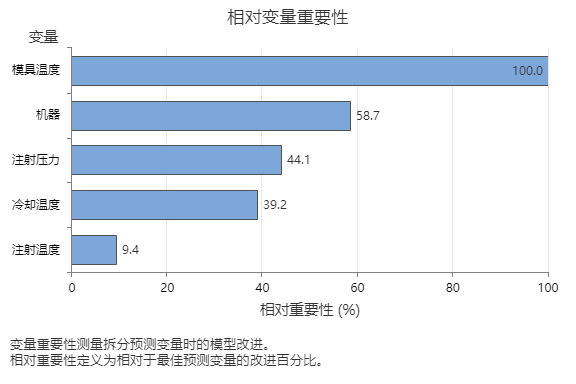
相对变量重要性图按照在对树序列上的预测变量进行拆分时预测变量对模型的改进作用的顺序,绘制预测变量的重要性图。最重要的预测变量为“模具温度”。如果顶部预测变量“模具温度”的重要度为 100%,则下一个重要变量“机器”的贡献为 58.7%。这意味着注塑机器与模具内部的温度一样重要,为 58.7%。
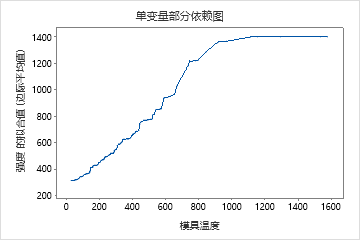
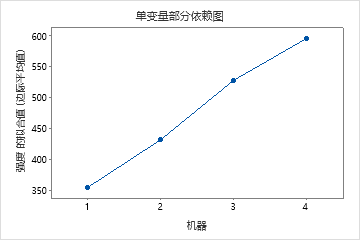
使用部分依赖图可以深入了解重要变量或变量对如何影响预测的响应。部分依赖图显示响应与变量之间的关系是线性、单调还是更复杂的关系。
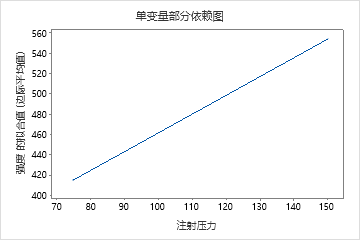
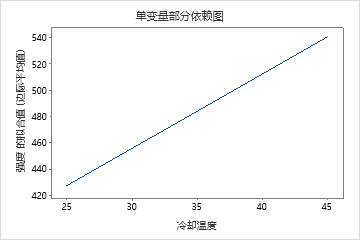
单预测变量部分依赖图显示,模具温度、注塑压力和冷却温度都与强度存在正向关系。机器图显示了机器之间的差异,机器 1 的部件平均最弱,机器 4 的部件平均最强。研究小组注意到,模具温度和机器在数据中的交互作用最强,因此他们查看双预测变量部分依赖图,以进一步了解这些变量如何影响强度。团队可以在结果中进行选择 ,以生成其他变量的绘图,例如 Injection Temperature (注射温度)。
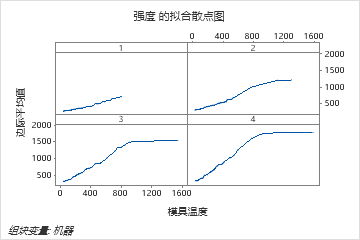
模具温度和机器的双预测变量部分依赖图提供了对机器平均强度差异的一些见解。原因之一是,来自机器 1 的数据包含的最高模具温度下的观测结果不如其他机器那么多。当其他设置相同时,团队仍然可以决定寻找机器产生不同优势的其他原因。团队可以在结果中单击 以生成其他变量对的图。
方法
| 损失函数 | 平方误差 |
|---|---|
| 选择最优树数量的标准 | 最大 R 平方 |
| 模型验证 | 3 折叠交叉验证 |
| 学习速率 | 0.01408 |
| 子样本部分 | 0.5 |
| 每个树的最大终端节点数 | 6 |
| 最小终端节点大小 | 3 |
| 为进行节点拆分而选定的预测变量数 | 预测变量总数 = 21 |
| 已使用的行数 | 1408 |
响应信息
| 均值 | 标准差 | 最小值 | 下四分位数 | 中位数 | 上四分位数 | 最大值 |
|---|---|---|---|---|---|---|
| 485.247 | 318.611 | 41.2082 | 301.099 | 398.924 | 562.449 | 2569.04 |
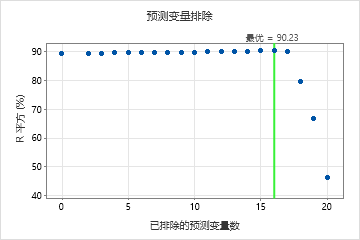
通过排除不重要的预测变量选择模型
| 模型 | 最优树数 | R 平方 (%) | 预测变量数 | 已排除的预测变量 |
|---|---|---|---|---|
| 1 | 300 | 89.32 | 21 | 无 |
| 2 | 300 | 89.34 | 19 | 塑料流速, 更改位置 |
| 3 | 300 | 89.39 | 18 | 干燥温度 |
| 4 | 300 | 89.46 | 17 | 熔融温度区2 |
| 5 | 300 | 89.51 | 16 | 塑料温度 |
| 6 | 300 | 89.50 | 15 | 公式 |
| 7 | 300 | 89.59 | 14 | 保持压力 |
| 8 | 300 | 89.57 | 13 | 螺丝垫 |
| 9 | 300 | 89.69 | 12 | 熔融温度区4 |
| 10 | 300 | 89.70 | 11 | 后压 |
| 11 | 300 | 89.86 | 10 | 熔融温度区1 |
| 12 | 300 | 89.90 | 9 | 干燥时间 |
| 13 | 300 | 89.92 | 8 | 测量温度 |
| 14 | 300 | 90.06 | 7 | 熔融温度区5 |
| 15 | 300 | 90.16 | 6 | 熔融温度区3 |
| 16* | 300 | 90.23 | 5 | 螺丝旋转速度 |
| 17 | 300 | 89.96 | 4 | 注射温度 |
| 18 | 297 | 79.37 | 3 | 冷却温度 |
| 19 | 244 | 66.64 | 2 | 注射压力 |
| 20 | 164 | 46.19 | 1 | 机器 |
模型汇总
| 总预测变量 | 5 |
|---|---|
| 重要预测变量 | 5 |
| 增长的树数 | 300 |
| 最优树数 | 300 |
| 统计量 | 训练 | 测试 |
|---|---|---|
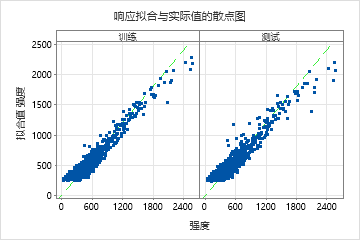
| R 平方 | 92.23% | 90.23% |
| 均方根误差 (RMSE) | 88.8049 | 99.5673 |
| 均方误差 (MSE) | 7886.3152 | 9913.6420 |
| 平均绝对偏差 (MAD) | 68.9231 | 74.4113 |
| 平均绝对百分比误差 (MAPE) | 0.2083 | 0.2175 |