要确定模型对数据的拟合优度,请检查模型汇总表格中的统计量。
预测变量总数
可用于模型的总预测变量数。该值为您指定的连续预测变量和类别预测变量的总和。
重要预测变量
模型中重要预测变量的数量。重要预测变量是在模型中至少具有 1 个基函数的变量。
解释
可以使用“相对变量重要性”图来显示相对变量重要性的顺序。例如,假设 20 个预测变量中有 10 个在模型中具有基函数,则“相对变量重要性”图按重要性顺序显示变量。
最大基函数数
算法为搜索最佳模型而构建的基础函数数。
解释
默认情况下,Minitab 统计软件将最大基函数数设置为 30。当 30 个基函数对于数据来说似乎太小时,请考虑更大的值。例如,当您认为超过 30 个预测变量很重要时,请考虑较大的值。
最佳基函数数
最优模型中基函数的数量。
解释
在分析估计具有最大基函数数的模型后,分析将使用向后消除过程从模型中删除基函数。分析逐个移除对模型拟合贡献最小的基函数。在每个步骤中,分析将计算分析的最优性准则值,即 R 平方或平均绝对偏差。消除过程完成后,最佳基函数数是消除过程中产生准则最优值的数字。
R 平方
R2 是由模型解释的响应的变异百分比。异常值对 R2 的影响大于对 MAD 和 MAPE 的影响。
使用验证方法时,表中包含训练数据集的R2 统计量和验证方法的R2 统计量。当验证方法是k折交叉验证时,验证会使用每个折叠,前提是树构建排除了该折叠。验证结果中的R2 统计量通常是衡量模型在新数据下工作方式的更好指标。
解释
使用 R2 可确定模型与数据的拟合程度。R2 值越高,模型与数据的拟合度越好。R2 始终介于 0% 和 100% 之间。
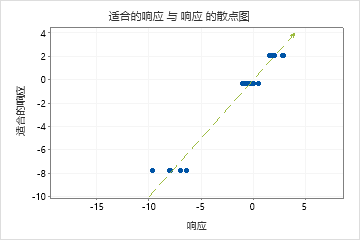
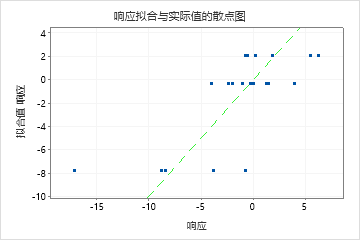
验证R2 远小于训练R2,说明模型可能无法很好地预测新病例的响应值,而模型拟合当前数据集。
均方根误差 (RMSE)
均方根误差 (RMSE) 衡量模型的准确度。异常值对 RMSE 的影响大于对 MAD 和 MAPE 的影响。
当你使用验证方法时,表中包含训练数据集的RMSE统计量和验证结果的RMSE统计量。当验证方法是k折交叉验证时,验证会使用每个折叠,前提是树构建排除了该折叠。验证RMSE统计量通常是衡量模型在新数据中工作方式的更好指标。
解释
用于比较不同模型的拟合。值越小,拟合越好。验证RMSE远低于训练RMSE表明模型可能无法很好地预测新病例的反应值,而模型对当前数据集的拟合度较低。
均方误 (MSE)
均方误 (MSE) 衡量模型的准确度。异常值对 MSE 的影响大于对 MAD 和 MAPE 的影响。
当你使用验证方法时,表中包含训练数据集的MSE统计量和验证结果的MSE统计量。当验证方法是k重交叉验证时,验证会在模型构建排除该折叠时使用每个折点。验证MSE统计量通常是衡量模型在新数据中工作方式的更好指标。
解释
用于比较不同模型的拟合。值越小,拟合越好。验证MSE远低于训练MSE表明模型可能无法很好地预测新病例的反应值,而模型对当前数据集的拟合度较低。
平均绝对偏差 (MAD)
平均绝对偏差 (MAD) 以与数据相同的单位表示准确度,这有助于使误差量概念化。异常值对 MAD 的影响小于对 R2、RMSE 和 MSE 的影响。
当你使用验证方法时,表中包含训练数据集的MAD统计量和验证结果的MAD统计量。当验证方法是k重交叉验证时,验证会在模型构建排除该折叠时使用每个折点。验证MAD统计量通常是衡量模型在新数据中工作方式的更好指标。
解释
用于比较不同模型的拟合。值越小,拟合越好。验证MAD远低于训练MAD表明模型可能无法很好地预测新病例的反应值,而模型对当前数据集的拟合度较低。