概述
默认情况下,Minitab Statistical Software 为误分类成本在最小误分类成本 1 个标准误内的最小树生成输出。Minitab 允许您从可以识别最优树的序列中探索其他树。通常,选择备择树有以下两个原因:
- 最优树是误分类成本降低的模式的一部分。具有更多个节点的一个或多个树属于同一模式。通常,您希望从树进行预测,并尽可能地提高预测准确度。如果树足够简单,您还可以使用它来了解每个预测变量如何影响响应值。
- 最优树是误分类成本相对平直的模式的一部分。与最优树相比,模型汇总统计量相似的一个或多个树的节点要少得多。通常,树的终端节点越少,越能清晰地显示每个预测变量如何影响响应值。较小的树也更易于识别一些目标组,以便进一步研究。如果较小树的预测准确度差异可以忽略不计,则也可以使用较小的树来评估响应变量与预测变量之间的关系
例如,在下面的图中,具有 4 个节点的树为最优树。接下来的两个较大的树是误分类成本降低的模式的一部分。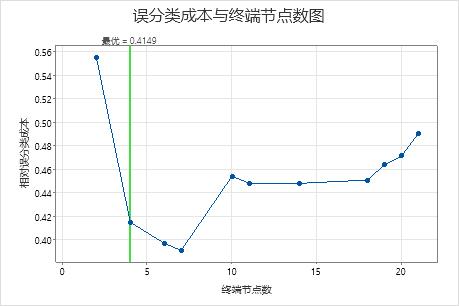
7 节点树的误分类成本低于 4 节点树的成本。由于 7 节点树的复杂度相似,因此可以使用较大的树及其附加的预测准确度来研究重要变量并进行预测。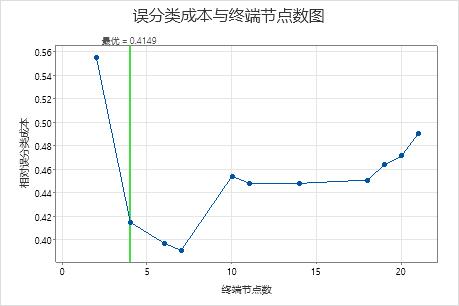
除了备择树的标准值外,您还可以比较树的复杂度和不同节点的有效性。关于为何与选择其他树相比,分析人员选择的特定树不会影响性能,请考虑以下原因示例:
- 分析人员选择可为最重要的变量提供更清晰视图的较小树。
- 在分析中选择某个树是因为分裂所在的变量比另一个树中的变量更易于测量。
- 分析人员选择某个树是因为关注特定的终端节点。
执行分析
在输出中单击选择备择树。将打开一个对话框,其中显示图表、树状图和汇总树或所选节点的表。
选择备择树
该对话框提供了三种选择备择树的方法:
- 单击图上的某个点。
- 单击模型汇总表下的箭头按钮,选择一个比当前所选树大一或小一的树。
- 单击按钮来选择一个常用的树。当分析不使用验证时,引用标准误的按钮将不适用。
- 最小成本
- 选择误分类成本最低的树
- 1-SE 最小成本
- 选择误分类成本在最低成本一个标准误内的最小树。
- 2-SE 最小成本
- 选择误分类成本在最低成本 2 个标准误内的最小树。
- 最佳 ROC
- 选择 ROC 曲线下面积最大的树。
调查树和各个节点
树提供工具栏上的以下交互作用:
- 突出显示纯度最高的 5 个节点。这些节点为最优节点。
- 在详细树和节点分裂树之间切换。当您有一个大型树并且只想查看哪些变量分裂节点时,节点分裂树非常有用。
- 放大和缩小树。
您可以选择树上的各个节点,以查看表中有关节点的详细信息。详细信息包括各个类别的计数和总计数。详细信息还包括用于达到该节点的规则。单击将规则复制到剪贴板,以将规则粘贴到另一个位置中。
要重新选择整个树,请单击图中不是某个节点的任意位置。
创建新树
单击创建树可为您选择的备择树创建和存储结果。针对结果和存储的选择与原始树相同。备择树的图形和表位于新的输出选项卡中。存储的列位于原始数据的工作表中。