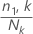使用每个事件概率作为阈值。对于特定阈值,估计事件概率大于或等于阈值的案例将获得 1 作为预测类别,否则获得 0。然后,可以为所有案例形成一个 2x2 的表,以观测类别作为行,以预测类别作为列来计算每个终端节点的假阳率和真阳率。假阳率是图表的 x 坐标,真阳率是 y 坐标。
例如,假设下表汇总了一个具有 4 个终端节点的树:
A:终端节点
B:事件数
C: 非事件数
D:案例数
E:阈值 (B/D)
4
18
12
30
0,60
1
25
42
67
0,37
3
12
44
56
0,21
2
4
32
36
0,11
合计
59
130
189
以下是相应的 4 个表,它们各自的假阳率和真阳率精确到小数点后 2 位:
表 : 1. 阈值 = 0.60.
假阳率 = 12 / (12 + 118) = 0.09
真阳率 = 18 / (18 + 41) = 0.31
预测
事件
非事件
观测
事件
18
41
非事件
12
118
表 : 2. 阈值 = 0.37.
假阳率 = (12 + 42) / 130 = 0.42
真阳率 = (18 + 25) / 59 = 0.73
预测
事件
非事件
观测
事件
43
16
非事件
54
76
表 : 3. 阈值 = 0.21.
假阳率 = (12 + 42 + 44) / 130 = 0.75
真阳率 = (18 + 25 + 12) / 59 = 0.93
预测
事件
非事件
观测
事件
55
4
非事件
98
32
表 : 4. 阈值 = 0.11.
假阳率 = (12 + 42 + 44 + 32) / 130 = 1
真阳率 = (18 + 25 + 12 + 4) / 59 = 1
预测
事件
非事件
观测
事件
59
0
非事件
130
0
单独的检验数据集
使用与训练数据集过程相同的步骤,但从检验数据集的案例中计算事件概率。
使用 k 折叠交叉验证进行检验
使用 k 折叠交叉验证在 ROC 曲线图上定义 x 和 y 坐标的过程具有额外的步骤。此步骤会创建许多可区分事件概率。例如,假设树状图包含 4 个终端节点。我们有 10 折叠交叉验证。那么,对于第 i 个折叠,您使用数据的 9/10 部分来估算折叠 i 中的案例的事件概率。当针对每个折叠重复此过程时,可区分事件概率的最大数为 4 *10 = 40。之后,按递减顺序对所有可区分事件概率进行排序。使用事件概率作为每个阈值,为整个数据集中的案例分配预测类别。在此步骤之后,将应用训练数据集过程从 3 到结束的步骤来查找 x 和 y 坐标。