重要预测变量
任何分类树都是一组分裂的集合。每个分裂都提供对树的改进。每个分裂还包含代理分裂,这些分裂也提供对树的改进。当树使用变量来分裂节点,或将其作为代理来分裂节点而另一个变量的值缺失时,变量的重要性由其所有改进程度决定。
以下公式给出了单个节点的改进程度:
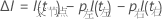
I(t)、p左和 p右的值取决于节点分裂标准。有关详细信息,请转到节点分裂方式 - CART® 分类。

负对数似然平均值
训练数据或无验证
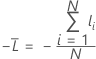
其中,
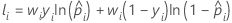
训练数据或无验证的表示法
| 项 | 说明 |
|---|---|
| N | 完整数据或训练数据的样本数量 |
| wi | 完整或训练数据集中第 i 个观测值的权重 |
| yi | 完整或训练数据集的指示变量,1 代表事件,其他情况下为 0 |
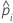 | 完整数据集或训练数据集中第 i 行事件的预测概率 |
K 折叠交叉验证
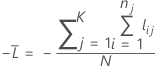
其中,

k 折叠交叉验证的表示法
| 项 | 说明 |
|---|---|
| N | 完整数据或训练数据的样本数量 |
| nj | 折叠 j 的样本数量 |
| wij | 折叠 j 中第 i 个观测值的权重 |
| yij | 折叠 j 中数据的指示变量,1 代表事件,其他情况下为 0 |
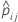 | 模型估计中不包括折叠 j 第 i 个观测值的事件的预测概率 |
检验数据集
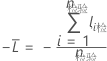
其中,
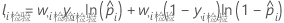
检验数据集的表示法
| 项 | 说明 |
|---|---|
| n检验 | 测试集的样本数量 |
| wi,检验 | 检验数据集中第 i 个观测值的权重 |
| yi,检验 | 测试集中数据的指示变量,1 代表事件,其他情况下为 0 |
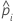 | 测试集中第 i 行的事件的预测概率 |
ROC 曲线下面积
公式


对于曲线下面积,Minitab 使用积分。

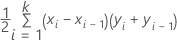
其中,k 是终端节点数,(x0, y0) 是点 (0, 0)。
| x(假阳率) | y(真阳率) |
|---|---|
| 0.0923 | 0.3051 |
| 0.4154 | 0.7288 |
| 0.7538 | 0.9322 |
| 1 | 1 |
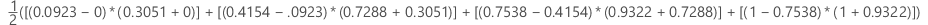

表示法
| 项 | 说明 |
|---|---|
| TRP | 真阳率 |
| FPR | 假阳率 |
| TP | 正确评估的事件的真阳性 |
| P | 实际阳性的事件数 |
| FP | 正确评估的非事件的真阴性 |
| N | 实际阴性的事件数 |
| FNR | 假阴率 |
| TNR | 真阴率 |
ROC 曲线下面积的 95% 置信区间
以下区间给出置信区间的上限和下限:
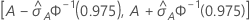
ROC 曲线下面积的标准误计算 (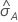 ) 来自 Salford Predictive Modeler®。有关 ROC 曲线下面积方差估算的一般信息,请参阅以下参考资料:
) 来自 Salford Predictive Modeler®。有关 ROC 曲线下面积方差估算的一般信息,请参阅以下参考资料:
Engelmann, B. (2011)。Measures of a ratings discriminative power: Applications and limitations(评级鉴别力度量:应用和限制)。发表于 B. Engelmann 和 R. Rauhmeier(编辑)编著的 The Basel II Risk Parameters:Estimation, Validation, Stress Testing - With Applications to Loan Risk Management(Basel II 风险参数:估计、验证、压力检验 - 贷款风险管理应用案例,第二版) 海德堡;纽约:Springer。doi:10.1007/978-3-642-16114-8
Cortes, C. 和 Mohri, M.(2005 年)。Confidence intervals for the area under the ROC curve(ROC 曲线下面积的置信区间)。Advances in neural information processing systems(神经信息处理系统的进步),305-312。
Feng, D.、Cortese, G. 和 Baumgartner, R. (2017)。A comparison of confidence/credible interval methods for the area under the ROC curve for continuous diagnostic tests with small sample size(比较 ROC 曲线下面积的置信区间方法,以利用小样本数量进行持续诊断检验)。Statistical Methods in Medical Research(医疗研究中的统计学方法),26(6),2603-2621。doi:10.1177/0962280215602040
表示法
| 项 | 说明 |
|---|---|
| A | ROC 曲线下面积 |
 | 标准正态分布的 0.975 百分位数 |
提升
公式
对于数据中分配给事件类别的概率最高的 10% 观测值,请使用以下公式。

对于使用检验数据集的检验提升,请使用检验数据集中的观测值。对于使用 k 折叠交叉验证的检验提升,选择要使用的数据,然后根据数据不在模型估计中的预测概率来计算提升。
表示法
| 项 | 说明 |
|---|---|
| d | 10% 数据中的案例数 |
 | 事件的预测概率 |
 | 训练数据中事件的概率,如果分析不使用验证,则为完整数据集中事件的概率 |
误分类成本
模型汇总表中的误分类成本是模型相对于将所有观测值分类为频率最高类别的细小分类器的相对误分类成本。
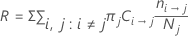
相对误分类成本的形式如下:
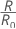
其中,R0 是细小分类器的成本。
当先验概率相等或来自数据时,R 的公式会简化。
先验概率相等

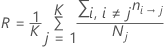
先验概率来自数据

使用此定义,R 具有以下形式:
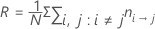
表示法
| 项 | 说明 |
|---|---|
| πj | 响应变量第 j 个类别的先验概率 |
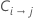 | 将类别 i 误分类为类别 j 的成本 |
 | 误分类为类别 j 的类别 i 记录数 |
| Nj | 响应变量第 j 个类别的案例数 |
| K | 响应变量中的类别数 |
| N | 数据中的案例数 |