一个研究小组收集并发布了有关影响心脏病的因素的详细信息。变量包括年龄、性别、胆固醇水平、最大心率等。本示例基于一个提供心脏病详细信息的公共数据集。原始数据来自于 archive.ics.uci.edu。
研究人员希望创建一个分类树,用于识别重要的预测变量,以指示患者是否患有心脏病。
- 打开样本数据 心脏病二进制.MWX。
- 选择 。
- 从下拉列表中,选择二元响应变量。
- 在响应中,输入心脏病。
- 在响应事件中,选择 是的以指示已将患者标识为患有心脏病。
- 在 连续预测变量中,输入 年龄、 胆固醇 血压 最大心率和 。 旧峰值
- 在 类别预测变量中,输入 性别、 血糖 运动绞痛 静息心电图 斜率 疼痛类型 血管和 。 地中海贫血
- 单击 确定。
解释结果
默认情况下,Minitab 显示误分类成本在误分类成本最低的树的 1 个标准误内的最小树。该树有 4 个终端节点。
在研究人员检查该树之前,他们查看了显示交叉验证的误分类成本和终端节点数的图表。在此图中,误分类成本降低的模式在 4 节点树之后会继续。在这种情况下,分析人员选择探索其他一些误分类成本更低的简单树。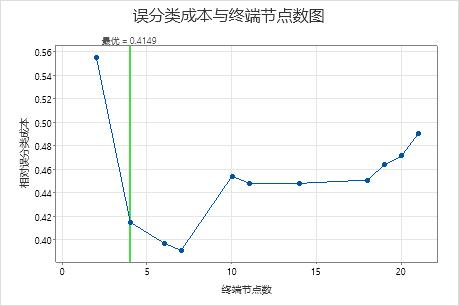
选择备择树
- 在输出中,单击选择备择树
- 在图中,选择误分类成本最低且 ROC 值最优的 7 节点树。
- 单击 创建树。
解释结果
在树状图中,蓝色的项代表事件水平。红色的项代表非事件水平。在此输出中,事件水平为“是”,表示某人患有心脏病。非事件水平为“否”,表示某人没有心脏病。
在根节点处,“是”事件的计数为 139,“否”事件的计数为 164。根节点使用变量 THAL 进行分裂。当 THAL = 正常时,转到左侧节点(节点 2)。当 THAL = 固定或可逆时,转到右侧节点(节点 5)。
- 节点 2:THAL 为“正常”时,有 167 个案例。在这 167 个案例中,有 38 个或 22.8% 为“是”,129 个或 77.2% 为“否”。
- 节点 5:当 THAL 为“固定”或“可逆”时,有 136 个案例。在这 136 个案例中,有 101 个或 74.3% 为“是”,35 个或 25.7% 为“否”。
左侧子节点和右侧子节点的下一个分裂变量为“胸痛类型”,疼痛等级为 1、2、3 或 4。
探索其他节点,看看哪些变量最值得关注。大多为蓝色的节点表示事件水平占比大。大多为红色的节点表示非事件水平占比大。
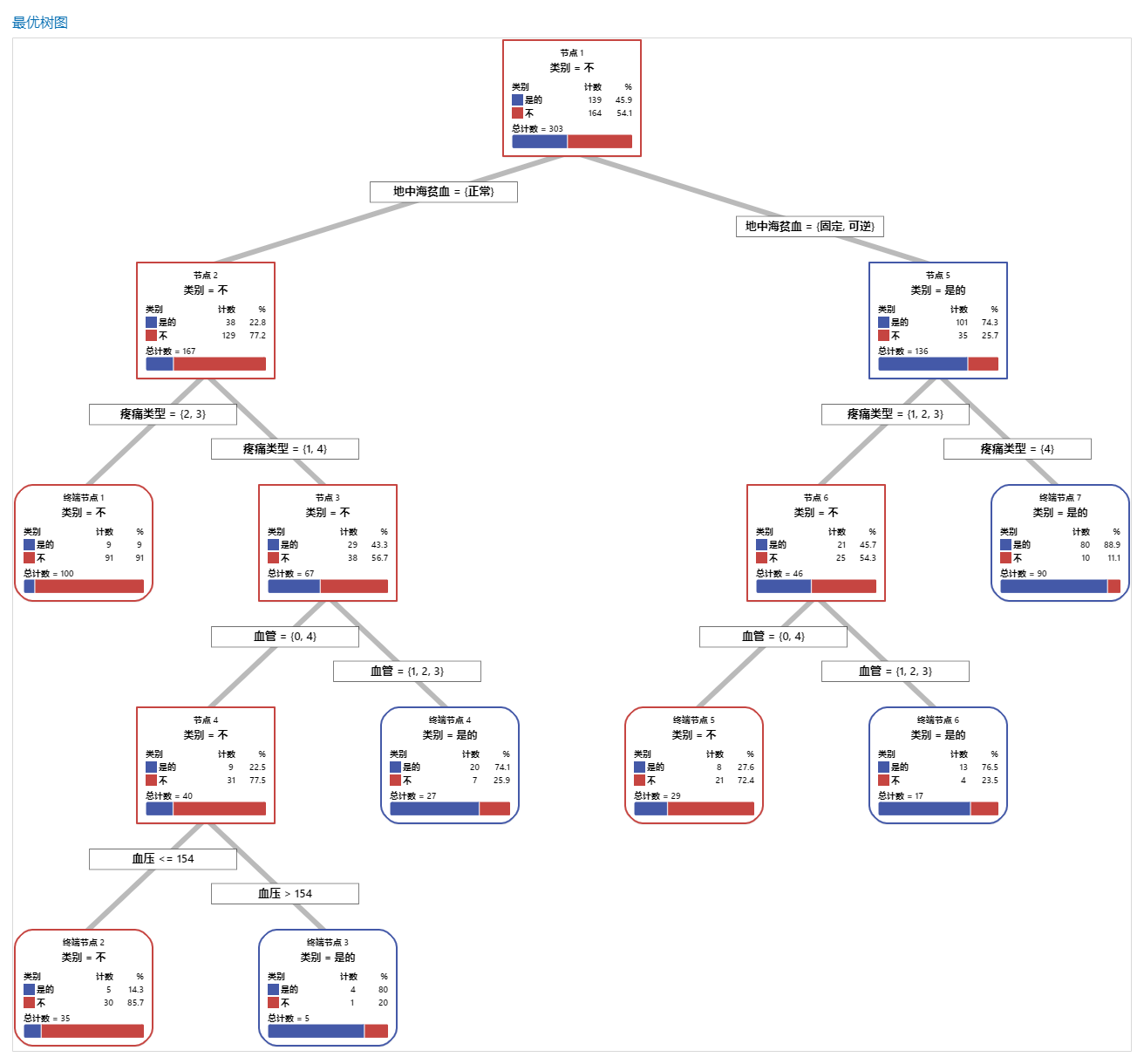
树状图使用整个数据集或训练数据集。您可以在详细视图和节点分裂视图之间切换树的视图。
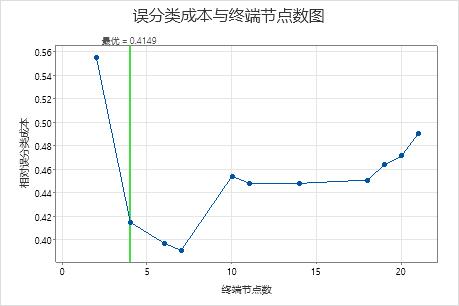
此树的误分类成本约为 0.391。
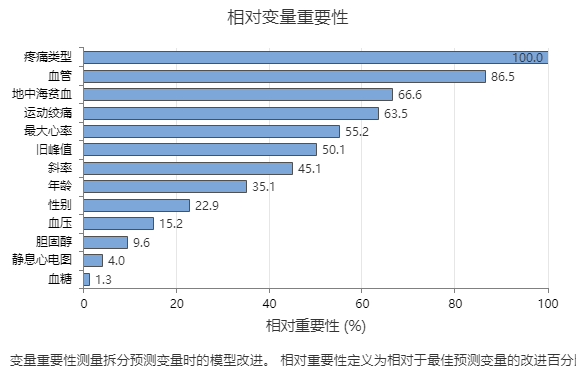
最重要的预测变量为“胸痛类型”。如果顶部预测变量胸痛类型的贡献为 100%,则下一个重要变量主要血管的贡献为 86.5%。这意味着在此分类树中,主要血管的重要性是胸痛类型的 86.5%。
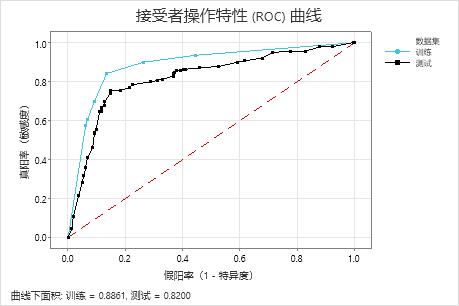
检验数据的 ROC 曲线下面积为 0.8200,这表明分类性能在很多应用中是合理的。对于需要更高预测准确性的应用程序,您可以尝试使用 TreeNet® 分类 模型或 Random Forests® 分类 模型来提高性能。
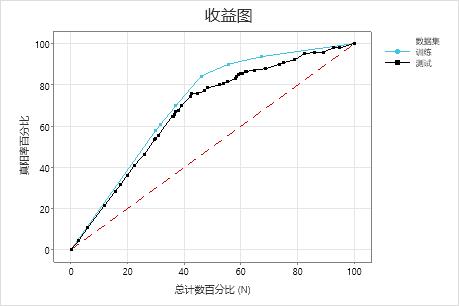
在此示例中,收益图显示参考线上方骤增,然后趋于平直。在这种情况下,大约 40% 的数据涵盖大约 70% 的真阳率。
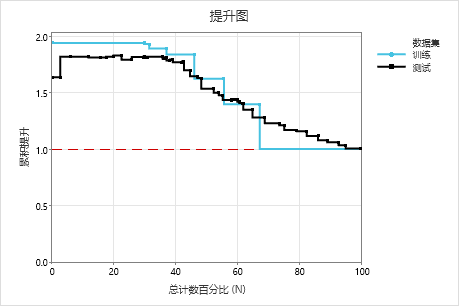
在此示例中,提升图显示参考线上方先有增加,然后逐渐降低。
7 节点 CART® 分类: 心脏病 与 年龄, 血压, 胆固醇, 最大心率, 旧峰值, 性别, 血糖, 运动绞痛, 静息心电图, 斜率, 地中海贫血, 疼痛类型, 血管
方法
| 先验概率 | 对所有类别相同 |
|---|---|
| 节点分裂 | 基尼 |
| 最优树 | 最小误分类成本 |
| 模型验证 | 10 折叠交叉验证 |
| 已使用的行数 | 303 |
二值响应信息
| 变量 | 类别 | 计数 | % |
|---|---|---|---|
| 心脏病 | 是的 (事件) | 139 | 45.87 |
| 不 | 164 | 54.13 | |
| 全部 | 303 | 100.00 |
模型汇总
| 总预测变量 | 13 |
|---|---|
| 重要预测变量 | 13 |
| 终端节点数 | 7 |
| 最小终端节点大小 | 5 |
| 统计量 | 训练 | 测试 |
|---|---|---|
| 负对数似然平均值 | 0.3971 | 0.5094 |
| ROC 曲线下面积 | 0.8861 | 0.8200 |
| 95% 置信区间 | (0.5590, 1) | (0.7702, 0.8697) |
| 提升 | 1.9376 | 1.8165 |
| 误分类成本 | 0.2924 | 0.3909 |
混淆矩阵
| 预测类别(训练) | 预测类别(测试) | ||||||
|---|---|---|---|---|---|---|---|
| 实际类别 | 计数 | 是的 | 不 | 正确百分比 | 是的 | 不 | 正确百分比 |
| 是的 (事件) | 139 | 117 | 22 | 84.2 | 105 | 34 | 75.5 |
| 不 | 164 | 22 | 142 | 86.6 | 24 | 140 | 85.4 |
| 全部 | 303 | 139 | 164 | 85.5 | 129 | 174 | 80.9 |
| 统计量 | 训练 (%) | 测试 (%) |
|---|---|---|
| 真阳率(敏感度或功效) | 84.2 | 75.5 |
| 假阳率(I 类错误) | 13.4 | 14.6 |
| 假阴率(II 类错误) | 15.8 | 24.5 |
| 真阴率(特异度) | 86.6 | 85.4 |
误分类
| 输入误分类成本 | 预测类别 | |
|---|---|---|
| 实际类别 | 是的 | 不 |
| 是的 | 1.00 | |
| 不 | 1.00 | |
| 训练 | 测试 | ||||||
|---|---|---|---|---|---|---|---|
| 实际类别 | 计数 | 分类有误 | 误差百分比 | 成本 | 分类有误 | 误差百分比 | 成本 |
| 是的 (事件) | 139 | 22 | 15.8 | 0.1583 | 34 | 24.5 | 0.2446 |
| 不 | 164 | 22 | 13.4 | 0.1341 | 24 | 14.6 | 0.1463 |
| 全部 | 303 | 44 | 14.5 | 0.1462 | 58 | 19.1 | 0.1955 |