主分量方法
在主分量分析中,Minitab 首先找到变量相关矩阵或协方差矩阵的正交特征向量集。主分量矩阵是特征向量矩阵与独立变量矩阵的产物。第一个主分量在数据总变异中占比最大,第二个主分量次之,以此类推。主分量的目的在于使用最少数量的分量解释最大量的方差。
系数的不唯一性
如果特征值不同并且不为零,则主分量的系数唯一(符号变化除外)。如果特征值重复,则与同一特征值对应的所有主分量向量的“空间跨度”是唯一的,但单个向量的空间跨度不唯一。因此,尽管特征值(分量的方差)始终相同,但 Minitab 在输出中显示的系数与书籍或其他程序中的系数可能不一致。
如果协方差矩阵的秩 r < p(其中,p 为变量数),则会有 p - r 个特征值等于零。与这些特征值对应的特征向量可能不唯一。如果观测值个数小于 p 或者存在多重共线性,则会出现这种情况。
特征向量
特征向量包括对应于每个变量的系数,是可用于计算主分量分值的每个变量的权重。特征向量在协方差或相关矩阵的频谱分解 S 或 R 中作为正交矩阵的列获取。更具体地说,由于 R 是对称的,正交矩阵 V 存在,使得 V'RV = D 或者,相当于 R = VDV',其中 D 是对角元素为特征值的对角矩阵。特征向量是 V 的列。特征向量产生于 R = VDV'。
表示法
| 项 | 说明 |
|---|---|
| R | 相关矩阵 |
| V | 特征向量矩阵 |
| D | 特征值的对角矩阵 |
分值
公式
分值是指原始变量的线性组合,这些变量说明数据中的方差。
分值计算如下:Z = YV
表示法
| 项 | 说明 |
|---|---|
| Z | 主分量分值矩阵 (n × m) |
| Y | 与相关矩阵方法配合使用的标准化数据矩阵 (n × p) |
| V | 特征向量矩阵 (p × m) |
注意
如果您使用协方差矩阵方法,而不是相关矩阵方法(默认),则 Minitab 对于 Y 使用原始数据矩阵,而不是标准化数据矩阵。
特征值
公式
特征值是协方差或相关矩阵(请参见主题“特征向量”)的频谱分解中对角矩阵的对角元素。特征值还表示主分量的样本方差 Z = V Y。
表示法
| 项 | 说明 |
|---|---|
| Z | 主分量分值矩阵 (n × m) |
| Y | 与相关矩阵方法配合使用的标准化数据矩阵 (n × p) |
| V | 特征向量矩阵 (p × m) |
注意
如果您使用协方差矩阵方法,而不是相关矩阵方法(默认),则 Minitab 对于 Y 使用原始数据矩阵,而不是标准化数据矩阵。
比率
公式
第 k个主分量解释的样本方差比率计算如下:
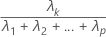
表示法
| 项 | 说明 |
|---|---|
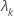 | 第 k个特征值 |
| p | 变量数 |
累积比率
公式
前 k 个主分量解释的样本方差累积比率计算如下: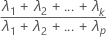
表示法
| 项 | 说明 |
|---|---|
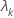 | 第 k个特征值 |
| p | 变量数 |
Mahalanobis 距离
公式


当 n – p – 1 为  0 时,Minitab 显示异常值图,不带参考线。
0 时,Minitab 显示异常值图,不带参考线。
表示法
| 项 | 说明 |
|---|---|
| Yi | 第 i 行的数据值向量 |
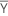 | 均值向量 |
| S-1 | 协方差矩阵的逆矩阵 |
| p | 变量数 |
| n | 非缺失行的数量 |