轴
Minitab 会计算各个主轴(亦称为主分量)。Minitab 按照主分量在总惯量的占比对主分量进行排序。第一个主分量(轴)占总惯量的大部分。第二个主分量(轴)占剩余总惯量的大部分,以此类推。
解释
使用主轴可评估哪些分量占数据变异性的大部分比率。
指示符矩阵分析
| 轴 | 惯量 | 比率 | 累积 | 直方图 |
|---|---|---|---|---|
| 1 | 0.4032 | 0.4032 | 0.4032 | ****************************** |
| 2 | 0.2520 | 0.2520 | 0.6552 | ****************** |
| 3 | 0.1899 | 0.1899 | 0.8451 | ************** |
| 4 | 0.1549 | 0.1549 | 1.0000 | *********** |
| 合计 | 1.0000 |
这些结果显示将总惯量分解成 4 个分量。这 4 个分量解释的总惯量是 1.000。在总惯量中,第一个分量占惯量的 40.32%,第二个分量占惯量的 25.20%。这两个变量总共占总惯量的 65.52%。因此,为分析指定 2 个变量可能不够。添加第 3 个分量可将惯量的累计比率增加到 84.51%。
惯量
分量的惯量描述分量解释的变异量。列的惯量描述该类别的值与预期值的差值(假定没有相关的类别变量)。要计算某个分量的惯量,Minitab 将每个类别的惯量乘以该分量的类别相关,然后合计所得乘积。
解释
使用分量的惯量可确定哪些分量在数据变异性中占大部分比率。
指示符矩阵分析
| 轴 | 惯量 | 比率 | 累积 | 直方图 |
|---|---|---|---|---|
| 1 | 0.4032 | 0.4032 | 0.4032 | ****************************** |
| 2 | 0.2520 | 0.2520 | 0.6552 | ****************** |
| 3 | 0.1899 | 0.1899 | 0.8451 | ************** |
| 4 | 0.1549 | 0.1549 | 1.0000 | *********** |
| 合计 | 1.0000 |
这些结果显示将总惯量分解成 4 个分量。这 4 个分量解释的总惯量是 1.000。在总惯量中,第一个分量(轴)占惯量的 40.32%,第二个分量占惯量的 25.20%。这两个变量总共占总惯量的 65.52%。因此,为分析指定 2 个变量可能不够。添加第 3 个分量可将惯量的累积比率增加到 84.51%。
使用列的惯量可确定哪些类别最不常见(假定没有类别变量相关)。对于列的惯量,(1/类别数) 的差值表示最不常见的类别。
列贡献
| 分量 1 | 分量 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | 名称 | 二次 | 质量 | 惯性 | 坐标 | 相关 | 贡献 | 坐标 | 相关 | 贡献 |
| 1 | 小型 | 0.9655 | 0.0424 | 0.2076 | 0.3814 | 0.0297 | 0.0153 | -2.1394 | 0.9357 | 0.7707 |
| 2 | 标准 | 0.9655 | 0.2076 | 0.0424 | -0.0780 | 0.0297 | 0.0031 | 0.4374 | 0.9357 | 0.1576 |
| 3 | 未弹出 | 0.4739 | 0.2134 | 0.0366 | -0.2844 | 0.4717 | 0.0428 | -0.0197 | 0.0023 | 0.0003 |
| 4 | 弹出 | 0.4739 | 0.0366 | 0.2134 | 1.6587 | 0.4717 | 0.2497 | 0.1151 | 0.0023 | 0.0019 |
| 5 | Collis | 0.6133 | 0.1926 | 0.0574 | -0.4264 | 0.6095 | 0.0868 | 0.0338 | 0.0038 | 0.0009 |
| 6 | 翻车 | 0.6133 | 0.0574 | 0.1926 | 1.4294 | 0.6095 | 0.2911 | -0.1133 | 0.0038 | 0.0029 |
| 7 | 不严重 | 0.5680 | 0.1353 | 0.1147 | -0.6523 | 0.5018 | 0.1428 | -0.2371 | 0.0663 | 0.0302 |
| 8 | 严重 | 0.5680 | 0.1147 | 0.1353 | 0.7692 | 0.5018 | 0.1684 | 0.2795 | 0.0663 | 0.0356 |
在“列贡献”表中,标记为“惯量”的列是每个类别贡献的总惯量的比率。因此,“弹出”与其期望值偏差最大,并且贡献总卡方统计量的 21.3%。
比率、累积和直方图
比率指的是每个主分量(轴)解释的总惯量(所有分量解释的惯量)比率。Minitab 会按照从大到小的比率顺序显示这些分量。每个比率都直观地显示在直方图中。
累积比率表示添加分量(轴)时比率的累积和。
解释
使用比率和累积比率可帮助确定解释大多数总惯量的足够分量数。理想情况下,两个或三个分量占总惯量的大部分比率,并且比其他分量更重要。
指示符矩阵分析
| 轴 | 惯量 | 比率 | 累积 | 直方图 |
|---|---|---|---|---|
| 1 | 0.4032 | 0.4032 | 0.4032 | ****************************** |
| 2 | 0.2520 | 0.2520 | 0.6552 | ****************** |
| 3 | 0.1899 | 0.1899 | 0.8451 | ************** |
| 4 | 0.1549 | 0.1549 | 1.0000 | *********** |
| 合计 | 1.0000 |
这些结果显示将总惯量分解成 4 个分量。这 4 个分量解释的总惯量是 1.000。在总惯量中,第一个分量(轴)占惯量的 40.32%,第二个分量占惯量的 25.20%。这两个变量总共占总惯量的 65.52%。因此,为分析指定 2 个分量可能不够。添加第 3 个分量可将惯量的累积比率增加到 84.51%。
Qual
质量 (Qual) 是点与所选维数中原点的平方距离除以与最大维数定义的空间中原点的平方距离所得到的值。Minitab 会计算每个类别的质量值。
解释
使用质量值可以为每个类别确定分量所占的惯量比率。“质量”始终是介于 0 和 1 之间的数字。质量值越大,分量对类别的表示越好。值越小,对类别的表示越差。质量值帮助解释分量。
使用列的贡献值可评估对每个分量的惯量贡献最大的类别。
列贡献
| 分量 1 | 分量 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | 名称 | 二次 | 质量 | 惯性 | 坐标 | 相关 | 贡献 | 坐标 | 相关 | 贡献 |
| 1 | 小型 | 0.9655 | 0.0424 | 0.2076 | 0.3814 | 0.0297 | 0.0153 | -2.1394 | 0.9357 | 0.7707 |
| 2 | 标准 | 0.9655 | 0.2076 | 0.0424 | -0.0780 | 0.0297 | 0.0031 | 0.4374 | 0.9357 | 0.1576 |
| 3 | 未弹出 | 0.4739 | 0.2134 | 0.0366 | -0.2844 | 0.4717 | 0.0428 | -0.0197 | 0.0023 | 0.0003 |
| 4 | 弹出 | 0.4739 | 0.0366 | 0.2134 | 1.6587 | 0.4717 | 0.2497 | 0.1151 | 0.0023 | 0.0019 |
| 5 | Collis | 0.6133 | 0.1926 | 0.0574 | -0.4264 | 0.6095 | 0.0868 | 0.0338 | 0.0038 | 0.0009 |
| 6 | 翻车 | 0.6133 | 0.0574 | 0.1926 | 1.4294 | 0.6095 | 0.2911 | -0.1133 | 0.0038 | 0.0029 |
| 7 | 不严重 | 0.5680 | 0.1353 | 0.1147 | -0.6523 | 0.5018 | 0.1428 | -0.2371 | 0.0663 | 0.0302 |
| 8 | 严重 | 0.5680 | 0.1147 | 0.1353 | 0.7692 | 0.5018 | 0.1684 | 0.2795 | 0.0663 | 0.0356 |
在此项分析中,Minitab 会为与汽车事故相关的数据计算两个主分量。在“列贡献”表中,汽车大小“小型”(0.965) 和“标准”(0.965) 的质量值最高。因此,这两个分量对这两个类别的表示最好。司机弹出的表示最差,其“弹出”和“不弹出”的质量值均为 0.474。“翻转”(0.291) 和 “弹出”(0.250) 对分量 1 的惯量贡献最大。汽车大小“小型”(0.771) 和“标准”(0.158) 对分量 2 的惯量贡献最大。但是,由于两个变量可能不足以解释这些数据的变异性,因此应谨慎解释这些结果。
总量
总量是每个类别的相对频率矩阵的合计。列中所有频率之和除以所有频率之和即可得到列的总量。
解释
使用总量可确定每个列类别的比率。总量值越大,表明列类别的相对频率越高。所有列类别的合计总量等于 1 (100%)。
列贡献
| 分量 1 | 分量 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | 名称 | 二次 | 质量 | 惯性 | 坐标 | 相关 | 贡献 | 坐标 | 相关 | 贡献 |
| 1 | 小型 | 0.9655 | 0.0424 | 0.2076 | 0.3814 | 0.0297 | 0.0153 | -2.1394 | 0.9357 | 0.7707 |
| 2 | 标准 | 0.9655 | 0.2076 | 0.0424 | -0.0780 | 0.0297 | 0.0031 | 0.4374 | 0.9357 | 0.1576 |
| 3 | 未弹出 | 0.4739 | 0.2134 | 0.0366 | -0.2844 | 0.4717 | 0.0428 | -0.0197 | 0.0023 | 0.0003 |
| 4 | 弹出 | 0.4739 | 0.0366 | 0.2134 | 1.6587 | 0.4717 | 0.2497 | 0.1151 | 0.0023 | 0.0019 |
| 5 | Collis | 0.6133 | 0.1926 | 0.0574 | -0.4264 | 0.6095 | 0.0868 | 0.0338 | 0.0038 | 0.0009 |
| 6 | 翻车 | 0.6133 | 0.0574 | 0.1926 | 1.4294 | 0.6095 | 0.2911 | -0.1133 | 0.0038 | 0.0029 |
| 7 | 不严重 | 0.5680 | 0.1353 | 0.1147 | -0.6523 | 0.5018 | 0.1428 | -0.2371 | 0.0663 | 0.0302 |
| 8 | 严重 | 0.5680 | 0.1147 | 0.1353 | 0.7692 | 0.5018 | 0.1684 | 0.2795 | 0.0663 | 0.0356 |
此“列贡献”表评估与汽车事故有关的列类别。“未弹出”类别总量最高 (0.213),占数据的 21.3%。“弹出”类别总量最低 (0.037),占数据的 3.7%。因此,对于这些数据,导致驾驶员弹出的事故相对少见,而不会导致驾驶员弹出的事故更为常见。
坐标
Minitab 会计算每个分量的列主坐标 (Coord)。列主坐标是显示在列图上的坐标。
为了直观地显示列主坐标定义的点,请使用列图。
相关
列相关值表示该分量对列惯量的贡献。相关值范围从 0 到 1。
解释
使用相关值可根据每个分量对惯量的贡献来解释每个分量。如果值接近 1,说明该分量对惯量贡献很大。如果值接近 0,说明该分量对惯量贡献很小。
列贡献
| 分量 1 | 分量 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | 名称 | 二次 | 质量 | 惯性 | 坐标 | 相关 | 贡献 | 坐标 | 相关 | 贡献 |
| 1 | 小型 | 0.9655 | 0.0424 | 0.2076 | 0.3814 | 0.0297 | 0.0153 | -2.1394 | 0.9357 | 0.7707 |
| 2 | 标准 | 0.9655 | 0.2076 | 0.0424 | -0.0780 | 0.0297 | 0.0031 | 0.4374 | 0.9357 | 0.1576 |
| 3 | 未弹出 | 0.4739 | 0.2134 | 0.0366 | -0.2844 | 0.4717 | 0.0428 | -0.0197 | 0.0023 | 0.0003 |
| 4 | 弹出 | 0.4739 | 0.0366 | 0.2134 | 1.6587 | 0.4717 | 0.2497 | 0.1151 | 0.0023 | 0.0019 |
| 5 | Collis | 0.6133 | 0.1926 | 0.0574 | -0.4264 | 0.6095 | 0.0868 | 0.0338 | 0.0038 | 0.0009 |
| 6 | 翻车 | 0.6133 | 0.0574 | 0.1926 | 1.4294 | 0.6095 | 0.2911 | -0.1133 | 0.0038 | 0.0029 |
| 7 | 不严重 | 0.5680 | 0.1353 | 0.1147 | -0.6523 | 0.5018 | 0.1428 | -0.2371 | 0.0663 | 0.0302 |
| 8 | 严重 | 0.5680 | 0.1147 | 0.1353 | 0.7692 | 0.5018 | 0.1684 | 0.2795 | 0.0663 | 0.0356 |
此“列贡献”表评估与汽车事故相关的列分类。分量 1 说明事故类型的大多数惯量(Corr = 0.610,对于“碰撞”和“翻转”),但解释很少的汽车大小惯量(Corr = 0.030,对于“小型”和“标准”)。
贡献
每个列类别对每个分量惯量的贡献 (Contr)。
解释
可使用列类别的贡献值解释分量。
列贡献
| 分量 1 | 分量 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | 名称 | 二次 | 质量 | 惯性 | 坐标 | 相关 | 贡献 | 坐标 | 相关 | 贡献 |
| 1 | 小型 | 0.9655 | 0.0424 | 0.2076 | 0.3814 | 0.0297 | 0.0153 | -2.1394 | 0.9357 | 0.7707 |
| 2 | 标准 | 0.9655 | 0.2076 | 0.0424 | -0.0780 | 0.0297 | 0.0031 | 0.4374 | 0.9357 | 0.1576 |
| 3 | 未弹出 | 0.4739 | 0.2134 | 0.0366 | -0.2844 | 0.4717 | 0.0428 | -0.0197 | 0.0023 | 0.0003 |
| 4 | 弹出 | 0.4739 | 0.0366 | 0.2134 | 1.6587 | 0.4717 | 0.2497 | 0.1151 | 0.0023 | 0.0019 |
| 5 | Collis | 0.6133 | 0.1926 | 0.0574 | -0.4264 | 0.6095 | 0.0868 | 0.0338 | 0.0038 | 0.0009 |
| 6 | 翻车 | 0.6133 | 0.0574 | 0.1926 | 1.4294 | 0.6095 | 0.2911 | -0.1133 | 0.0038 | 0.0029 |
| 7 | 不严重 | 0.5680 | 0.1353 | 0.1147 | -0.6523 | 0.5018 | 0.1428 | -0.2371 | 0.0663 | 0.0302 |
| 8 | 严重 | 0.5680 | 0.1147 | 0.1353 | 0.7692 | 0.5018 | 0.1684 | 0.2795 | 0.0663 | 0.0356 |
此“列贡献”表评估与汽车事故相关的列类别。“弹出”(Contr = 0250) 和“翻转”(Contr = 0.291) 对分量 1 的惯量贡献最大。“小型”(Contr = 0.771) 和“标准”(Contr = 0.158) 汽车大小对分量 2 的惯量贡献最大。
列图
注意
默认情况下,Minitab 针对前两个主分量显示点,前两个主分量占总惯量的最大量。要在图上显示其他主分量(轴),请在执行分析时单击图形并输入分量数。
解释
使用列图可以找出列类别之间的关系,并帮助解释与列类别相关的主分量。点离原点越远,对应的类别影响越大。图上另一侧的点指示某个分量使这些类别值形成对照。
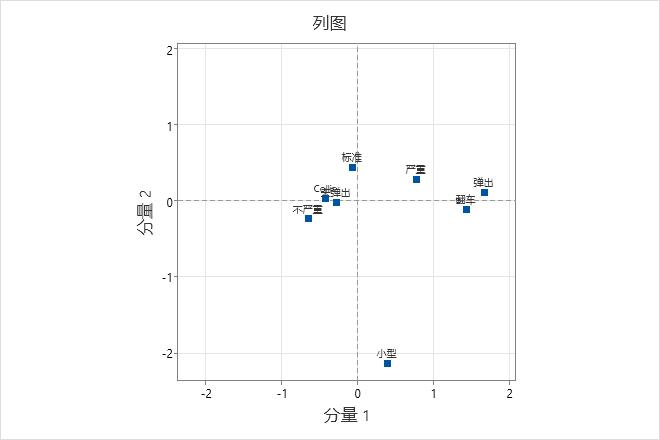
在此列图中,“弹出”和“翻转”与沿着分量 1 的水平轴分布的原点最远。这符合对分量 1 的这些类别的贡献 (Contr) 相对较高这一情况。由于“弹出”和“未弹出”以及“严重”和“不严重”处于原点两端,因此分量 1 使这些类别值形成对照。分量 2 显示在垂直轴上。“小型”汽车大小位于垂直轴一端上远离其他类别的位置。因此,分量 2 使“小型”汽车大小与其他类别形成对照。
指示符表格
指示符表格以指示变量的形式显示您数据中的所有观测值。每个指示变量(列)代表类别变量的一个水平,每个观测值(行)则根据它属于 (1) 或不属于 (0) 该类别而取一个二进制值。因此,所有列中的值必须是 0 或 1。
要在结果中包括指示符表格,必须单击结果并在执行分析时选择显示该表格的选项。
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C8 |
|---|---|---|---|---|---|---|---|---|
| 男 | 女 | 正常体重 | 体重不足 | 超重 | 吸烟 | 不吸烟 | 活动 | 无活动 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
Burt 表
Burt 表是一种用于帮助显示并分析类别变量之间关系的对称图。要在结果中包括指示符表,必须单击结果并在执行分析时选择显示该表的选项。
| 男 | 女 | 轻微 | 中 | 高 | <20 | 20-50 | >50 | |
|---|---|---|---|---|---|---|---|---|
| 男 | 87 | 0 | 33 | 45 | 9 | 26 | 47 | 14 |
| 女 | 0 | 163 | 27 | 111 | 25 | 43 | 89 | 31 |
| 轻微 | 33 | 27 | 60 | 0 | 0 | 14 | 48 | 7 |
| 中等 | 45 | 111 | 0 | 111 | 0 | 14 | 107 | 18 |
| 高 | 9 | 25 | 0 | 0 | 79 | 9 | 30 | 3 |
| <20 | 26 | 43 | 14 | 14 | 9 | 37 | 0 | 0 |
| 20-50 | 47 | 89 | 48 | 107 | 30 | 0 | 185 | 0 |
| >50 | 14 | 31 | 7 | 18 | 3 | 0 | 0 | 28 |
Burt 表中的每个条目显示了满足对应行和列中的类别的观测值个数。例如,行 1 和列 3 中的条目表示男性与轻微活动组合的观测值个数 (33)。行 1 和列 2 中的条目表示男性和女性组合的观测值个数 (0)。
您可以在从左上至右下的对角线条目中确定每个类别的观测值总数,其中每个条目都具有相同的行标题、列标题。例如,行 1 和列 1 中的条目显示了男性总数 (87),行 2 和列 2 中的条目显示了女性总数 (163),以此类推。