请在模型汇总表中查找每个统计量的定义和解释指导。
S
S 表示数据值和拟合值之间距离的标准偏差。S 以响应单位进行度量。
解释
使用 S 可评估模型描述响应值的程度。S 以响应变量的单位进行度量,它表示数据值与拟合值的距离。S 值越低,模型描述响应的程度越高。但是,自身低 S 值并不表明模型符合模型假设。您应检查残差图来验证假设。
例如,您效力一家薯片公司,该公司正在检查影响每个包装内碎薯片百分比的因子。 将模型简化为显著的预测变量,S 的计算结果为 1.79。此结果表明拟合值附近的数据点的标准差为 1.79。如果您在比较模型,则低于 1.79 的值表明拟合较优,值较高则表明拟合较差。
R-sq
R2 是由模型解释的响应中的变异百分比。它由 1 减去误差平方和(未由模型解释的变异)与平方总和(数据的总变异)之比计算得出。
解释
以下拟合线图说明了不同的 R2 值。第一个图说明了解释响应中 85.5% 变异的简单回归模型。第二个图说明了解释响应中 22.6% 变异的模型。模型解释的变异越多,数据点距离拟合回归线越近。从理论上讲,如果模型可以解释 100% 的变异,则拟合值将始终等于观测值,并且所有数据点都将落于拟合线上。但是,即便 R2 为 100%,模型也不需要准确地预测新观测值。
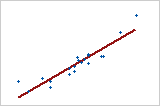
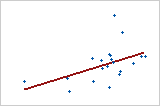
当解释 R2 值时,请考虑以下问题:
- 如果向模型添加更多预测变量,则 R2 会始终增加。例如,最佳的 5 预测变量模型的 R2 始终比最佳的 4 预测变量模型的高。因此,比较相同大小的模型时 R2 最有效。
- 样本数量较小则不能提供对于响应变量和预测变量之间关系强度的精确估计。如果需要 R2 更为精确,则应当使用较大的样本(通常为 40 或更多)。
- R2 只是模型拟合数据优度的一种度量。即使模型具有高 R2,您也应当检查残差图,以验证模型是否符合模型假设。
R-Sq(调整)
调整的 R2 是由模型解释的响应中变异的百分比,相对于观测值个数,已调整了模型中的预测变量数。调整的 R2 是用 1 减去均方误 (MSE) 和均方总和 (MS Total) 之比计算得出。
解释
在想要比较具有不同数量的预测变量的情况下,使用调整的 R2。如果向模型添加预测变量,即使模型没有实际改善,R2 也会始终增加。调整的 R2 值包含模型中的预测变量数,以便帮助您选择正确的模型。
例如,您效力一家薯片公司,该公司正在检查影响每个包装内碎薯片百分比的因子。当您以向前逐步方式添加预测变量时,将得到以下所述结果。
| 模型 | 马铃薯百分比 | 冷却速度 | 加工温度 | R2 | 调整的 R2 |
|---|---|---|---|---|---|
| 1 | X | 52% | 51% | ||
| 2 | X | X | 63% | 62% | |
| 3 | X | X | X | 65% | 62% |
第一个模型会生成超过 50% 的 R2。第二个模型会为自身增加冷却速率。调整的 R2 增加,这表明冷却速率会改善模型。提高了加工温度的第三个模型会增加 R2,但不会增加调整的 R2。这些结果表明,加工温度不会改善模型。基于这些结果,您可以考虑从模型中删除加工温度。