步骤 1:确定哪些项对响应具有最大效应
使用 Pareto 标准化效应图可比较主效应、平方效应和交互作用效应的相对量值与统计显著性。
Minitab 按照标准化效应绝对值的递减顺序绘制效应图。 图中的参考线表明哪些效应是显著效应。 默认情况下,Minitab 使用显著性水平 .05 绘制参考线。
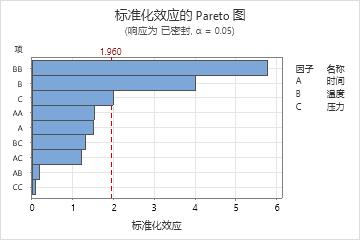
主要结果:Pareto 图
在这些结果中,温度 (BB) 的平方项以及温度 (B) 和压力 (C) 的主效应在显著性水平 α 为 0.05 时显著。
此外,还可以发现最大的效应是温度*温度 (BB),因为它延伸得最远。最小的效应是压力*压力 (CC),因为它延伸得最近。
步骤 2:确定哪些项对响应具有统计意义显著的效应
要确定响应与模型中每个项之间的关联在统计意义上是否显著,请将该项的 P 值与显著性水平进行比较以评估原假设。原假设声明该项的系数等于零,这意味着该项与响应之间没有关联。通常,显著性水平(用 α 或 alpha 表示)为 0.05 即可。显著性水平 0.05 指示在实际上不存在关联时得出存在关联的风险为 5%。
- P 值 ≤ α:关联在统计意义上显著
- 如果 P 值小于或等于显著性水平,则可以得出响应变量与项之间的关联在统计意义上显著的结论。
- P 值 > α:关联在统计意义上不显著
- 如果 p 值大于显著性水平,则无法得出响应变量与该项之间的关联在统计意义上显著的结论。您可能希望重新拟合没有该项的模型。
- 如果因子的系数显著,则可以断定并非所有因子水平都具有相同的事件概率。
- 如果一个平方项的系数在统计意义上显著,则可以得出结论:因子与响应之间的关系沿着曲线分布。
- 如果一个交互作用项的系数显著,则因子与响应之间的关系取决于该项中的其他因子。在这种情况下,不应在不考虑交互作用效应时解释主效应。
- 如果区组的系数在统计意义上显著,则可以断定区组的链接函数与平均值不同。
已编码系数
| 项 | 系数 | 系数标准误 | 方差膨胀因子 |
|---|---|---|---|
| 常量 | 3.021 | 0.384 | |
| 时间 | 0.210 | 0.139 | 18.53 |
| 温度 | 0.641 | 0.159 | 19.53 |
| 压力 | 0.420 | 0.211 | 70.48 |
| 时间*时间 | -0.0735 | 0.0482 | 1.01 |
| 温度*温度 | 0.2988 | 0.0517 | 1.17 |
| 压力*压力 | -0.0022 | 0.0277 | 70.24 |
| 时间*温度 | -0.0092 | 0.0505 | 1.14 |
| 时间*压力 | 0.0417 | 0.0342 | 18.12 |
| 温度*压力 | -0.0521 | 0.0396 | 19.24 |
主要结果:系数
在这些结果中,时间、温度和压力的主效应的系数为正数。时间 * 时间的平方项的系数为负数。一般而言,在项的值增大时,正系数会使事件发生的可能性变大,负系数会使事件发生的可能性变小。
方差分析
| 来源 | 自由度 | 调整后偏差 | 调整后均值 | 卡方 | P 值 |
|---|---|---|---|---|---|
| 模型 | 9 | 903.478 | 100.386 | 903.48 | 0.000 |
| 时间 | 1 | 2.303 | 2.303 | 2.30 | 0.129 |
| 温度 | 1 | 16.388 | 16.388 | 16.39 | 0.000 |
| 压力 | 1 | 3.966 | 3.966 | 3.97 | 0.046 |
| 时间*时间 | 1 | 2.331 | 2.331 | 2.33 | 0.127 |
| 温度*温度 | 1 | 34.012 | 34.012 | 34.01 | 0.000 |
| 压力*压力 | 1 | 0.006 | 0.006 | 0.01 | 0.937 |
| 时间*温度 | 1 | 0.033 | 0.033 | 0.03 | 0.856 |
| 时间*压力 | 1 | 1.490 | 1.490 | 1.49 | 0.222 |
| 温度*压力 | 1 | 1.731 | 1.731 | 1.73 | 0.188 |
| 误差 | 5 | 23.404 | 4.681 | ||
| 合计 | 14 | 926.882 |
主要结果:P 值
在这些结果中,在 α = 0.05 的显著性水平下,温度 * 温度的平方项以及温度和压力的主效应显著。
步骤 3:了解预测变量的效应
- 连续预测变量的优势比
-
优势比大于 1 表示在预测变量越大,事件发生的几率越大。优势比小于 1 表示预测变量越大,事件发生的几率越小。
连续预测变量的优势比
变更单位 优势比 95% 置信区间 剂量(毫克) 0.5 6.1279 (1.7218, 21.8087) 主要结果:优势比
在这些结果中,该模型使用药物的剂量水平来预测成人体内是否存在细菌。每颗药的剂量为 0.5 毫克,因此研究人员使用 .5 作为一个单位变化。优势比约为 6。成人每额外服用一颗药,患者不感染细菌的几率大约会增加 6 倍。
- 类别预测变量的优势比
-
对于类别预测变量,优势比可以比较事件在两个不同的预测变量水平发生的几率。Minitab 通过在水平 A 和水平 B 这两列中列出水平来设置比较。水平 B 是因子的参考水平。优势比大于 1 表示事件在水平 A 下发生的几率大。优势比小于 1 表示事件在水平 A 下发生的几率小。有关类别预测变量编码的更多信息,请转到类别预测变量的编码方案。
类别预测变量的优势比
水平 A 水平 B 优势比 95% 置信区间 月份 2 1 1.1250 (0.0600, 21.0834) 3 1 3.3750 (0.2897, 39.3165) 4 1 7.7143 (0.7461, 79.7592) 5 1 2.2500 (0.1107, 45.7172) 6 1 6.0000 (0.5322, 67.6397) 3 2 3.0000 (0.2547, 35.3325) 4 2 6.8571 (0.6556, 71.7169) 5 2 2.0000 (0.0976, 41.0019) 6 2 5.3333 (0.4679, 60.7946) 4 3 2.2857 (0.4103, 12.7323) 5 3 0.6667 (0.0514, 8.6389) 6 3 1.7778 (0.2842, 11.1200) 5 4 0.2917 (0.0252, 3.3719) 6 4 0.7778 (0.1464, 4.1326) 6 5 2.6667 (0.2124, 33.4861) 主要结果:优势比
在这些结果中,类别预测变量是距离酒店旺季开始时间的月数。响应是客户是否取消预定。在该示例中,取消是事件。当水平 A 为第 4 个月,水平 B 为第 1 个月时,最大的优势比大约为 8。这表示客户在第 4 个月取消预定房间的几率约为客户在第 1 个月取消预定房间的几率的 8 倍。
步骤 4:确定模型对数据的拟合优度
注意
数据在工作表中的排列方式以及每行是存在一个还是多个试验会影响很多模型汇总和拟合优度统计量。Hosmer-Lemeshow 检验不会受数据排列方式影响,并且无论每行是存在一个还是多个试验都可进行比较。有关更多信息,请转到数据格式对二元 Logistic 回归中拟合优度的影响。
- 偏差 R-Sq
-
偏差 R2 越高,模型拟合数据的优度越高。偏差 R2 始终在 0% 和 100%之间。
在向模型添加其他项时,偏差 R2 会始终增大。例如,最佳的 5 项模型的 R2 始终比最佳的 4 项模型的高(至少一样高)。因此,比较相同大小的模型时,偏差 R2 最有效。
数据排列会影响偏差 R2 值。每行有多个试验的数据通常比每行只有一个试验的数据具有更高的偏差 R2。偏差 R2 值仅在使用相同数据格式的模型之间可比较。
拟合优度统计量只是模型拟合数据优度的一种度量。即使模型具有合意的值,您也应当检查残差图和拟合优度检验,以评估模型拟合数据的优度。
- 偏差 R-sq (adj)
-
使用调整的偏差 R2 可比较具有不同项数量的模型。向模型添加项时,偏差 R2 会始终增大。调整的偏差 R2 值在模型中包含了项数,以帮助您选择正确的模型。
- AIC、AICc 和 BIC
-
使用 AIC、AICc 和 BIC 比较不同的模型。对于各统计量,值越小越合意。但是,对于预测变量集具有最小值的模型,不一定需要很准确地拟合数据。而且,还可使用拟合优度检验和残差图评估模型与数据的拟合优度。
模型汇总
| 偏差 R-Sq | 偏差 R-Sq (调整) | AIC | AICc | BIC |
|---|---|---|---|---|
| 97.95% | 76.75% | 105.98 | 171.98 | 114.48 |
主要结果:偏差 R-Sq、偏差 R-Sq (adj)、AIC
在这些结果中,模型可以解释响应变量中 97.95% 的偏差。对于这些数据,偏差 R2 值表示模型与数据充分拟合。如果要拟合具有不同预测变量的其他模型,请使用调整的偏差 R2 值、AIC 值、AICc 值和 BIC 值比较模型对数据的拟合优度。
步骤 5:确定模型是否无法与数据拟合
- 不正确的链接函数
- 忽略了模型中变量的高阶项
- 忽略了模型中不存在的预测变量
- 过度离散
如果偏离在统计上显著,则您可以尝试另一种链接函数或更改模型中的项。
- 偏差:与每行多个试验的数据相比,每行排列单个试验的数据的偏差检验 p 值往往较小,每行的试验数越少, p 值通常越小。对于每行单个试验的数据,Hosmer-Lemeshow 结果更可靠。
- Pearson:如果数据中每行事件的预计数量较小,则 Pearson 检验使用的卡方分布近似不准确。因此,如果数据为每行一个试验的格式,则 Pearson 拟合优度检验也不准确。
- Hosmer-Lemeshow:Hosmer-Lemeshow 检验不像其他拟合优度检验那样依赖于数据中每行的试验数。当数据中每行的试验数很少时,Hosmer-Lemeshow 检验能够更可靠地指出模型对数据的拟合优度。
响应信息
| 变量 | 值 | 计数 | 事件名称 |
|---|---|---|---|
| 腐败 | 事件 | 506 | Event |
| 非事件 | 7482 | ||
| 容器 | 合计 | 7988 |
拟合优度检验
| 检验 | 自由度 | 卡方 | P 值 |
|---|---|---|---|
| 偏差 | 5 | 0.97 | 0.965 |
| Pearson | 5 | 0.97 | 0.965 |
| Hosmer-Lemeshow | 6 | 0.10 | 1.000 |
事件/试验格式的主要结果:响应信息、偏差检验、Pearson 检验、Hosmer-Lemeshow 检验
在这些结果中,所有拟合优度检验的 P 值都大于常见显著性水平 ..05。这些检验无法提供预测概率以二项分布无法预测的方式偏离观测概率的证据。