观测到的概率
观测到的概率等于事件数除以试验数。例如,当事件数为 30,试验数为 495 时,观测到的概率为 0.06061。
拟合值
拟合值又称为事件概率或预测概率。事件概率是制定事件的发生机会。事件概率估计事件发生的可能性,如在牌桌上抽到一张 A,或制造不一致的部件。 事件概率的范围从 0(不可能)到 1(必然)。
解释
试验响应只有两个可能值,如存在或不存在特定疾病。 事件概率是给定因子或协变量模式的响应为 1 或发生某一事件的可能性(例如,50 岁以上的妇女患上二型糖尿病的可能性)。
试验中的每个性能都称为一次试验。例如,如果投掷硬币 10 次,并记录了印有头像那面朝上的次数,则您执行了 10 次试验。如果试验是独立的而且可能性相等,则可以通过将事件数量除以试验总数来估计事件概率。例如,如果在 10 次硬币投掷中有 6 次印有头像那面朝上,则估计的事件概率(印有头像那面朝上的投掷)为:
事件数 ÷ 试验数 = 6 ÷ 10 = .6
拟合值 SE
拟合值标准误(拟合值 SE)用于估计指定变量设置的事件概率中的变异。 将使用拟合值标准误来计算事件概率的置信区间。 标准误始终为非负值。
解释
使用拟合值标准误可度量时间概率估计值的精确度。 标准误越小,预测平均响应越精确。
例如,研究人员在医疗研究中研究会影响包含的因子。对于一组因子,患者有资格包含在新治疗研究中的概率为 0.63,标准误为 0.05。对于第二组因子设置,概率相同,但是,拟合标准误为 0.03。该分析人员可以更加确信:第二组变量设置的事件设置接近 0.6 。
拟合值的置信区间(95% 置信区间)
这些置信区间 (CI) 是值的极差,可能包含总体(具有模型中预测变量的观测值)的事件概率。
由于样本的随机性,来自总体的两个样本不可能生成相同的置信区间。但是如果将样本重复许多次,则所获得的特定百分比的置信区间会包含未知的总体参数。这些包含参数的置信区间的百分比是区间的置信水平。
- 点估计值
- 点估计是从样本数据计算得到的参数的估计值。
- 边际误差
- 边际误差定义了置信区间的宽度,它受到事件概率范围、样本数量和置信水平的影响。
解释
使用置信区间可以为变量的实测值评估拟合值的估计值。
例如,对于 95% 置信区间,置信区间包含模型中指定变量值的事件概率的可信度为 95%。置信区间有助于评估结果的实际意义。使用您的专业知识可以确定置信区间是否包括对您的情形有实际意义的值。如果区间因太宽而毫无用处,请考虑增加样本数量。
残差
残差是模型对观测值的预测优度的度量标准。默认情况下,Minitab 将计算残差偏差。模型未良好拟合的观测值的偏差量残差和 Pearson 残差较高。Minitab 将针对每个可区分因子/协变量模式计算残差。
无论是使用残差偏差还是 Pearson 残差,这些残差图的解释都相同。当模型使用 Logit 链接函数时,残差偏差分布更接近于最小二乘回归模型中的残差分布。随着每个预测变量设置组合的试验数增加,残差偏差和 Pearson 残差会更相似。
解释
绘制残差图可确定模型是否适用且符合回归的假设。检查残差可以提供有关模型对数据的拟合优度的有用信息。一般而言,残差应当是随机分布的,而且没有明显的模式和异常值。如果 Minitab 确定数据包含异常观测值,则会在输出的“异常观测值的拟合与诊断”表中确定这些观测值。有关异常值的更多信息,请转到异常观测值。
标准化残差
标准化残差等于残差值 (ei) 除以其标准差的估计值。
解释
使用标准化残差帮助您检测异常值。大于 2 和小于 −2 的标准化残差通常被视为较大值。“异常观测值的拟合与诊断”表使用“R”来标识这些观测值。如果分析表明有许多异常观测值,那么模型通常会出现严重的失拟。也就是说,该模型不能充分说明因子与响应变量之间的关系。有关更多信息,请转到异常观测值。
标准化残差很有用,因为原始残差可能不是良好的异常值指示符。每个原始残差的变异因与其关联的 X 值而异。尺度不同使其难以评估原始残差的大小。标准化残差可以通过将不同的变异转换为公共尺度来解决此问题。
无论是使用残差偏差还是 Pearson 残差,这些残差图的解释都相同。当模型使用 Logit 链接函数时,残差偏差分布更接近于最小二乘回归模型中的残差分布。随着每个预测变量设置组合的试验数增加,残差偏差和 Pearson 残差会更相似。
删后残差
每个 t 化删后残差采用相当于从数据集中系统地删除每个观测值、估计回归方程,然后确定模型对已删除观测值的预测优度的公式来计算。每个 t 化删后残差还通过将观测值的删后残差除以其标准差的估计值来实现标准化。删除观测值是为了确定没有此观测值时模型的行为。如果观测值的 t 化删后残差较大(如果其绝对值大于 2),则它可能是数据中的异常值。
解释
使用 t 化删后残差可删除异常值。删除每个观测值是为了确定当模型拟合过程中不包含观测值时,模型预测响应的优度。大于 2 或小于 −2 的 t 化删后残差通常被视为较大值。Minitab 标记的观测值未能很好地遵循建议的回归方程。但是,预计您将得到一些异常观测值。例如,基于较大残差的标准,因为具有较大的残差,预计将大致标记 5% 的观测值。如果分析表明存在多个异常观测值,则模型可能无法充分说明预测变量与响应变量之间的关系。有关更多信息,请转到异常观测值。
标准化残差和删后残差与原始残差相比,在确定异常值方面可能更为有用。它们会根据不同的预测变量值或因子,调整原始残差的方差中可能的差值。
Hi(杠杆率)
Hi 也称为杠杆率,用于度量某个观测值的 x 值与数据集中所有观测值的 x 值的平均值之间的距离。
解释
Hi 值介于 0 和 1 之间。Minitab 会在异常观测值表的拟合值与诊断中用 X 标识杠杆率值大于 3p/n 或 0.99(以较小者为准)的观测值。在 3p/n 中,p 是模型中的系数个数,n 是观测值个数。Minitab 使用“X”标记的观测值可能是有影响的观测值。
有影响的观测值对模型具有不成比例的影响,会产生误导性结果。例如,包含或不包含有影响的点可能会改变系数是否统计意义显著。有影响的观测值可以是杠杆率点、异常值或这两者。
如果看到有影响的观测值,请首先确定该观测值是否是数据输入或测量错误。如果观测值既不是数据输入错误又不是测量错误,请确定观测值所造成的影响。首先,拟合带观测值和不带观测值的模型。然后,比较系数、p 值、R2 和其他模型信息。如果在排除有影响的观测值后模型有显著变化,请进一步检查模型,确定在模型中是否指定了错误内容。您可能需要收集更多数据以解决此问题。
Cook 距离 (D)
Cook 距离 (D) 度量观测值对于线性模型中系数集的效应。Cook 距离会同时考虑每个观测值的杠杆率值和标准化残差,以便确定观测值的效应。
解释
具有较大 D 值的观测值可能被视为有影响的观测值。较大 D 值的常用标准为 D 大于 F 分布的中位数:F(0.5, p, n-p),其中 p 是模型项数(包括常量),n 是观测值个数。另一种检验 D 值的方法是使用图形(如单值图)将它们与另一个值相比较。相对于其他观测值,具有较大 D 值的观测值可能是有影响的观测值。
有影响的观测值对模型具有不成比例的影响,会产生误导性结果。例如,包含或不包含有影响的点可能会改变系数是否在统计意义上显著。有影响的观测值可以是杠杆率点、异常值或这两者。
如果看到有影响的观测值,请确定该观测值是否存在数据输入或测量错误。如果该观测值既不存在数据输入错误又不存在测量错误,请确定它会造成何种影响。首先,拟合带该观测值的模型和不带该观测值的模型。然后,比较系数、p 值、R2 和其他模型信息。如果在排除有影响的观测值后模型有显著变化,请进一步检查模型,确定在模型中是否指定了错误内容。您可能需要收集更多数据以解决此问题。
DFITS
DFITS 测量每个观测值对于线性模型中拟合值的效应。DFITS 大致表示从数据集中删除每个观测值并重新拟合模型时,拟合值改变的标准差的数量。
解释
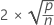
| 项 | 说明 |
|---|---|
| p | 模型项的数量 |
| n | 观测值个数 |
如果看到有影响的观测值,请确定该观测值是否存在数据输入或测量错误。如果该观测值既不存在数据输入错误又不存在测量错误,请确定它会造成何种影响。首先,拟合带该观测值的模型和不带该观测值的模型。然后,比较系数、p 值、R2 和其他模型信息。如果在排除有影响的观测值后模型有显著变化,请进一步检查模型,确定在模型中是否指定了错误内容。您可能需要收集更多数据以解决此问题。