估计法
您可以选择限制的极大似然(REML)或极大似然(ML)。通常,您使用限制的极大似然(REML),因为限制极大似然的方差分量估计量大致是无偏的,而极大似然估计量是偏倚的。但是,样本数量越大,偏倚越小。
如果需要检验具有一些固定效应项的嵌套模型与具有更多固定效应项的相应参考模型是否等效,前提为两种模型都具有相同的随机项数和误差方差结构,则使用极大似然(ML)。具体来说,设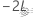 为全模型中的负 2 对数似然,并且设
为全模型中的负 2 对数似然,并且设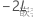 为较小模型的负 2 对数似然。
为较小模型的负 2 对数似然。
在原假设下,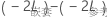 服从渐近卡方分布,其中自由度等于参考模型和嵌套模型之间的固定效应项参数个数的差值。您可以使用似然比检验来评估是否可以从参考模型中删除一部分固定效应项。
服从渐近卡方分布,其中自由度等于参考模型和嵌套模型之间的固定效应项参数个数的差值。您可以使用似然比检验来评估是否可以从参考模型中删除一部分固定效应项。
有关混合效应模型中固定参数的似然比检验的更多信息,请参见 B. T. West, K.B. Welch, 和 A.T. Gałecki (2007)。Linear Mixed Models: A Practical Guide Using Statistical Software(线性混合模型:使用统计软件的实用指南),第一版。Chapman and Hall/CRC(第 34 至 36 期)。
固定效应检验方法
通常,您使用Kenward-Roger 近似,因为这些计算包括会降低小样本数量偏倚的调整。您也可以使用Satterthwaite 近似。通常,样本数量越大,两种方法之间的差异越小。
权重
在权重中,为所有响应值输入权重数字列。如果响应值内的随机误差方差不是常量,则使用权重。相反地,对于每个响应值,方差等于相应权重乘以常量后的相反数。
权重必须大于或等于零。权重列的行数必须与响应列的行数相同。
所有区间的置信水平
为输出中的所有置信区间输入置信水平。
通常,置信水平为 95% 即可。95% 置信水平表明,如果从总体中为相关参数随机抽取 100 个样本,则大约 95 个样本的置信区间中将包含该未知系数的实际值。对于给定的数据集,置信水平越低,生成的区间越窄;置信水平越高,生成的区间越宽。
注意
要显示置信区间,必须转到结果子对话框,然后从结果显示中,选择扩展表。
置信区间的类型
您可以选择双侧区间或单侧边界。对于相同的置信水平,边界比区间更接近于点估计值。上限不提供可能的下限值。下限不提供可能的上限值。
- 双侧
-
- 使用双侧置信区间可估计相关参数可能的上限值和下限值。
- 下限
-
- 使用置信下限可估计相关参数可能的下限值。
- 上限
-
- 使用置信上限可估计相关参数可能的上限值。
均值
您可以在输出中显示模型中的主效应、双因子交互作用项或所有项的拟合均值。或者,您可以显示其中一部分项的均值,或不显示任何项的均值。
如果您选择指定的项,请将I = 计算项的均值用于项按钮以识别项。选择列表中的项,然后按该按钮。I 表示将显示项的均值。如果您期望在列表中看到的项未显示,您需要将其添加到模型中。