步骤 1:检验所有响应的等均值
- P 值 ≤ α:均值之间的差值在统计意义上显著
- 如果 p 值小于或等于显著性水平,则可以得出均值的差值在统计意义上显著的结论。
- P 值 > α:均值之间的差值在统计意义上不显著
- 如果 p 值大于显著性水平,则无法得出均值的差值在统计意义上显著的结论。您可能希望重新拟合没有该项的模型。
- 如果一个主效应显著,则在模型的所有响应中,该因子的水平均值之间存在显著差异。
- 如果交互作用项的效应显著,那么每个因子的效应在模型内所有响应中的其他因子的不同水平下有所不同。因此,没有必要分析显著高次交互作用中所包含项的单个效应。
方法 的多元方差分析检验
| 自由度 | |||||
|---|---|---|---|---|---|
| 标准 | 检验统计量 | F | 分子 | 分母 | P |
| Wilks' | 0.63099 | 16.082 | 2 | 55 | 0.000 |
| Lawley-Hotelling | 0.58482 | 16.082 | 2 | 55 | 0.000 |
| Pillai's | 0.36901 | 16.082 | 2 | 55 | 0.000 |
| Roy's | 0.58482 | ||||
工厂 的多元方差分析检验
| 自由度 | |||||
|---|---|---|---|---|---|
| 标准 | 检验统计量 | F | 分子 | 分母 | P |
| Wilks' | 0.89178 | 1.621 | 4 | 110 | 0.174 |
| Lawley-Hotelling | 0.11972 | 1.616 | 4 | 108 | 0.175 |
| Pillai's | 0.10967 | 1.625 | 4 | 112 | 0.173 |
| Roy's | 0.10400 | ||||
方法*工厂 的多元方差分析检验
| 自由度 | |||||
|---|---|---|---|---|---|
| 标准 | 检验统计量 | F | 分子 | 分母 | P |
| Wilks' | 0.85826 | 2.184 | 4 | 110 | 0.075 |
| Lawley-Hotelling | 0.16439 | 2.219 | 4 | 108 | 0.072 |
| Pillai's | 0.14239 | 2.146 | 4 | 112 | 0.080 |
| Roy's | 0.15966 | ||||
主要结果:P
当显著性水平为 0.10 时,生产方法的 p 值在统计意义上显著。对于任何检验来说,当显著性水平为 0.10 时,制造厂的 p 值并不显著。当显著性水平为 0.10 时,工厂和方法之间交互作用的 p 值在统计意义上显著。由于交互作用在统计意义上显著,因此该方法的效应取决于工厂。
步骤 2:确定每个因子的哪种响应均值具有最大差值
使用特征分析来评估响应均值在不同模型项水平之间如何不同。您应重点关注与高特征值相对应的特征向量。要显示特征分析,请转到并选择特征分析下的结果显示。
方法 的特征分析
| 特征值 | 0.5848 | 0.00000 |
|---|---|---|
| 比率 | 1.0000 | 0.00000 |
| 累积 | 1.0000 | 1.00000 |
| 特征向量 | 1 | 2 |
|---|---|---|
| 可用性评级 | 0.144062 | -0.07870 |
| 质量评级 | -0.003968 | 0.13976 |
主要结果:特征值,特征向量
在这些结果中,方法的第一个特征值 (0.5848) 大于第二个特征值 (0.00000)。因此,您应更重视第一个特征向量。方法的第一个特征值为 0.144062,-0.003968。此向量中的最高绝对值用于可用性评级。这表明,可用性均值具有方法因子水平之间的最大差值。此信息对于评估均值表十分有用。
步骤 3:评估组均值之间的差值
使用“均值”表可理解数据中因子水平之间的统计显著性差异。每组的均值都提供了每个总体均值的估计值。请查找统计意义显著的项组均值之间的差异。
对于主效应,该表显示每个因子内的组及其均值。对于交互作用项效应,该表显示组的所有可能的组合。如果交互作用项在统计意义上显著,则在不考虑交互作用效应的情况下,不解释主效应。
要显示均值,请转到,选择单变量方差分析,并在显示与项对应的最小二乘均值中输入项。
响应的最小二乘均值
| 可用性评级 | 质量评级 | |||
|---|---|---|---|---|
| 均值 | 均值标准误 | 均值 | 均值标准误 | |
| 方法 | ||||
| 方法 1 | 4.819 | 0.165 | 5.242 | 0.193 |
| 方法 2 | 6.212 | 0.179 | 6.026 | 0.211 |
| 工厂 | ||||
| 工厂 A | 5.708 | 0.192 | 5.833 | 0.226 |
| 工厂 B | 5.493 | 0.232 | 5.914 | 0.273 |
| 工厂 C | 5.345 | 0.206 | 5.155 | 0.242 |
| 方法*工厂 | ||||
| 方法 1 工厂 A | 4.667 | 0.272 | 5.417 | 0.319 |
| 方法 1 工厂 B | 4.700 | 0.298 | 5.400 | 0.350 |
| 方法 1 工厂 C | 5.091 | 0.284 | 4.909 | 0.334 |
| 方法 2 工厂 A | 6.750 | 0.272 | 6.250 | 0.319 |
| 方法 2 工厂 B | 6.286 | 0.356 | 6.429 | 0.418 |
| 方法 2 工厂 C | 5.600 | 0.298 | 5.400 | 0.350 |
主要结果:均值
在这些结果中,均值表显示均值可用性和质量评分如何根据方法、设备以及方法*设备交互作用项而变化。方法和交互作用项在 0.10 水平时统计意义显著。该表显示方法 1 和方法 2 分别与均值可用性评分 4.819 和 6.212 相关。这些均值之间的差值大于质量评分的相应均值之间的差值。这确认了特征值分析的解释。
但是,因为方法*设备交互作用项的统计意义也显著,所以不考虑交互作用效应就无法解释主效应。例如,交互作用项表显示,使用方法 1,设备 C 与最高可用性评分和最低质量评分相关。但是,使用方法 2,设备 A 与最高可用性评分和约等于最高质量评分的质量评分相关。
步骤 4:评估单变量结果以检查单个响应值
执行一般多元方差分析时,您可以选择计算单变量统计量来检查单个响应。单变量结果有利于更直观地理解数据关系。但是,单变量结果可能不同于多变量结果。
要显示单变量结果,请转到并在结果显示下选择单变量方差分析。
- P 值 ≤ α:关联在统计意义上显著
- 如果 P 值小于或等于显著性水平,则可以得出响应变量与项之间的关联在统计意义上显著的结论。
- P 值 > α:关联在统计意义上不显著
- 如果 p 值大于显著性水平,则无法得出响应变量与该项之间的关联在统计意义上显著的结论。您可能希望重新拟合没有该项的模型。
- 如果一个类别因子显著,则可以得出并非所有水平均值都相等的结论。
- 如果一个交互作用项显著,则因子与响应之间的关系取决于该项中的其他因子。在这种情况下,不应在不考虑交互作用效应时解释主效应。
- 如果一个协变量在统计意义上显著,则可以得出结论:该协变量的值的变化与平均响应值的变化相关联。
- 如果一个多项式项显著,则可以得出数据包含弯曲的结论。
可用性评级 的方差分析,在检验中使用调整的 SS
| 来源 | 自由度 | Seq SS | Adj SS | Adj MS | F | P |
|---|---|---|---|---|---|---|
| 方法 | 1 | 31.264 | 29.074 | 29.0738 | 32.72 | 0.000 |
| 工厂 | 2 | 1.366 | 1.499 | 0.7495 | 0.84 | 0.436 |
| 方法*工厂 | 2 | 7.099 | 7.099 | 3.5494 | 3.99 | 0.024 |
| 误差 | 56 | 49.754 | 49.754 | 0.8885 | ||
| 合计 | 61 | 89.484 |
质量评级 的方差分析,在检验中使用调整的 SS
| 来源 | 自由度 | Seq SS | Adj SS | Adj MS | F | P |
|---|---|---|---|---|---|---|
| 方法 | 1 | 8.8587 | 9.2196 | 9.2196 | 7.53 | 0.008 |
| 工厂 | 2 | 6.7632 | 7.0572 | 3.5286 | 2.88 | 0.064 |
| 方法*工厂 | 2 | 0.7074 | 0.7074 | 0.3537 | 0.29 | 0.750 |
| 误差 | 56 | 68.5900 | 68.5900 | 1.2248 | ||
| 合计 | 61 | 84.9194 |
主要结果:P
在这些结果中,在用于对可用性评级的模型中,方法主效应和方法*设备交互作用项效应的 p 值在水平为 0.10 时统计意义上显著。在用于对质量进行评级的模型中,方法和设备的主效应在统计意义上均显著。您可推断出这些变量的变化是与响应变量的变化相关的。
步骤 5:确定模型是否符合分析的假设条件
使用残差图可帮助您确定模型是否适用并符合分析的假设。如果不符合此假设,则模型可能无法充分拟合数据,在解释结果时应当格外小心。
执行一般多元方差分析时,Minitab 会显示模型中的所有响应变量残差图。您必须确定所有响应变量的残差图是否表示模型符合假设。
有关如何处理残差图模式的更多信息,请转到一般多元方差分析的残差图,然后单击页面顶部列表中残差图的名称。
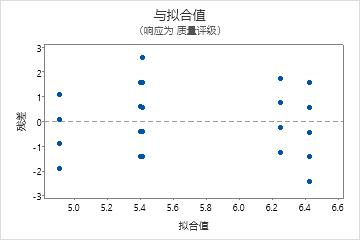
残差与拟合值图
使用残差与拟合值图可验证残差随机分布和具有常量方差的假设。理想情况下,点应当在 0 的两端随机分布,点中无可辨识的模式。
| 模式 | 模式的含义 |
|---|---|
| 残差相对拟合值呈扇形或不均匀分散 | 异方差 |
| 曲线 | 缺少高阶项 |
| 远离 0 的点 | 异常值 |
| 在 X 方向远离其他点的点 | 有影响的点 |
残差与顺序图
趋势
偏移
周期
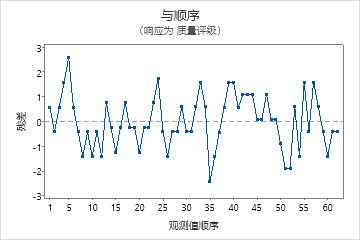
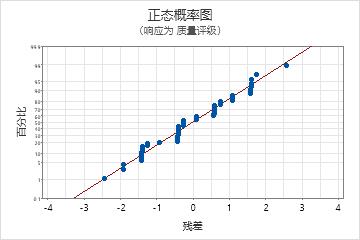
残差的正态概率图
使用残差正态概率图可验证残差呈正态分布的假设。残差的正态概率图应该大致为一条直线。
| 模式 | 模式的含义 |
|---|---|
| 非直线 | 非正态性 |
| 远离直线的点 | 异常值 |
| 斜率不断变化 | 未确定的变量 |