方差分量
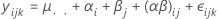
其中,αi, βj 、(αβ)ij 和 εijk 是独立随机变量。这些变量为正态分布,均值为零,其方差由以下公式给定:


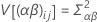

这些方差属于方差分量。在此例中,检验方差分量等于零的假设。
对于具有固定因子 A 和随机因子 B 的无约束混合模型,以下公式可描述该模型:
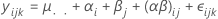
其中,αi 是固定效应,βj、(αβ)ij 和 εijk 是具有零均值和以下方差的不相关随机变量:

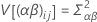

这些方差属于方差分量。Σα i = 0。
此信息用于平衡模型。有关不平衡模型或更多复杂模型的信息,请查看 Montgomery1 和 Neter2。
- D. C. Montgomery (1991)。Design and Analysis of Experiments(试验的设计和分析),第三版。John Wiley & Sons。
- J. Neter、W. Wasserman 和 M.H. Kutner (1985)。Applied Linear Statistical Models(应用线性统计模型),第二版。Irwin, Inc.
期望均方
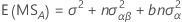



用于具有一个固定因子 A 和一个随机因子 B 的无约束混合模型的期望均方的公式如下:
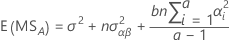



有关计算期望均方的一般规则,以及不平衡模型或更复杂模型的信息,请参阅 Montgomery1 和 Neter2。
- D. Montgomery (1991)。Design and Analysis of Experiments(试验设计和分析),第三版。John Wiley & Sons。
- J. Neter、W. Wasserman 和 M.H. Kutner (1985)。Applied Linear Statistical Models(应用的线性统计模型),第二版。Irwin, Inc.
表示法
| 项 | 说明 |
|---|---|
| b | 因子 B 中的水平数 |
| a | 因子 A 中的水平数 |
| n | 因子水平的每个组合中的观测值数 |
| σ2 | 模型的估计方差 |
 | A 的估计方差 |
 | B 的估计方差 |
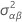 | AB 的估计方差 |
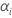 | A 的固定效应 |
具有随机因子的模型的 F 统计量
如何计算方差分析输出中的 F 统计量
每个 F 统计量都是均方比率。分子是项的均方。已选择分母,以便分子均方预期值仅在相关效应下不同于分母均方预期值。随机项的效应由项的方差分量表示。固定项的效应通过与该项相关的模型分量的平方和除以其自由度表示。因此,高 F 统计量表明效应显著。
当模型中的所有项均固定时,每个 F 统计量的分母都为均方误 (MSE)。但是,对于包含随机项的模型,MSE 并不总是正确的均方。预期均方 (EMS) 可用于确定哪一个适合分母。
示例
| 来源 | 每项的期望均方 |
|---|---|
| (1) 屏幕 | (4) + 2.0000(3) + Q[1] |
| (2) 技术 | (4) + 2.0000(3) + 4.0000(2) |
| (3) 屏幕*技术 | (4) + 2.0000(3) |
| (4) 误差 | (4) |
带括号的数字表示在源数字旁边列出的与项相关的随机效应。(2) 表示 Tech 的随机效应,(3) 表示 Screen*Tech 交互作用项的随机效应,(4) 表示误差的随机效应。误差的 EMS 是误差项的效应。此外,Screen*Tech 的 EMS 是误差项的效应与 Screen*Tech 双倍的交互作用项效应相加。
要计算“屏幕*技术”的 F 统计量,使用“屏幕*技术”的均方除以误差的均方,使得分子的预期值(“屏幕*技术”的 EMS = (4) + 2.0000(3))与分母的预期值(误差的 EMS = (4))仅在交互作用项 (2.0000(3))上存在差异。因此,高 F 统计量表明“屏幕*技术”交互作用显著。
Q[ ] 的数字表明与源数字旁边列出的项相关的固定效应。例如,Q[1] 是 Screen 的固定效应。Screen 的 EMS 是误差项的效应与两倍的 Screen*Tech 交互作用项效应相加。Q[1] 等于 (b*n * 总和 ((Screen 的水平系数)**2)) 除以 (a - 1),其中 a 和 b 分别是 Screen 和 Tech 的水平数,n 是仿行数。
要计算 Screen 的 F 统计量,可以使用 Screen 的均方除以 Screen*Tech 的均方, 这样,分子的预期值(Screen*Tech 的 EMS = (4) + 2.0000(3) + Q[1])与分母的预期值(Screen*Tech 的 EMS = (4) + 2.0000(3))仅在 Screen (Q[1]) 上存在差异。因此,高 F 统计量表明 Screen 效应显著。
为什么我的方差分析输出中在方差分析表的 p 值旁有一个“x”,且带有标签“不是精确的 F 检验”?
针对某个项的精确 F 检验是分子均方的预期值与分母均方的预期值仅在目标项的方差分量或固定因子上有所差异的检验。
但有时,这种均方是无法计算的。在这种情况下,Minitab 会使用一个适当的均方进行近似 F 检验,并在 p 值旁显示“x”,以标识 F 检验不精确。
| 来源 | 每项的期望均方 |
|---|---|
| (1) 补充 | (4) + 1.7500(3) + Q[1] |
| (2) 湖 | (4) + 1.7143(3) + 5.1429(2) |
| (3) 补充*湖 | (4) + 1.7500(3) |
| (4) 误差 | (4) |
“补充”的 F 统计量是用补充的均方除以“补充*湖”交互作用项的均方。如果“补充”的效应较小,分子的预期值将等于分母的预期值。下面是精确的 F 检验的示例。
但是请注意,对于非常小的“湖”效应,不存在分子预期值等于分母预期值的均方。因此,Minitab 使用近似 F 检验。在此示例中,“湖”的均方除以“补充*湖”交互作用项的均方。如果“湖”效应较小,这会导致分子预期值约等于分母预期值。
关于“F 检验的分母为零或未定义”消息
- 不存在至少一个误差自由度。
-
调整的 MS 值非常小,因此不够精确,无法显示 F 值和 p 值。作为计算方法,请将响应值列乘以 10。然后执行相同的回归模型,但取而代之,针对响应值使用新的响应值列。
注意
响应值乘以 10 将不会影响 Minitab 显示输出的 F 值和 p 值。但是,其余输出中的小数点位置将受到影响,特别是连续平方和、Adj SS、Adj MS、拟合、拟合的标准误和残差列。
如何计算方差分析输出中的 F 统计量
每个 F 统计量都是均方比率。分子是项的均方。已选择分母,以便分子均方预期值仅在相关效应下不同于分母均方预期值。随机项的效应由项的方差分量表示。固定项的效应通过与该项相关的模型分量的平方和除以其自由度表示。因此,高 F 统计量表明效应显著。
当模型中的所有项均固定时,每个 F 统计量的分母都为均方误 (MSE)。但是,对于包含随机项的模型,MSE 并不总是正确的均方。预期均方 (EMS) 可用于确定哪一个适合分母。
示例
| 来源 | 每项的期望均方 |
|---|---|
| (1) 屏幕 | (4) + 2.0000(3) + Q[1] |
| (2) 技术 | (4) + 2.0000(3) + 4.0000(2) |
| (3) 屏幕*技术 | (4) + 2.0000(3) |
| (4) 误差 | (4) |
带括号的数字表示在源数字旁边列出的与项相关的随机效应。(2) 表示 Tech 的随机效应,(3) 表示 Screen*Tech 交互作用项的随机效应,(4) 表示误差的随机效应。误差的 EMS 是误差项的效应。此外,Screen*Tech 的 EMS 是误差项的效应与 Screen*Tech 双倍的交互作用项效应相加。
要计算“屏幕*技术”的 F 统计量,使用“屏幕*技术”的均方除以误差的均方,使得分子的预期值(“屏幕*技术”的 EMS = (4) + 2.0000(3))与分母的预期值(误差的 EMS = (4))仅在交互作用项 (2.0000(3))上存在差异。因此,高 F 统计量表明“屏幕*技术”交互作用显著。
Q[ ] 的数字表明与源数字旁边列出的项相关的固定效应。例如,Q[1] 是 Screen 的固定效应。Screen 的 EMS 是误差项的效应与两倍的 Screen*Tech 交互作用项效应相加。Q[1] 等于 (b*n * 总和 ((Screen 的水平系数)**2)) 除以 (a - 1),其中 a 和 b 分别是 Screen 和 Tech 的水平数,n 是仿行数。
要计算 Screen 的 F 统计量,可以使用 Screen 的均方除以 Screen*Tech 的均方, 这样,分子的预期值(Screen*Tech 的 EMS = (4) + 2.0000(3) + Q[1])与分母的预期值(Screen*Tech 的 EMS = (4) + 2.0000(3))仅在 Screen (Q[1]) 上存在差异。因此,高 F 统计量表明 Screen 效应显著。
为什么我的方差分析输出中在方差分析表的 p 值旁有一个“x”,且带有标签“不是精确的 F 检验”?
针对某个项的精确 F 检验是分子均方的预期值与分母均方的预期值仅在目标项的方差分量或固定因子上有所差异的检验。
但有时,这种均方是无法计算的。在这种情况下,Minitab 会使用一个适当的均方进行近似 F 检验,并在 p 值旁显示“x”,以标识 F 检验不精确。
| 来源 | 每项的期望均方 |
|---|---|
| (1) 补充 | (4) + 1.7500(3) + Q[1] |
| (2) 湖 | (4) + 1.7143(3) + 5.1429(2) |
| (3) 补充*湖 | (4) + 1.7500(3) |
| (4) 误差 | (4) |
“补充”的 F 统计量是用补充的均方除以“补充*湖”交互作用项的均方。如果“补充”的效应较小,分子的预期值将等于分母的预期值。下面是精确的 F 检验的示例。
但是请注意,对于非常小的“湖”效应,不存在分子预期值等于分母预期值的均方。因此,Minitab 使用近似 F 检验。在此示例中,“湖”的均方除以“补充*湖”交互作用项的均方。如果“湖”效应较小,这会导致分子预期值约等于分母预期值。
关于“F 检验的分母为零或未定义”消息
- 不存在至少一个误差自由度。
-
调整的 MS 值非常小,因此不够精确,无法显示 F 值和 p 值。作为计算方法,请将响应值列乘以 10。然后执行相同的回归模型,但取而代之,针对响应值使用新的响应值列。
注意
响应值乘以 10 将不会影响 Minitab 显示输出的 F 值和 p 值。但是,其余输出中的小数点位置将受到影响,特别是连续平方和、Adj SS、Adj MS、拟合、拟合的标准误和残差列。