公差区间方法
Minitab 同时计算参数和非参数公差区间。参数公差区间的计算将假设样本的父分布呈正态分布。非参数公差区间的计算仅假设父分布为连续分布。
一般定义
设 X 1, X 2, ..., X n 为基于部分连续分布中数量为 n 的随机样本的排序统计量。
假设维度大于或等于 1 的某个参数空间中 Ω 的分布函数为 F(χ;θ)。
假设 L < U 是两个基于样本的统计量,对于任何给定值 α 和 P(0 < α < 1,0 < P < 1),以下等式针对 Ω 中的每个 θ 都成立:
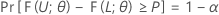
然后,区间 [L, U] 是双侧公差区间,其容量 = P x 100%,置信区间 = 100(1 – α)%。类似的区间可称为双侧 (1 – α, P) 公差区间。例如,如果 α = 0.10,P = 0.85,则生成的区间称为双侧 (90%, 0.85) 公差区间。
如果 L = –∞ 且 U < +∞,则区间 (-∞, U] 称为单侧 (1 – α, P) 公差上限。如果 L > -∞ 且 U = +∞,则区间 [L, +∞) 称为单侧 (1 – α, P) 公差下限。
- 单侧 (1 – α, P) 公差下限也是单侧 (α, 1 – P) 公差上限。
- 数据分布的第 (1 – P) 个百分位数的单侧 (1 – α)100% 置信下限也称为单侧 (1 – α, P) 公差下限。同样地,数据分布的第 P 个百分位数的单侧 (1 – α)100% 置信上限也称为单侧 (1 – α, P) 公差上限。
- 如果 L 和 U 是单侧 (1 – α/2, (1 + P)/2) 公差上限和下限,则 [L, U] 是近似双侧 (1 – α, P) 公差区间。此方法可以在无法直接获得双侧公差区间的情况下使用。生成的双侧公差区间通常是保守的区间。请参见 Guenther1 以及 Hahn 和 Meeker2。
- Guenther, W. C. (1972)。Tolerance intervals for univariate distributions(单变量分布的公差区间),Naval Research Logistics(海军物流研究),第 19 期:第 309 到 333 页。
- Hahn G. J. 和 Meeker W. Q. (1991)。Statistical Intervals: A Guide for Practitioners(统计间隔:从业者指南)。纽约 John Wiley & Sons。
正态分布的精确公差区间

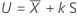
单侧区间的公差因子
单侧区间的精确公差因子可以通过以下方程得出: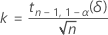
其中,tn-1,1-α(δ) 是自由度为 n – 1 且非中心参数为 δ 的非中心 t 分布的第 1 – α 个百分位数,δ 可以通过以下公式得出:

双侧区间的公差因子
双侧区间的精确公差因子通过对 k 的以下方程求解而获得。请参见 Krishnamoorthy 和 Mathew1。
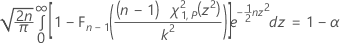
其中,Fn – 1 是自由度为 n – 1 的卡方分布的累积分布函数,χ21,p 是自由度为 1 且非中心参数为 z2 的非中心卡方分布的第 P 个百分位数。方程的左侧可以改写为:
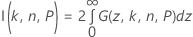
其中:
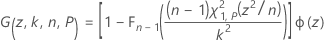
其中,Φ(z) 是标准正态分布的概率密度函数。Minitab 使用 36 点的 Gauss-Legendre 求积来评估 I(k, n, P)。
表示法
| 项 | 说明 |
|---|---|
| 1 - α | 公差区间的置信水平 |
| P | 公差区间的范围(区间中的目标最小总体百分比) |
| L | 公差区间的下限 |
| U | 公差区间的上限 |
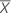 | 样本均值 |
| k | 公差因子(又称为 k 因子) |
| S | 样本的标准差 |
| n | 样本中的观测值个数 |
| ZP | 标准正态分布的第 P 个百分位数 |
- Krishnamoorthy, K. 和 Mathew, T. (2009)。Statistical Tolerance Regions: Theory, Applications, and Computation(统计公差区域:理论、应用和计算)。纽约 Hoboken 的 Wiley。
连续分布的精确非参数公差区间
Minitab 计算精确的 (1 – α, P) 非参数公差区间,其中 1 – α 是置信水平,P 是范围(区间中的目标最小总体百分比)。公差区间的非参数方法是与分布无关的方法。换言之,非参数公差区间不取决于样本的父总体。Minitab 将对单侧和双侧区间使用精确方法。
设 X 1, X 2 , ... , X n 为基于部分连续分布总体 F(x;θ) 中随机样本的排序统计量。那么,根据 Wilks1, 2 和 Robbins3 的发现,可以得出:

其中 B 表示具有参数 a = r 和 b = n – s + 1 的 Beta 分布的累积分布函数。因此,(Xr, Xs) 是与分布无关的公差区间,因为区间范围具有使用已知参数值的 Beta 分布,这些值独立于父总体 F(x;θ) 的分布。
单侧区间
设 k 为满足如下条件的最大整数:

其中 Y 是使用 n 和 1 – P 参数的二项式随机变量。可以看出(请参见 Krishnamoorthy 和 Mathew4),单侧 (1 – α, P) 公差下限由 Xk 给定。相同地,单侧 (1 – α, P) 公差上限由 X n - k +1 给定。在这两种情况下,实际范围或有效范围由 P(Y > k) 给定。
双侧区间
设 k 为满足如下条件的最小整数:

其中 V 是使用 n 和 P 参数的二项式随机变量。因此,
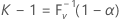
其中,F V -1(x) 是 V 的逆累积分布函数。可以看出(请参见 Krishnamoorthy 和 Mathew4),双侧 (1 – α, P) 公差区间可以由 (Xr, Xs) 给定。Minitab 选择 s = n - r + 1,以便 r = (n – k + 1) / 2。r 和 s 向下舍入到最近的整数。实际范围或有效范围由 P(V < k – 1) 给定。
表示法
| 项 | 说明 |
|---|---|
| 1 – α | 公差区间的置信水平 |
| P | 公差区间的范围(区间中的目标最小总体百分比) |
| n | 样本中的观测值个数 |
- Wilks, S. S. (1941)。Sample size for tolerance limits on a normal distribution(正态分布公差限的样本数量)。The Annals of Mathematical Statistics(数理统计年报),第 12 期,第 91 到 96 页。
- Wilks, S. S. (1941)。Statistical prediction with special reference to the problem of tolerance limits(特别针对公差限问题的统计预测)。The Annals of Mathematical Statistics(数理统计年报),第 13 期,第 400 到 409 页。
- Robbins, H. (1944)。On distribution-free tolerance limits in random sampling(关于随机抽样中与分布无关的公差限)。The Annals of Mathematical Statistics(数理统计年报),第 15 期,第 214 到 216 页。
- Krishnamoorthy, K. 和 Mathew, T. (2009)。Statistical Tolerance Regions: Theory, Applications, and Computation(统计公差领域:理论、应用和计算)。Wiley, Hoboken, NJ.