关于本主题
自由度
每个 SS(平方和)的自由度 (DF)。通常,DF 用于测量计算每个 SS 时可用的信息量。
SS
平方和 (SS) 是各个平方距离之和,用来度量来自不同源的变异性。合计 SS 表明来自总体平均值的数据中的变异数量。SS 操作员指示每位操作员的平均测量值和总体平均值之间的变异量。
SS 合计 = SS 操作员 + SS 部件(操作员)+ SS 重复性
MS
均方 (MS) 是来自各个源的数据中的变异性。MS 考虑了不同源的水平数或可取值的个数不同在计算中的影响。
MS = SS/每一种变异源的 DF 值
F
该统计量用于确定操作员或部件(操作员)是否会对测量结果产生显著影响。
F 统计量越大,该因子在响应或测量变量的变异性中所起的作用就越大。
P
如果原假设成立,P 值就是获得至少与从样本计算的值一样极端的检验统计量(如 F 统计量)的概率。
解释
使用方差分析表中的 p 值可以确定平均测量值之间是否存在显著差异。
如果 p 值较小,则说明所有操作员或部件(操作员)均值均相同的假定可能不为真。
- P 值 ≤ α:至少一个均值存在显著差异
- 如果 p 值小于或等于显著性水平,则可否定原假设并得出至少有一个均值与其他均值显著不同的结论。例如,至少一位操作员的测量结果不同。
- P 值 > α:均值之间不存在显著差异
- 如果 p 值大于显著性水平,则无法否定原假设,因为您没有足够的证据断定总体均值存在差异。例如,您无法得出操作员的测量结果不同的结论。
方差分量
方差分量是针对 ANOVA 表中每个源的预估方差分量。
解释
使用方差分量评估每个测量误差源的变异性。
对于可接受的测量系统来说,最大的变异分量为部件之间的变异。如果重复性和再现性对于变异量贡献很大,您需要研究问题的来源并采取纠正措施。
方差分量贡献率
% 贡献是每个方差分量占总体变异性的百分比。它等于每个源的方差分量除以总变异,再乘以 100。
解释
使用贡献率评估每个测量误差源的变异性。
对于可接受的测量系统来说,最大的变异分量为部件之间的变异。如果重复性和再现性对于变异量贡献很大,您需要研究问题的来源并采取纠正措施。
标准差(SD)
标准差 (SD) 是每个变异来源的标准差。此标准差等于该源方差分量的平方根。
标准差是一种测量变异的便利方式,因为标准差具有与部件测量和公差相同的单位。
研究变异 (6 * SD)
研究变异等于每个变异来源的标准差与 6 或您在研究变异中指定的乘数相乘。
通常,过程变异会定义为“6s”,其中“s”是作为总体标准差(表示为 σ 或 sigma)估计值的标准差。当数据正态分布时,接近 99.73% 的数据处于均值的 6 个标准差内。要定义不同的数据百分比,请使用其他标准差乘数。例如,如果要知道 99% 的数据处于哪个范围,可使用乘数 5.15 而非默认乘数 6。
%研究变异 (%SV)
% 研究变异等于每个变异来源的研究变异除以总研究变异,然后再乘以 100。
% 研究变异是该源的计算方差分量 (VarComp) 的平方根。因此,VarComp 的 % 贡献之和等于 100,但 % 研究方差值之和不等于 100。
解释
利用 %研究变异将测量系统变异与总体变异做比较。如果利用测量系统评估过程改进情况,如降低部件之间的变异性,则 %研究变异可以对测量精度进行较好地估计。如果要评估测量系统的能力以评估部件与规格的比较,则 %公差是合适的度量。
%公差 (SV/Toler)
%公差作为每个来源的研究变异进行计算,通过除以过程公差并乘以 100 计算得出。
如果输入公差,Minitab 则会计算 %公差,它将测量系统变异与规格相比。
解释
利用 %公差可相对于规格评估部件。如果利用测量系统评估过程改进情况,如降低部件之间的变异性,则适合使用 %研究变异度量。
% 过程 (SV/Proc)
如果您输入历史标准差但使用研究中的部件估计过程变异,则 Minitab 会计算 % 过程。% 过程将测量系统变异与历史过程变异进行比较。% 过程等于每个源的研究变异除以历史过程变异,再乘以 100。默认情况下,过程变异等于 6 乘以历史标准差。
如果您使用历史标准差估计过程变异,Minitab 将不显示 % 过程,因为 % 过程与 % 研究变异相同。
95% 置信区间
95% 置信区间 (95% CI) 是可能包含每个测量错误度量真实值的值范围。
Minitab 提供了方差分量的置信区间、方差分量的贡献百分比、标准差、研究变异、研究变异百分比、公差百分比和可区分类别数。
解释
因为数据样本是随机的,所以两个量具研究不可能得出相同的置信区间。但是,如果多次重复进行您的研究,则特定百分比的包含未知真实测量的结果置信区间将发生错误。这些包含参数的置信区间的百分比是区间的置信水平。
例如,具有 95% 的置信水平,置信区间便可以有 95% 的置信度包含真实值。置信区间有助于评估结果的实际意义。使用专业知识确定置信区间是否包含对您有实际意义的值。如果置信区间范围太广而不实用,则请增大样本大小。
假定 VarComp 的重复性是 0.044727,对应的 95% CI 是 (0.035, 0.060)。从该数据计算得出的估计重复性变异是 0.044727。置信区间 0.035 到 0.060 包含真实重复性变异的置信度为 95%。
可区分类别数
可区分类别数是在量具 R&R 研究中使用的度量,用于识别测量系统检测测量特征中的差异的能力。可区分类别数表示跨越产品变异极差的非重叠置信区间数,由您选择的样本数定义。可区分类别数还表示您的测量系统可识别的过程数据中的分组数。
误分类概率(P)
当您指定至少一个规格限时,Minitab 可以计算将产品误分类的概率。因为量具的变异,部件的测量值不会总是等于部件的真实值。测量值和真实值之间的差异造成了对部件误分类的可能性。
- 联合概率
- 如果以前对部件的可接受情况不了解,请使用联合概率。例如,您正在生产线中抽样,但并不了解具体每个部件合格与否。您可能会做出两种误分类:
- 可能某部件是不合格的,而您接受了它。
- 可能某部件是合格的,而您拒绝了它。
- 条件概率
- 如果以前对部件的可接受情况有所了解,请使用条件概率。例如,您正在从一堆返工品中或从即将作为合格产品发货的一批产品中抽样。您可能会做出两种误分类:
- 可能会接受某个从一堆需要返工的不合格产品中抽样的部件(也称为误接受)。
- 可能会拒绝某个从一堆即将发货的合格产品中抽样的部件(也称为误拒绝)。
解释
联合概率
| 说明 | 概率 |
|---|---|
| 随机选择的部件不合格,但被接受 | 0.037 |
| 随机选择的部件合格,但被拒绝 | 0.055 |
条件概率
| 说明 | 概率 |
|---|---|
| 来自一组不合格产品的部件被接受 | 0.151 |
| 来自一组合格产品的部件被拒绝 | 0.073 |
接受一个不合格部件的联合概率是 0.037。拒绝一个合格部件的联合概率是 0.055。
误接受的条件概率(也即在重新检验过程中接受实际不符合规格的部件)是 0.151。误拒绝的条件概率(也即在重新检验过程中拒绝实际符合规格的部件)是 0.073。
VDA 5
注意
VDA 5 仅在 Web 应用程序 中提供。
注意
该分析使用 uEVR、uRE 和 uEVO 之间的最大不确定度来计算测量过程的变化。缺少其他 2 个统计量的 % of Total ,因为这些统计量不计入总数。
- 校准 (uCAL)
- 校准 (uCAL) 是参考标准校准的测量结果的不确定度。此统计量是分析的输入。通常,该值来自校准证书。
- 参考时的可重复性 (uEVR)
- 参考时的可重复性 (uEVR) 是同一操作员使用同一设备重复测量参考部件的不确定度。此统计量是分析的输入。通常,该值来自 I 型量具研究。
- 分辨度 (uRE)
- 分辨度 (uRE) 是由于仪表分辨率引起的不确定度。当仪表的分辨率是分析的输入时,分析将计算此统计量。
- 被测物体的重复性(uEVO)
- 被测物体的可重复性(uEVO)是由于量具 R&R 研究中可重复性而产生的不确定性。重复性是同一操作员多次测量同一零件时测量的可变性。
- 偏倚(uBI)
- 偏倚 (uBI) 是由于与已知参考测量值和研究中测量值的平均值的差异而导致的测量值的不确定性。此统计量是分析的输入。通常,该值来自参考零件在测量范围内的偏差研究。
- 线性(uLIN)
- 线性 (uLIN) 是线性度测量的不确定度。线性度是参考零件的值与平均测量值之间的差值,该测量值来自零件值变化时偏差的变化。此统计量是分析的输入。通常,该值来自参考零件在测量范围内的线性度研究。
- 其他因素 (uREST)
- 其他因素 (uREST) 是由于一个或多个其他因素导致的测量不确定性。如果分析的规格有一个附加因素,则该不确定性是分析的输入。如果分析的规范具有多个因子,则此不确定性将合并这些值。例如,如果数据收集在较高温度下测量值差异较大,则使用其他因素的规格来解释温度引起的不确定性。
- 运营商 (uAV)
- 操作员 (uAV) 是由于量具 R&R 研究中的可重复性而导致的测量不确定性。可重复性是当不同的操作员测量同一零件时测量的可变性。
- 测量过程 (uMP)
- 测量过程 (uMP) 结合了所有不确定度组件,以估计测量过程中的总不确定度。
- 总和的 %
- 对于每个不确定性来源,分析显示来自该来源的 uMP 百分比。使用百分比来比较来自不同来源的不确定性量。
- 公差百分比 (%QMP)
- 公差百分比 (%QMP) 将测量过程的不确定度与研究变化相结合,并将该值与过程公差进行比较。%QMP 是确定测量过程是否令人满意的常用方法。在某些应用中,30% 或更小的值表示测量过程令人满意。
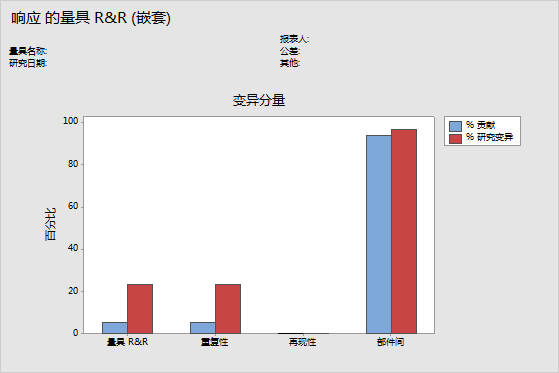
变异分量图
变异分量控制图是量具 R&R 研究结果的图形总结。
- 合计量具 R&R:重复性方差分量和再现性方差分量之和。
- 重复性:同一操作员测量同一批次中的部件时的测量变异性。
- 再现性:不同操作员测量部件时的测量变异性。
- 部件间:由于部件的不同所引起的测量变异性。
解释
- % 贡献
- % 贡献是每个方差分量占总变异的百分比。它等于将每个源的方差分量除以总变异,再乘以 100。
- % 研究变异
- % 研究变异是每个源的研究变异所占的百分比。它等于每个源的研究变异除以总研究变异,然后再乘以 100。
- % 公差
- % 公差将测量系统变异与规格进行比较。它等于每个源的研究变异除以过程公差,再乘以 100。
- % 过程
- % 过程将测量系统变异与过程总变异进行比较。它等于每个源的研究变异除以历史过程变异,再乘以 100。
在可接受的测量系统中,最大的变异分量为部件之间的变异。
R 控制图
R 控制图是一种极差控制图,显示操作员的一致性。
- 标绘点
- 对于每位操作员,每个部件的最大值和最小值之间的差值。R 控制图上的点由操作员标绘,因此您可以看出每位操作员测量的一致程度。
- 中心线 (Rbar)
- 过程的总平均值(即所有样本极差的平均值)。
- 控制限(LCL 和 UCL)
- 预计的样本极差变异量。Minitab 使用样本内的变异计算控制限。
注意
如果每位操作员对每个部件测量 9 次或更多次,Minitab 显示 S 控制图(而非 R 控制图)。
解释
小的平均极差表示测量系统的变异性低。高于控制上限 (UCL) 的点表示操作员对部件的测量不一致。UCL 的计算包括每位操作员对部件的测量次数以及部件之间的变异。如果操作员对部件的测量一致,那么与研究变异相比,最高测量值与最低测量值之间的极差就很小,且各个点都应该处于受控状态。
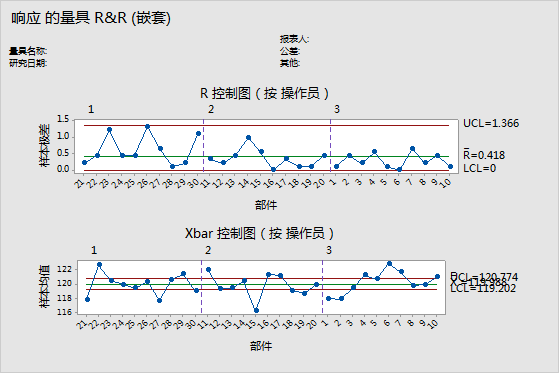
Xbar 控制图
Xbar 控制图将部件间变异与重复性分量进行比较。
- 标绘点
- 每个部件的平均测量值,由每位操作员标绘。
- 中心线 (Xbar)
- 所有操作员测量的所有部件测量值的整体平均值。
- 控制限(LCL 和 UCL)
- 控制限基于每个平均值中的重复性估计和测量次数。
解释
为量具 R&R 研究选择的部件应当代表所有可能的部件。因此,该图应当表示期望在部件均值间观察到的变异比重复性变异多。
通常,该图的控制限较窄,其中的许多失控点表示具有低变异的测量系统。
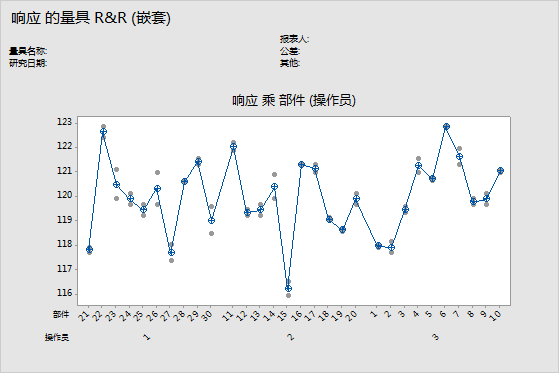
部件(操作员)对比图
“按部件(操作员)”图形显示在研究过程中所测量并按部件排列的所有测量值。此图显示因子水平之间的差异。通常,量具 R&R 研究按部件和按操作员排列测量值。但是,使用扩展的量具 R&R 研究,可以在图中绘制其他因子。
在此图中,点表示测量值,而带十字标的圆形符号表示均值。连接线连接每个因子水平的平均测量值。
注意
如果每个水平的观测值大于 9,Minitab 将显示箱线图而非单值图。
解释
如果每个部件的多个测量值的变化尽可能小(一个部件的点接近另一个部件的点),则表示测量系统的变异小。而且,部件的平均测量值的变异足够大时才会显示部件有差异和表示整个过程极差。
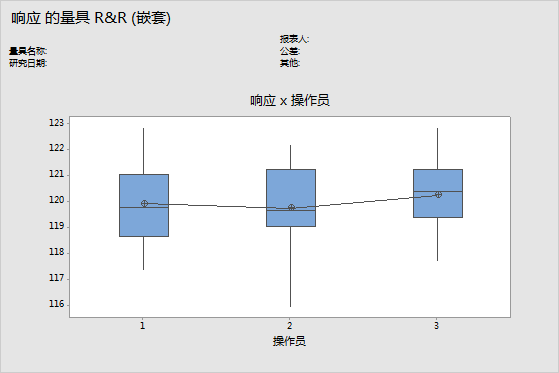
“按操作员”图
“按操作员”图形显示研究过程中所测量并按操作员排列的所有测量值。此图显示因子水平之间的差异。通常,量具 R&R 研究按部件和按操作员排列测量值。但是,使用扩展的量具 R&R 研究,可以在图中绘制其他因子。
注意
如果每个操作员大于 9 个观测值,Minitab 将显示箱线图而非单值图。
解释
跨操作员的直线水平线表示每位操作员的测量值均值是相似的。理想情况下,每位操作员的测量值之间的差值应相同。