量具 R&R 扩展研究法
Minitab 使用带有三种方差分析模型的一般线性模型法执行量具 R&R 研究:随机效应模型、混合效应模型和嵌套设计模型。默认使用随机效应模型。如果任何因子是固定因子或嵌套因子,则使用混合效应模型或嵌套设计模型。
最终选定的模型仅包含主效应项、显著高次交互作用,以及它们之间的相关交互作用。Minitab 为合适模型计算方差分析表。然后,使用该表计算量具 R&R 表中出现的方差分量。
参考书
Burdick, R. K., Borror, C. M., and Montgomery, D.C. (2003). "A Review of Methods for Measurement Systems Capability Analysis", Journal of Quality Technology, 35(4) 342–354.
Adamec, E. and Burdick, R.K. (2003). "Confidence Intervals for a Discrimination Ratio in a Gauge R&R Study with Three Random Factors", Quality Engineering, 15(3) 383–389.
随机效应模型
此命令中使用的默认模型是随机效应模型。如果您指定完整的三因子模型,则:
Yijkl = μ + Pi + Oj + Ak + (PO)ij + (PA)jk + (OA)jk + (POA)ijk + εijkl
| 项 | 说明 |
|---|---|
| μ | 常量 |
| Pi | 第 i 个部件 |
| 项 | 说明 |
|---|---|
| Oj | 第 j 个操作员 |
| 项 | 说明 |
|---|---|
| Ak | 附加因子的第 k 种水平 |
Pi、Oj、Ak、(PO)ij、(PA)jk、(OA)jk、(POA)ijk 和 εijkl 服从均值为零的独立正态分布,它们分别是以下各项的方差: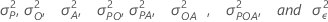 。
。
Minitab 使用 拟合一般线性模型 来估计方差分量。有关估计方差分量的更多详细信息,请转到“拟合一般线性模型 的方法和公式”。
- 合计量具 R&R
-

- 重复性
-

- 再现性
-
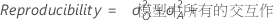
- 操作员
-

- A
-

- 部件 * 操作员
-

- 部件 * A
-

- 部件间
-

- 部件
-

- 合计变异
-
注意
在指定用来估计过程变异的历史标准差时,Minitab 执行以下操作:
- 如果历史标准差大于根据数据计算的总量具标准差,则总标准差为 σ,部件间标准差为
 。
。 - 否则,Minitab 使用数据估计总标准差和部件间的变异。
- 合计量具 R&R
-

- 重复性
-

- 再现性
-
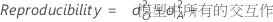
- 操作员
-

- 部件 * 操作员
-

- 部件间
-

- 部件
-

- A
-

- 部件 * A
-

- 合计变异
-
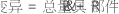
注意
在指定用来估计过程变异的历史标准差时,Minitab 执行以下操作:
- 如果历史标准差大于根据数据计算的总量具标准差,则总标准差为 σ,部件间标准差为
 。
。 - 否则,Minitab 使用数据估计总标准差和部件间的变异。
- 量具重复性 = 误差项的方差分量
- 部件间变异 = 部件的方差分量或者部件间项的方差分量之和
- 量具再现性 = 其余项的方差分量之和
混合效应模型
如果线性模型中的某些项是固定的,则该模型为混合效应模型。随机项的方差分量是使用拟合一般线性模型的结果获取的。
有关估计方差分量的更多详细信息,请转到“拟合一般线性模型的方法和公式”。
- 通过拟合线性模型,Minitab 会估计因子的前 J-1 个水平的系数。
- 水平 J 的系数 = –(前 J-1 个水平的系数之和)。
- 估计的变异性 = 所有水平的 (系数)2 之和/水平数。
在计算混合效应的量具再现性时,固定项的方差分量将替换为 φ,而随机效应模型定义保持不变。
嵌套设计模型
如果某些因子嵌套在其他因子之中,Minitab 将使用 拟合一般线性模型 拟合模型。有关估计方差分量的详细信息,请转到“拟合一般线性模型 的方法和公式”。
量具重复性、再现性和部件间的变异在随机因子和固定因子的情况下定义方式相同。
量具 R&R 扩展计算
Minitab displays two tables for 扩展量具 R&R 研究. 第一个表包含 VarComp 列和%贡献(VarComp)列。 For more details about estimating variance components, go to Methods and Formulas for 拟合一般线性模型.
%贡献 = VarComp 的值 / 总变异。
- StdDev (SD) = sqrt (VarComp)
- 研究 Var = 标准偏差数 * StdDev
- %研究 Var (%SV) = 研究 Var / 研究 Var 用于总变异
- %容差 = 研究 Var / 过程容差
- %过程 = StdDev / 历史标准偏差
公差百分比和置信区间
%容差是每个组件的容差百分比。
如果给出容差(上规格 = 下规格),则通过将每个分量的算量除以指定的容差来计算百分比。

如果仅给定一个规格限值,则公差百分比是单侧公差除以每个分量“研究变异”的二分之一。单侧公差是将所有测量的平均值减去给定规格限值的绝对值。
Minitab 仅当您在“选项”子对话框中输入过程公差(规格上限 - 规格下限)或某个规格限值时才显示此值。
If L and U are the lower and upper bounds of a variance component, then the confidence interval for the corresponding percent tolerance is:

| 项 | 说明 |
|---|---|
| k | k 是研究常量,默认值为 6 |
可区分类别数
可区分类别数表示要跨越产品变异极差的非重叠置信区间数。您也可以将其视为测量系统可识别的过程数据中的分组数。
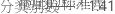
然后,Minitab 会截断该值的尾数,除非该值小于 1。如果小于 1,Minitab 会将可区分类别数设为等于 1。
置信区间
假设 L 和 U 是量具方差和总方差比率的下限和上限,则可区分类别数的下限和上限为:


注意
L 和 U 必须介于 (0, 1) 之间。如果 L 和 U 超出该范围,则可区分类别数的下限和上限将缺失。
误分类概率
当至少输入一个规格限时,Minitab 会将误分类概率作为联合概率和条件概率进行计算。对于提供方差分析方法和 Xbar-R 方法的分析,结果包括使用方差分析方法时错误分类的概率。
联合概率
该部分是坏的并且您接受它的概率:
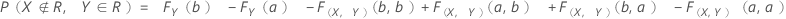
该部分是好的,而你拒绝它的概率:
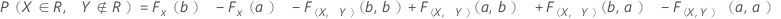
条件概率
给定一个零件是坏的概率,你接受它(错误接受):

给定一个零件是好的,你拒绝它的概率(错误拒绝):

表示法

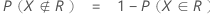
F(X,Y ) 是双变量正态随机向量 (X,Y)T 的累积分布函数 (CDF),具有:
平均值,μ = (θ,θ)T
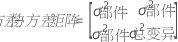
F(X) 和 F(Y) 是相应的边际 CDF。
即,

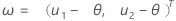
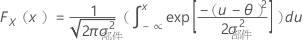
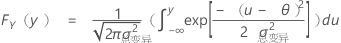
VDA 5 的统计数据
- 分辨度 (uRE)
-

- 被测物体的重复性(uEVO)
- √(重复性的方差分量)
- 操作员的可重复性 (uAV)
- √(运算符的方差分量)
- 研究中因素的贡献(u 后跟因素名称)
- uVi = √(因子的方差分量)
- 交互 (uIA)

- 其他因素 (uREST)
-

- 测量过程 (uMP)
-

总和的 %

%QMP

表示法
| 项 | 说明 |
|---|---|
| n | 测量次数 |
| xi | 第 i部分 的测量 |
 | n 次测量值的平均值 |
| RE | 测量过程的分辨率。如果分析规范包括分辨率,则计算会考虑分辨率引起的不确定度。 |
| xm | 参考测量 |
| Ci | 交互的方差组件 |
| j | 具有统计显著性的交互数 |
| Fi | 由于研究中未存在的其他因素而导致的不确定性。这些值来自分析规范。 |
| a | 导致分析规范不确定性的其他因素的数量 |
| uCAL | 校准带来的不确定度。除非分析规范包含该值,否则该值为 0。 |
| uEVR | 参考值下可重复性引起的不确定度。除非分析规范包含该值,否则该值为 0。 |
| uBI | 偏见导致的不确定性。除非分析规范包含该值,否则该值为 0。 |
| uLIN | 由于线性而产生的不确定性。除非分析规范包含该值,否则该值为 0。 |
| uVi | 由于研究中除零件和操作员之外的其他因素造成的不确定性 |
| b | 研究中除零件和操作员外,导致不确定性的因素数量 |
| ui | 不确定性的单一组成部分 |
| k1 | Minitab 使用标准正态分布的 6 个标准差的默认值来表示测量值的 99.73%。 若要更改此值,请参阅 “选项” 子对话框。例如,使用乘数 5.15 表示 99% 的测量值。 |