N
样本数量 (N) 是原始样本中的观测值总数。Minitab 抽取此样本数量的重复样本来形成自举样本。
均值
均值是数据的平均值,即所有观测值之和除以观测值的个数。
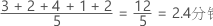
标准差
标准差是离差的最常用度量,即数据从均值展开的程度。符号 σ(西格玛)通常用于表示总体的标准差,而 s 用于表示样本的标准差。对某一过程而言随机或合乎自然规律的变异通常称为噪声。对某一过程而言随机或合乎自然规律的变异通常称为噪声。
由于标准差与数据采用相同的单位,因此它通常比方差更易于解释。
解释
使用标准差可以确定数据从均值扩散的程度。 标准差值越大,数据越分散。 对于正态分布来说,好的经验法则是大约 68% 的值位于均值的一个标准差范围内,95% 的值位于两个标准差范围内,99.7% 的值位于三个标准差范围内。
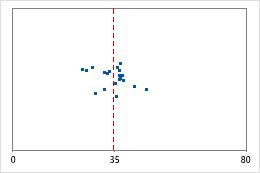
医院 1
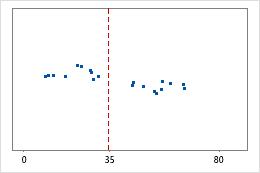
医院 2
医院出院时间
管理员对两家医院急诊部所治疗的患者的出院时间进行跟踪。尽管平均出院时间大致相同(35 分钟),但标准差显著不同。医院 1 的标准差大约为 6。平均而言,患者的出院时间大约偏离均值(虚线)6 分钟。医院 2 的标准差大约为 20。
方差
方差度量数据围绕其均值的分散程度。方差等于标准差的平方。
解释
方差越大,数据越分散。
由于方差 (σ2) 是量的平方,因此其单位也是平方的,这在实际讨论中容易使人混淆。由于标准差与数据采用相同的单位,因此它通常更易于解释。例如,在公共汽车站等待时间样本的均值为 15 分钟,方差为 9 分钟2。由于方差与数据采用不同的单位,所以方差通常会显示为其平方根,即标准差。方差 9 分钟2 等效于标准差 3 分钟。
和
和是所有数据值的合计。和还用在统计计算中,如用于计算均值和标准差。
最小值
最小值是最小的数据值。
在这些数据中,最小值为 7。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解释
使用最小值可以标识可能的异常值或数据输入错误。评估数据散布最简单的方法之一就是比较最小值和最大值。如果最小值非常低,甚至要考虑数据的中心、散布和形状,请调查出现极端值的原因。
中位数
中位数是数据集的中点。在此中点值所在的点上,有一半的观测值大于中点值,有一半的观测值小于中点值。中位数是通过对观测值排秩并在秩顺序中查找第 [N + 1] / 2 位的观测值来确定的。如果观测值数为偶数,则中位数是排在第 N / 2 位和第 [N / 2] + 1 位的观测值的平均值。
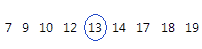
对于此排序数据,中位数是 13。也就是说,一半的值小于或等于 13,一半的值大于或等于 13。如果添加另一个等于 20 的观测值,则中位数为 13.5,即第 5 个观测值 (13) 和第 6 个观测值 (14) 的平均值。
解释
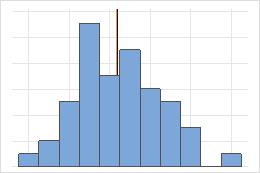
对称
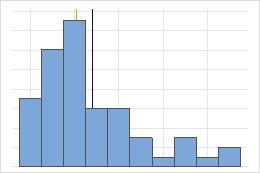
非对称
对于对称分布,均值(蓝线)和中位数(橙线)非常相似,以至于您很难区分这两条线。但是,非对称分布会向右偏斜。
最大值
最大值是指最大的数据值。
在这些数据中,最大值为 19。
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
解释
使用最大值可以标识可能的异常值或数据输入错误。评估数据散布最简单的方法之一就是比较最小值和最大值。如果最大值非常高,甚至要考虑数据的中心、散布和形状,请调查出现极端值的原因。