指定估计方法、固定效应项的检验方法以及要显示的结果。对默认设置所做的更改将保留到您再次更改它们,即使退出 Minitab 也是如此。
- 估计法
-
您可以选择 限制的极大似然(REML) 或 极大似然(ML)。通常,您使用 限制的极大似然(REML),因为限制极大似然的方差分量估计量大致是无偏的,而极大似然估计量是偏倚的。但是,样本数量越大,偏倚越小。
如果需要检验具有一些固定效应项的嵌套模型与具有更多固定效应项的相应参考模型是否等效,而前提是两种模型都具有相同的随机项数和误差方差结构,则使用 极大似然(ML)。具体来说,设
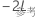 为整个模型中的负 2 对数似然,并且设
为整个模型中的负 2 对数似然,并且设 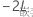 为较小模型的负 2 对数似然。
为较小模型的负 2 对数似然。在原假设下,通过渐近方式,
 服从卡方分布,其自由度等于参考模型和嵌套模型中固定效应项数的差值。您可以使用似然比检验来评估是否可以从参考模型中移除固定效应项子集。
服从卡方分布,其自由度等于参考模型和嵌套模型中固定效应项数的差值。您可以使用似然比检验来评估是否可以从参考模型中移除固定效应项子集。有关混合效应模型中固定参数的似然比检验的更多信息,请参见 B. T. West, K.B.Welch 和 A.T.Gałecki (2007)。Linear Mixed Models: A Practical Guide Using Statistical Software, First Edition(线性混合模型:统计软件的实际使用指南,第一版)。Chapman 和 Hall/CRC (34–36)。
- 固定效应检验方法
-
通常,您使用 Kenward-Roger 近似,因为这些计算包括会降低小样本数量偏倚的调整。您也可以使用 Satterthwaite 近似。通常,样本数量越大,两种方法之间的差异越小。
- 结果显示
-
- 因子信息
- 显示因子名称(无论因子是否随机)、水平数和水平的汇总。
- 迭代历史记录
- 显示算法收敛前的迭代次数和每次迭代的 –2 对数似然的值。
- 方差分量
- 显示方差分量的估计值。
- 方差分量估计值的方差-协方差矩阵
- 显示方差分量估计值的方差-协方差矩阵。
- 固定效应检验
- 显示有关固定效应的不同水平下的均值是否相等的假设检验。
- 随机效应预测
- 显示模型的随机项的统计量,其中包括随机项水平效应的最佳线性无偏预测 (BLUP)。
- 边际拟合方程
- 显示边际拟合值的方程。边际拟合值表示在输入协变量值(如果有)后,固定因子组合水平下的平均响应。边际拟合值的计算中不使用随机因子水平。
- 每组因子水平使用单独的方程:显示每个因子水平组合的单独方程。
- 单一方程:显示一个包含所有因子的所有水平的方程。
- 条件拟合方程
- 显示条件拟合值的方程。条件拟合是数据中随机因子水平的拟合值。使用条件拟合可以了解研究中随机因子的特定水平之间的差异。
- 每组因子水平使用单独的方程:显示每个因子水平组合的单独方程。
- 单一方程:显示一个包含所有因子的所有水平的方程。
- 边际拟合和诊断
-
- 仅用于异常观测值:只显示异常观测值的边际拟合值、边际残差以及诊断统计量。
- 适用于所有观测值:显示所有观测值的边际拟合值、边际残差以及诊断统计量。
- 条件拟合和诊断
-
- 仅用于异常观测值:只显示异常观测值的条件拟合值、残差以及诊断统计量。
- 适用于所有观测值:显示所有观测值的条件拟合值、残差以及诊断统计量。