方程语法
注意
计算列是作为顺序数据清理堆栈中的一个步骤创建的。由于计算列不包含公式,因此它们不会在每次更改工作表时重新计算值。
- 在 中打开您的数据集Minitab Data Center。
- 从标题栏打开 。
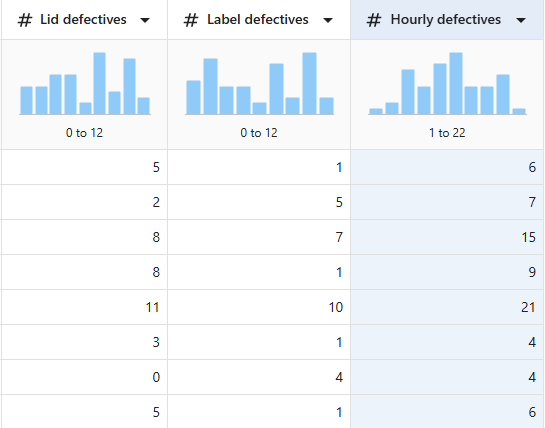
- 在 新列名中,输入 Hourly defectives。
- 在 方程中,输入 ='Lid defectives' + 'Label defectives'。
- 选择O确定。
- 重新打开 。
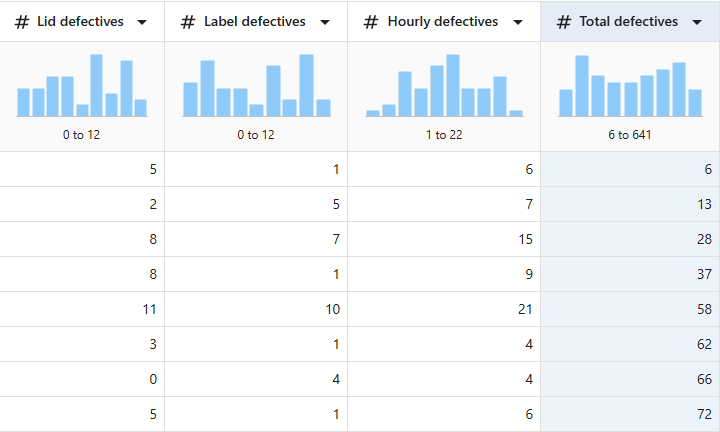
- 在 新列名中,输入 Total defectives。
- 在 插入函数下,选择Partial sum。
- 在 插入列 下,选择Hourly defectives。
=PARS('Hourly defectives’)
- 选择好的。
以下各节给出了所有受支持函数的基本语法信息。有关以下任何函数的更多信息,请转到 Minitab 支持网站上的计算器 函数 。
算术函数
- ABS(数字)
- absolute value 函数将所有负数更改为正数。正数和零不变。
- CEIL(数字,小数)
- ceiling 函数根据您指定的小数位数对数字进行四舍五入。对于数字,请指定要舍入的数字或数字列。对于小数,请指定要舍入到的小数位数。
- 如果小数 = 0,该数字将被舍入到大于或等于该数字的最近整数。
- 如果小数 > 0,该数字将向上舍入到小数点后指定的小数位数。
- 如果小数 < 0,该数字将向上舍入到 1 减去小数点左侧指定的位数值。
- COMBINATIONS(项数, 要选择的数字)
- combinations 函数计算一次选择 k 的 n 项的组合数。对于只有两个结果的试验(二项试验),可以在计算其 n 次试验中观测到 k 次事件(成功)的概率的公式中使用此函数。
为项数和要选择的数字指定一个数字或一列数字。项数必须大于或等于 1,要选择的数字必须大于或等于 0。
- FACTORIAL(项数)
- 阶乘函数计算从 1 到 n(含 1)的所有连续整数的乘积。表示法 ! 用于表示因子。例如,5! = 1* 2 * 3 * 4 * 5 = 120。按照定义,0! = 1。= 1.
number of items 的值必须大于或等于 0。您可以输入列或常量。不允许缺失值。
- FLOOR(数字,小数)
- floor 函数根据您指定的小数位数将数字向下舍入。对于数字,请指定要舍入的数字或数字列。对于小数,请指定要舍入的位数:
- 如果小数 = 0,该数字将被舍入到小于或等于该数字的最近整数。
- 如果小数 > 0,该数字将被舍入到小数点后指定的小数位数。
- 如果小数 < 0,该数字将向下舍入到 1 减去小数点左侧指定的位数值。
- GAMMA(形状)、IGAMMA(极限,形状)、LNGAMMA(形状)
- Gamma、不完全 Gamma 和 Gamma 的自然对数函数扩展了阶乘函数 (1 * 2 * 3...* n),以便除了正整数之外,还可以计算分数的阶乘。有时在计算中使用 Gamma 的自然对数函数而不是 Gamma 函数,因为 Gamma 的自然对数不太可能生成非常大的数字,这些数字可能大于存储容量并导致溢出。
对于形状,请指定要带入函数的数字。对于限值,请指定积分上限。
- MOD(数字,除数)
- 模函数计算数字除以除数后的余数。在标准表示法中,结果表示为 m = (MOD result) (mod n)。例如,MOD(23,10) 的结果表示为 23 = 3 (mod 10)。
数字和除数必须为整数或整数列。
- PARP(数字)
- 部分乘积函数将 input 列的前 i 行的乘积存储在存储列的第 i 行中。例如,如果输入列 c1 的前三行包含值 2、5 和 3,那么存储列的前三行将包含 2(等于 2 * 1)、10 (2 * 5) 和 30 (2 * 5 * 3)。
- PARS (数字)
- 部分求和函数通过将输入列的前 i 行的总和存储在另一列的第 i 行中来计算列中数字的运行总计。
- PERMUTATIONS (项数, 要选择的数)
- Permutations 函数查找一次选择 k 的 n 项的排列数。排列用来在只有两种可能结果的试验(二项试验)中计算事件的概率。
为项数和要选择的数字指定一个数字或一列数字。项数必须大于或等于 1,要选择的数字必须大于或等于 0。
- ROUND(数字,小数)
- round 函数根据您指定的小数位数对数字进行四舍五入。对于数字,请指定要舍入的数字或数字列。对于小数,请指定要舍入到的小数位数。
- 如果小数 = 0,该数字将被舍入到最近的整数。
- 如果小数 > 0,该数字将被舍入到小数点后指定的小数位数。
- 如果小数 < 0,该数字将被舍入到 1 减去小数点左侧指定的位数值。
- SIGN(数字)
- 符号函数将负数、零和正数分别转换为 −1、0 和 +1。您可以使用 signs 函数对列中的数字进行编码。此函数在宏、公式和非参数分析中非常有用。
对于数字,请指定要转换的数字或一列数字。
- SQRT(数字)
- 平方根函数计算所有非负数的平方根。例如,25 的平方根 = 5。
对于数字,请指定该数字或一列数字。如果输入一个负数,Minitab 将返回缺失值。
- FTC(计数)
- 变换计数函数执行 Freeman-Tukey 变换以稳定泊松数据(计数)的方差。例如,可以变换属性数据,使其满足回归或方差分析模型的假设。
对于计数,请指定只包含非负整数的一列或存储的常量。
- FTP(试验数,事件数)
- 变换比例函数执行 Freeman-Tukey 变换以稳定二项式数据的方差。例如,可以变换属性数据,使其满足回归或方差分析模型的假设。
指定试验数所代表的值和事件数所代表的值;每个数值都可以是列或已存储的常量。试验数必须是正整数。事件数必须是介于 0 和试验数(包含 0 和试验数)之间的整数。
列函数
- DIFFERENCES(数字, [滞后])
- differences 函数计算列中数值之间的逐行差异。
指定列,然后指定滞后值以确定逐行差异。此函数从每行中减去上面的元素滞后行,并将差异存储在新列中。如果没有为滞后指定值,将计算连续行之间的差值(滞后 = 1)。新列的前几个滞后行将包含缺失值符号 *。
- LAG(数字或文本,[滞后(Lag)])
- lag 函数将 input 列中的数据复制到 storage 列,并将每个值下移您指定的行数。
指定 input 列,然后指定数据应向下移动的行数。默认情况下,如果没有为滞后指定值,数据将向下移动一行(滞后 = 1)。缺失值符号 * 将添加到存储列的空行中。
- RANK(数字)
- rank 函数计算并存储输入列的排名。
在数字中,请指定列。此函数将排名分数分配给列中的值:将 1 分配给最小值,将 2 分配给下一个最小值,依此类推。对于结对值将分配该值的平均秩。缺失值留为缺失。经排秩的分值存储在一列中。
- SORT(列)
- sort 函数按升序对列中的数值进行排序。经排秩的分值存储在一列中。
指定要对其进行排序的列。数据必须为数字。
日期/时间函数
- CTIME()
- 当前时间函数将当前时间返回到日期/时间格式的列。
例如,要计算服务调用已打开的时间,请使用以下表达式:ELAPSED(CTIME () – column_name)。
- DATE(数字或文本)
- date 函数提取日期/时间值的日期部分。例如,“1/6/25 10:23”的日期部分为“1/6/25”。
- ELAPSED(数字)
- elapsed time 函数返回两个日期/时间值之间经过的时间。
对于数字,输入结束时间列减去开始时间列。这些列必须是日期/时间格式。如果输出列的最大值小于一小时,过去的时间将用分钟和秒 (mm:ss) 指定;如果输出列的最大值是一小时或更长,过去的时间将用小时、分钟和秒 (hh:mm:ss) 指定。
- NETWORKDAYS(开始日期,结束日期,[假期])
- net workdays 函数返回两个日期(含)之间的工作日 (M-F) 数。
当您输入单个日期时,还需要使用 DATE 函数。例如,要找出 1/1/25 和 1/31/25 之间的工作日数,请输入 NETWORKDAYS (DATE(“1/1/25”), DATE(“1/31/25”))。
- 现在()
- now 函数将当前日期和时间返回到日期/时间格式的列。
例如,要计算自收到初始调用以来的天数,请使用以下表达式:NOW() – column_name)。
- TIME(数字或文本)
- time 函数提取日期/时间值的时间部分。例如,“1/6/25 10:23”的时间部分是“10:23”。
- 今天()
- today 函数将当前日期返回到日期/时间格式的列。
例如,要计算账单未支付的时间,请使用以下表达式:TODAY() – column_name)。
- WHEN(数字或文本)
- when 函数将日期/时间值的日期和时间部分(如“01/06/25 10:23”)提取到具有日期/时间格式的列中。
- WDAY(开始日期,工作日天数,[假期])
- workdays 函数将日期偏移指定的工作日数。此功能对于快速修改工作表中的日期/时间数据列非常有用。
当您输入单个日期时,还需要使用 DATE 函数。例如,WDAY(DATE(“1/1/25”),4) 等于 2025 年 1 月 7 日。
对数函数
- ANTILOG(数字)
- 反对数函数计算 10n,其中 n 是指定的数字。例如,2 的反对数是 102 = 100。
- EXP(数字)
- 自然指数函数计算值 ex,其中 e 是自然对数的底数,大约等于 2.71828,x 是您输入的值。例如,5 的指数是 e5,大约等于 148.413。
- LOGTEN(数字)
- 以 10 为底的对数函数计算 10 必须提高到等于给定数字的指数。例如,102 = 100,因此 100 的对数基数 10 为 2。
十进制对数仅针对正数定义。当您将一个数字与 10 相乘,您将使其对数增大 1;当您将一个数字除以 10,您将使其对数减小 1。
- LN(数字)
- 自然对数 (对数以 e) 函数计算以 e 为底的对数,其中 e 是等于约 2.71828 的常数。任何正数 n 的自然对数都是指数 x,必须将 e 提高到该指数,以便 ex = n。例如,e2 = 7.389,因此 7.389 的自然对数为 2。
逻辑函数
- ANY(检验,常量,常量,...)
- 如果值等于一组值中的任何值,则 ANY 函数返回 1,否则返回 0。
例如,要在 C1 中标识值 3 的实例,请输入表达式 ANY(C1,3)。结果将存储在新列中。
C1 新建 6 0 3 1 2 0 3 1 3 1 - IF(检验,条件满足的值,[条件不满足的值])
- IF 函数根据条件是 true 还是 false 来选择要返回的两个值中的哪一个。
例如,要将 0 和 1 列更改为 “pass” 和 “fail”,请输入表达式 IF(C1=1,“fail”,“pass”)。结果将存储在新列中。
C1 新建 0 通过 1 失败 0 通过 1 失败 1 失败 - IF(检验,value_if_true,...,检验,value_if_true,[value_if_false])
- IF (general) 函数为按顺序计算的多个条件中的每一个条件返回一个值。
例如,要将数字 0-6 转换为“低”、“中”和“高”的评级,请输入表达式 IF(C1<=2,"low",C1<=4,"medium","high").结果将存储在新列中。
C1 新建 0 低 1 低 6 高 3 中 2 低
统计量函数
- GMEAN(数字)
- 几何平均值函数计算几何平均值,几何平均值是集中趋势的度量,它使用乘法而不是加法来计算数据的平均值。
对于由 n 个数字组成的一组数字,几何均值是这些数字的乘积的 n 次方根。例如,数字 2、3 和 14 的几何均值等于 (2 * 3 * 14)1/3 = (84)1/3 = 4.37952。
- MAX(数字) 或 MIN(数字)
- 标识出数据的最大值和最小值。
例如,计算沿列或跨行的最大值和/或最小值。
列 计算器表达式 结果 C1 包含 6、3、15 MAX(C1) 15 C1 包含 6、3、15 MIN(C1) 3 C1 包含 6,C2 包含 3,C3 包含 15 RMAX(C1) 15 C1 包含 6,C2 包含 3,C3 包含 15 RMIN(C1) 3 - MEAN(数字) 或 RMEAN(数字,数字,...)
- mean 函数计算算术平均值(所有观测值的总和除以观测值个数)。
例如,计算沿列或跨行的平均值。
列 计算器表达式 结果 C1 包含 6、3、15 MEAN(C1) 8 C1 包含 6,C2 包含 3,C3 包含 15 RMEAN(C1,C2,C3) 8 - MEDIAN(数字)或 RMEDIAN(数字,数字,...)
- 中位数函数计算数据的中间值:一半的观测值小于或等于它,一半的观测值大于或等于它。
例如,计算沿列或跨行的中位数。
列 计算器表达式 结果 C1 包含 6、3、15 MEDIAN(C1) 6 C1 包含 6,C2 包含 3,C3 包含 15 RMEDIAN (C1,C2,C3) 6 - NMISS(数字) 或 RMISS(数字)
- total nonmissing 函数计算包含缺失数据的单元格总数。
- N(数字) 或 RN(数字)
- total nonmissing 函数计算包含实际数据的单元格总数。
- COUNT(数字) 或 RCOUNT(数字)
- total count 函数计算观测值总数(缺失值和非缺失值的总和)。
- NSCORES(数字)
- normal scores 函数提供 normality 下有序数据的预期值。这些分值可用于生成正态概率图和各种检验。
- PERCENTILE(数字,概率)
- percentile 函数计算指定概率和一组数字的样本百分位数。百分位数将数据集划分为若干部分。通常,第 n 个百分位数有 n% 的观测值位于它之下,(100-n)% 的观测值位于它之上。
例如,要确定一个数据列的第 1 个四分位数(第 0.25 个百分位数),请输入列号和概率 .25。
列 计算器表达式 结果 C1 包含 2、3、5 和 7 PERCENTILE (C1,0.25) 2.25 - RANGE(数字) 或 RRANGE(数字,数字,...)
- range 函数计算最大值和最小值之间的差值。
例如,计算沿列或跨行的范围。
列 计算器表达式 结果 C1 包含 6、3、15 RANGE(C1) 12 C1 包含 6,C2 包含 3,C3 包含 15 RRANGE(C1,C2,C3) 12 - STDEV(数字) 或 RSTDEV(数字,数字,...)
- 标准差函数度量关于平均值的离差 (数据的展开程度)。极差通过从最大值中减去最小值来估计数据的散布,而标准差则近似估计单个观测值与平均值的“平均”距离。标准差越大,数据越分散。
例如,计算沿列或跨行的标准差。
列 计算器表达式 结果 C1 包含 6、3、15 STDEV(C1) 6.245 C1 包含 6,C2 包含 3,C3 包含 15 RSTDEV(C1,C2,C3) 6.245 - SUM(数字) 或 RSUM(数字,数字,...)
- sum 函数计算 sum,这是两个或多个数字相加的结果。
例如,对一列或跨行求和。
列 计算器表达式 结果 C1 包含 6、3、15 SUM(C1) 24 C1 包含 6,C2 包含 3,C3 包含 15 RSUM(C1,C2,C3) 24 - SSQ(数字) 或 RSSQ(数字,数字,...)
- 平方和函数对每个值进行平方处理,并计算这些平方值的总和。也就是说,如果列包含 x 1、x 2、..., x n,则平方和计算 (x12 + x22 + ...+ xn2) 的 2 个实例。
例如,计算沿列或跨行的平方和。
列 计算器表达式 结果 C1 包含 6、3、15 SSQ(C1) 270 C1 包含 6,C2 包含 3,C3 包含 15 RSSQ(C1,C2,C3) 270
文本函数
- CLEAN(文本)
- clean 函数会删除所有不可打印的字符。当您从外部源导入文本时,不可打印的字符可能会嵌入到文本中。
- CONCATENATE(文本,文本,...)
- concatenate 函数将两个或多个文本列并排合并,并将它们存储在新列中。
- FIND(待查找的文本, 包含要查找关键字的文本,[开始字号])
- find 函数标识文本字符串在不同文本字符串中的起始位置。Find 类似于 Search,不同点是 Find 区分大小写;例如,它区分 b 和 B。
您可以使用星号 (*) 作为通配符,表示由一个或多个字符组成的字符串。问号 (?) 也是通配符,但它只表示一个字符,而不是一串字符。要在文本字符串中引用 “*” 或 “?” 字符,请在符号前使用波浪号 (~)。
- FIXED(数字,[小数],[无数字分组符号])
- fixed 函数将数字四舍五入到指定的小数位数,并将其转换为带或不带逗号的文本。对于数字,请指定要舍入的数字或数字列。对于小数,请指定要保留的位数。
- 如果 decimals = 1,则值舍入到最接近的十分之一。
- 如果 decimals = 0,则值四舍五入到最接近的整数。
- 如果 decimals = -1,则值四舍五入为 10 的倍数。
- 如果不输入第二个参数,则 value 将四舍五入到小数点后 2 位。
- HTOD(文本)
- hex to decimal 函数将十六进制值转换为其等效的十进制形式。
- ITEM(文本,字符编号,[分隔符])
- item 函数从文本字符串中提取第 n 个单词。
例如,如果一列中包含由逗号分隔的姓氏和名字,则可以提取从文本字符串开头到逗号之间的所有字符(这些字符构成姓氏)。
- LEFT(文本,num_chars) 或 RIGHT(文本,num_chars) 或 MID(文本,start_num,[num_chars])
- left 函数从文本字符串的开头返回指定数量的字符。right 函数从文本字符串的末尾返回指定数量的字符。mid 函数在给定子字符串的起始位置和长度的情况下,返回文本字符串中的字符子字符串。
- LEN(文本)
- length 函数标识文本字符串中的字符数。
- UPPER(文本)或 LOWER(文本)或 PROPER(文本)
- upper 函数将所有字母转换为大写 (大写字母)。lower 函数将所有字母转换为小写。正确的函数将每个单词中的第一个字母大写,并将所有其他字符转换为小写。
列 计算器表达式 结果 C1 包含“defective” UPPER(C1) DEFECTIVE C1 包含“DEFECTIVE” LOWER(C1) defective C1 包含“defective” PROPER(C1) 不良品 - PAD(文本,字符数)
- pad 函数使用尾随空格填充文本。对于 text,请指定文本或文本值列。对于 num_chars,输入文本和尾部空格所需的字符总数。填充是字符总数减去文本中的字符数。
- REPT(文本,次数)
- repeat 函数将文本重复指定的次数。对于文本,请指定文本或文本列。对于 number_times,请指定文本的重复次数。
- REPLACE(old_text,start_num,num_chars,new_text) 或 SUBSTITUTE(text,old_text,new_text,[instance_num])
- replace 函数替换文本字符串中的文本子字符串。substitute 函数将现有文本替换为新文本,并允许您指定如果文本在单个条目中多次出现时,要替换原始文本的哪个匹配项。
- SEARCH(待查找的文本, 包含要查找关键字的文本,[开始字号])
- 搜索函数标识文本字符串在另一个文本字符串中的初始位置。Search 类似于 Find,不同点是 Search 不区分大小写,例如,它不区分 b 和 B。
列 计算器表达式 结果 C1 包含“234B75” SEARCH("b7",C1) 4(因为 B7 从文本中的第 4 个位置开始) C1 包含“depreciate” SEARCH( "c*t",C1) 6 C1 包含“Item# C-222-T” SEARCH( "c*t",C1) 7 C1 包含“defective” SEARCH( "c*t",C1) 5 C1 包含“814*231*2682” SEARCH( "~*",C1) 4 - TEXT(数字)
- text 函数将数字或日期/时间列或值转换为文本列。将数值转换为文本允许您使用文本作函数编辑和作值。
- TRIM(文本)
- trim 函数会删除除单词之间单个空格之外的所有空格。
- VALUE(文本)
- value 函数将包含数字的文本列转换为数字列。在将包含数字的文本列转换为数字列之后,可以针对这些数据执行数学运算。
- WORD(文本,字符编号,[分隔符])
- value 函数从文本字符串中提取第 n 个单词。例如,如果一列中包含由逗号分隔的姓氏和名字,则可以提取从文本字符串开头到逗号之间的所有字符(这些字符构成姓氏)。
注意
字函数类似于项函数,但不同的是项函数提取出现在两个连续分隔符(例如逗号和空格)之间的空白文本,而字函数忽略空白字符串并提取跟在连续分隔符之后的文本。
三角法函数
- ACOS(数字)
- 反余弦函数确定与指定余弦对应的角度。反余弦用 0 到 π 的弧度定义。
例如,...0.5 的反余弦为 π/6 或 ....5230 弧度。反余弦(又称为逆正弦)可以用 cos−1 x、arccos x 或 acos x 来表示。
- ACSH(数字)
- 双曲反余弦函数计算值的双曲反余弦。
- ASIN(数字)
- 反正弦函数确定与指定正弦对应的角度。反正弦以 −π/2 到 π/2 的弧度定义。
例如,反正弦 0.5 是 π/6 或 0.5230 弧度。反正弦又称为逆正弦,可以用 sin−1 x、arcsin x 或 asin x 表示。
- ASNH(数字)
- 双曲反正弦函数计算值的双曲反正弦。
- ATAN(数字)
- arctangent 函数确定与指定切线对应的角度。
例如,1 的反正切是其正切等于 1 的角,或者角 π/4(...785398 弧度)。反正切又称为逆正切,可以用 tan−1 x、arctan x 或 atan x 表示。
- ATNH(数字)
- 双曲反正切函数计算值的双曲反正切值。
- COS(以弧度表示的角度)
- 直角三角形的锐角的余弦是相邻直角边与斜边(正对直角的最长边)的比值,用弧度来度量。
- COSH(数字)
- 双曲余弦函数计算角度的双曲余弦。
- DEGREES(以弧度表示的角)
- degrees 函数将弧度更改为度数。弧度和角度是用来标识角大小的度量单位。以弧度来度量角时,角等于角顶点位于单位圆中心时弧的长度。
- RADIANS(以角度表示的角)
- 弧度函数将度数更改为弧度。此计算器中的三角函数需要以弧度为单位的角度测量。弧度和度数是用于表示角度大小的度量单位。以弧度来度量角时,角等于角顶点位于单位圆中心时弧的长度。
- SIN(以弧度表示的角度)
- 直角三角形锐角的正弦是对边与斜边(最长的边,直角的对边)的比值,用弧度来度量。
- SINH(数字)
- 双曲正弦函数计算角度的双曲正弦。
- TAN(以弧度表示的角度)
- 角度的正切是其正弦与余弦的比值。对于直角三角形的锐角,这等效于对边长度与邻边长度之间的比值,用弧度来度量。
- TANH(数字)
- 双曲正切函数计算角度的双曲正切。
行统计函数
最大值、平均值、中值、最小值、缺失、非缺失、总计、范围、标准差、总和平方和的行统计信息的语法详细信息如统计函数所示。
常量函数
- E()
- e 函数插入常量 e,四舍五入到小数点后六位 (2.718281)。e 是自然对数函数的基数。常数 e 是一个无理数,由无限和的 1/0 定义!+ 1/1! + 1/2! + 1/3! + 1/4! + 1/5!...
- 失误()
- 缺失数据代码函数插入常量 *(缺失值符号)。
- PI()
- pi 函数插入常数 π,四舍五入到小数点后六位 (3.141592)。Pi 是圆的周长与其直径的比值。