图形生成器
使用 可视化 图形生成器 数据并探索图形替代方案。根据您的输入,将显示 图形生成器 可用候选图表的预览。在浏览图表库时,您可以选择一个候选图表,然后为所选图表设置选项,以实时查看更改的效果。
主要领域
- 1:列选择器面板
- 活动工作表中的列列表。
- 2:源数据面板
- 可用的输入字段以及与所选图表关联的任何显示选项。
- 3:候选人名单
- 所有可用图表的完整列表。
- 4:帆布
- Minitab 显示图形预览的区域。
技巧
- 要使用鼠标输入变量,请单击列选择器面板中的变量,然后将其拖动到源数据面板中的输入字段。
- 要使用键盘输入变量,请单击输入字段 或 Tab 键,然后键入要输入的变量的列名或列号,例如 C1 或 Flaws。
- 要重新排列图表上变量的顺序,请单击输入字段中的变量,然后将其拖动到同一字段中的新位置或源数据面板中的其他字段。
- 要从源数据面板中删除变量,请单击
 或选择变量并按 删除 键。
或选择变量并按 删除 键。
直方图
使用 Histogram 检查数据的形状和分布。当样本数量最少为 20 时,直方图效果最佳。
连续变量
输入要绘制图表的一个或多个数字列。
组变量
输入定义组的变量。组标签显示在图形图例中。
Y 尺度
- 频率
- 每个条形的高度表示落入直方图区间内的观测值数。
- 百分比
- 每个条形的高度表示位于区间的样本观测值的百分比。具有百分比尺度的直方图有时称为相对频率直方图。使用百分比尺度可以比较不同数量的样本。
概率图
使用概率图可以评估分布与数据的拟合度、估计百分位数以及比较样本分布。概率图显示每个值以及样本中小于或等于该值的值所占的百分比。可以变换 y 轴,以使拟合分布形成一条直线。
连续变量
输入要绘制图表的一个或多个数字列。
组变量
输入定义组的变量。组标签显示在图形图例中。
分布
箱线图
使用箱线图评估并比较样本分布的形状、集中趋势和变异性,并查看异常值。当样本数量最少为 20 时,箱线图效果最佳。
连续变量
输入要绘制图表的一个或多个数字列。
类别变量 可选
输入最多五列定义组的分类数据。第一个变量是尺度上的最外层,最后一个变量是最内层。
须触线和异常值
- 抖散异常值
- 如果图表上的数据值相同,则离群值符号可能会相互隐藏。选择此选项可稍微移动元件以显示重叠点。
自定义百分位数
对于大型数据集,且异常值较多,你可以显示自定义百分位数而非异常值,以收集更多数据信息。自定义百分位数出现在四分位数框之外,通常出现在分布的尾部。此外,线条将放置在最小值和最大值处。默认情况下,这些百分位数值为 0.5、2.5、10、90、97.5 和 99.5,但您可以添加、删除或更改它们。
Y 尺度
- 原始单位
- 对数值变量使用原始度量单位。
- 标准化单位
- 将不同的度量单位转换为标准单位,以使数值变量具有可比性。
变量显示顺序
对于图形上所显示的组,Minitab 使用“最内层”和“最外层”这两个词来指示多个水平的尺度的相对位置。对于水平尺度,最外层是指图形底部的尺度,最内层是指离底部最远的尺度(离水平轴最近)。对于垂直尺度,最外层是指最左侧的尺度,最内层是指离垂直轴最近的尺度。
- 首先为类别变量,Y 在下方
- 图形变量是最外层的组,类别变量是最内层的组。
- 首先为 Y,类别变量在下方
- 图形变量是最内层的组,类别变量是最外层的组。
区间图
使用区间图可以评估和比较组均值的置信区间。区间图显示每个组均值的 95% 置信区间。当样本数量为每组至少 10 个时,区间图效果最佳。通常,样本数量越大,置信区间越小且精确度越高。
连续变量
输入要绘制图表的一个或多个数字列。
类别变量 可选
输入最多五列定义组的分类数据。第一个变量是尺度上的最外层,最后一个变量是最内层。
置信区间
指定置信区间的设置。
- 置信水平
- 输入置信区间的置信水平。通常,置信水平为 95% 即可。95% 置信水平表明,如果从总体中随机抽取 100 个样本,则大约 95 个样本的置信区间中将包含总体参数。
- 使用 Bonferroni 方法
- 用于控制一整组置信区间的整体置信水平的方法。在检验多个置信区间时考虑整体置信水平很重要,因为对于一组置信区间来说,其中至少一个置信区间不包含总体参数的几率大于任何单个区间的几率。为解决这一较高的误差率,Bonferroni 方法会调整每个单个区间的置信水平,以使所获得的整体置信水平等于您指定的值。
- 双侧
- 使用双侧置信区间来估计均值的可能下限和上限。
- 上部单侧
- 使用置信下限来估计平均值的可能较低值。
- 下部单侧
- 使用置信上限来估计平均值可能较高的值。
- 使用合并标准差
- 选择何时可以假定所有总体具有相等的方差。
Y 尺度
- 原始单位
- 对数值变量使用原始度量单位。
- 标准化单位
- 将不同的度量单位转换为标准单位,以使数值变量具有可比性。
变量显示顺序
对于图形上所显示的组,Minitab 使用“最内层”和“最外层”这两个词来指示多个水平的尺度的相对位置。对于水平尺度,最外层是指图形底部的尺度,最内层是指离底部最远的尺度(离水平轴最近)。对于垂直尺度,最外层是指最左侧的尺度,最内层是指离垂直轴最近的尺度。
当您有多个 Y 变量具有组时,请选择以下选项之一。
- 首先为类别变量,Y 在下方
- 图形变量是最外层的组,类别变量是最内层的组。
- 首先为 Y,类别变量在下方
- 图形变量是最内层的组,类别变量是最外层的组。
单值图
使用单值图可以评估和比较样本数据分布。单值图对于一个组中每个观测值的实际值显示一个点,这便于发现异常值并查看分布的散布。
连续变量
输入要绘制图表的一个或多个数字列。
类别变量 可选
输入最多五列定义组的分类数据。
抖散单值符号
如果图表上的数据值相同,则各个交易品种可能会相互隐藏。选择此选项可稍微移动元件以显示重叠点。
Y 尺度
- 原始单位
- 对数值变量使用原始度量单位。
- 标准化单位
- 将不同的度量单位转换为标准单位,以使数值变量具有可比性。
变量显示顺序
对于图形上所显示的组,Minitab 使用“最内层”和“最外层”这两个词来指示多个水平的尺度的相对位置。对于水平尺度,最外层是指图形底部的尺度,最内层是指离底部最远的尺度(离水平轴最近)。对于垂直尺度,最外层是指最左侧的尺度,最内层是指离垂直轴最近的尺度。
- 首先为类别变量,Y 在下方
- 图形变量是最外层的组,类别变量是最内层的组。
- 首先为 Y,类别变量在下方
- 图形变量是最内层的组,类别变量是最外层的组。
变异性控制图
使用变异性控制图作为调查数据变异(包括周期变异和因子之间交互作用)的初步工具。变异性控制图显示因子和响应之间的关系。每个图都显示多达八个因子。有关数据注意事项、示例和解释的信息,请转到变 异性图表概述。
响应变量
输入一个包含测量数据的数值列。
因子
输入包含因子水平的列。第一个变量是尺度上的最外层,最后一个变量是最内层。最多可以有 8 个因子。
数据表示法
- 单数据点
- 在平均响应及变异图上绘制各个数据点。
- 每个单元格的极差
- 显示连接每个因子水平组合的最小和最大数据点的每个范围条。
- 单元格均值的连接线
- 添加一条线来连接因子水平组合的均值。
- 整体均值
- 在平均响应及变异图上的总体均值处显示一条水平线。
- 因子均值
- 在“带变异”图的平均响应中,在因子的平均值处显示一条水平线。
尺度
- 对数变换: Y 尺度
-
对数尺度通过更改轴来将对数关系线性化,以便同一个距离表示尺度上不同的值变化。例如,在具有未变换 Y 尺度的散点图中,该函数不是线性的。当您将 Y 尺度转换为以 e 为底的对数时,数据的形式是线性的。
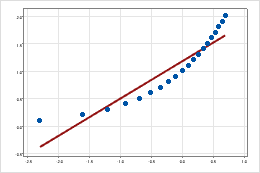
未变换的 Y 尺度
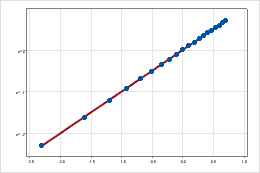
转换后的 Y 尺度(以 10 为底的对数转换)
线条图
用于 线条图 比较函数或序列的响应模式。您可以根据要比较的组数或序列长度,创建一个包含符号或不含符号的线条图。
汇总变量
输入定义折线图中点的列。
从 函数 中选择 汇总变量 的函数。例如,如果您选择 最大值,Minitab 将根据汇总变量的最大值定义图形的颜色。如果在 中 汇总变量输入文本列,则只能选择 等于指定值的百分比、 非缺失值数或 缺失值数。
- 百分位数
- 如果选择 百分位数,则必须在 百分位数值 中输入值。值必须在 0 和 100 之间。Minitab 使用您输入的值来定义图形中的颜色渐变。例如,如果您输入 50,Minitab 将使用第 50 个百分位数来定义图形上每个点的颜色渐变。
- 两个值之间的百分比
- 如果选择 两个值之间的百分比,则必须在 和 第二个值中 第一个值 输入数值。您为 第一个值 输入的值必须小于或等于您为 第二个值 输入的值。Minitab 根据两个值之间的观测值百分比定义图形的颜色渐变。
- 等于指定值的百分比
- 如果选择 等于指定值的百分比,则必须在 值 中输入一个或多个值。这些值必须与在 汇总变量 中输入的列具有相同的数据类型。Minitab 根据与您输入的值相等的观测值的百分比定义graphs图的颜色梯度。
类别变量
输入定义 x 轴的分类变量。
图例组
当您输入 multiple 汇总变量时,多个汇总变量将叠加在同一图表上。选择 类别形成图例组 以使 的组 连续变量 形成图例,并将您指定的 汇总变量 列形成 x 轴。选择 汇总变量形成图例组 以将您指定的列以图例的形式,将指定的 汇总变量 组 连续变量 以 x 轴的形式显示。
组变量
输入定义组的变量。组标签显示在图形图例中。
显示符号
选择以在 x 轴上的每个点上显示一个符号。如果不选择此选项,则图表将仅显示线条。
显示函数为总计的百分比
选择此选项可将 Y 比例类型更改为百分比。
Pareto 图
用于 Pareto 图 识别最常见的缺陷、最常见的缺陷原因或最常见的客户投诉原因。Pareto 图可帮助着重改进能获得最大收益的方面。
缺陷或属性数据
输入包含原始数据或摘要数据的列。如果有一列原始数据,请输入该列。如果有汇总数据,请输入包含缺陷名称的列。
如果使用文本数据,请确保缺陷名称的前 15 个字符不同。
汇总变量 可选
输入包含摘要数据计数的数字列。
超过此累积百分比后合并剩余缺陷
Minitab 为缺陷类别生成条形,直到累积百分比超过指定的百分比。然后,Minitab 会将剩余缺陷分组到名为“其他”的类别中。
显示百分比尺度和累积线
选择此选项可显示累积百分比符号、连接线和百分比刻度。
条形图
使用条形图可以比较计数、平均值或其他汇总统计量,使用条形来表示组或类别。条形的高度显示组的 count 或 variable 函数。
类别变量
输入要绘制图表的一个或多个数字列。
汇总变量 可选
输入定义条形图中的条形的数字或文本列。
函数
从 函数 中选择 汇总变量 的函数。例如,如果选择 最大值,Minitab 将根据每个条形中汇总变量的最大值定义条形图的颜色。如果在 中 汇总变量输入文本列,则只能选择 等于指定值的百分比、 非缺失值数或 缺失值数。
- 百分位数
- 如果选择 百分位数,则必须在 百分位数值 中输入值。值必须在 0 和 100 之间。Minitab 使用您输入的值来定义条形图中的颜色渐变。例如,如果您输入 50,Minitab 将使用第 50 个百分位数来定义条形图每个矩形的颜色渐变。
- 两个值之间的百分比
- 如果选择 两个值之间的百分比,则必须在 和 第二个值中 第一个值 输入数值。您为 第一个值 输入的值必须小于或等于您为 第二个值 输入的值。Minitab 根据两个值之间的观测值百分比定义条形图的颜色渐变。
- 等于指定值的百分比
- 如果选择 等于指定值的百分比,则必须在 值 中输入一个或多个值。这些值必须与在 汇总变量 中输入的列具有相同的数据类型。Minitab 根据等于您输入的值的观测值的百分比定义条形图的颜色渐变。
重叠
当您选择多个类别变量并选择叠加图形时,您可以选择如何显示叠加的条形。
- 与均匀间隔的条形重叠
- 默认情况下,Minitab 沿轴均匀显示条形。分类组按照它们在 中的 类别变量显示顺序沿轴的不同级别显示。
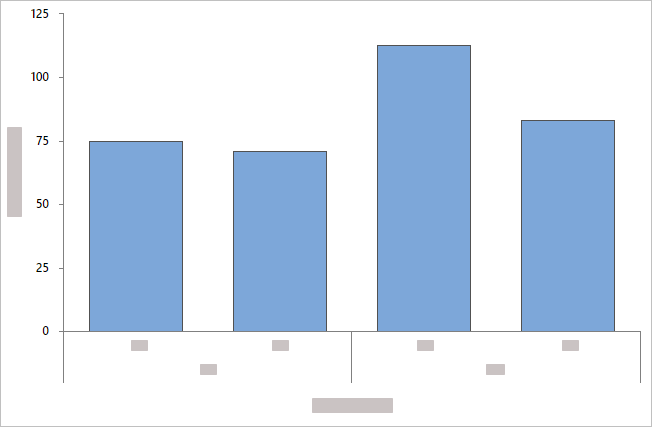
- 与聚类的条形重叠
- Minitab 将类别组显示为簇状条形,并包含一个图例。您可以通过对 中的 类别变量变量重新排序来更改分组,也可以从 变量聚类中选择其他变量。
- 与堆叠的条形重叠
- Minitab 将类别组显示为堆叠条形,并包含一个图例。您可以通过对 中的 类别变量变量重新排序来更改类别的显示级别,也可以从 变量聚类中选择其他变量。
注意
当您有多个汇总变量并选择叠加图形时,您可以选择按汇总变量对条形进行聚类或堆叠。
按汇总变量聚类
按汇总变量堆叠
条形排序依据
- 默认值
- 默认情况下,当您绘制唯一值或变量函数的计数时,Minitab 会按类别名称(例如:第 1 组、第 2 组、第 3 组)。
- 递增 Y
- 根据 Y 值按升序排列条形。
- 递减 Y
- 根据 Y 值按降序排列条形。
显示计数为总计的百分比
如果未输入 汇总变量,请选择此选项可将 Y 刻度类型从 count 更改为 percent。
显示函数为总计的百分比
输入 汇总变量时,选择此选项可将 Y 刻度类型更改为百分比。
相同的 Y 尺度
使 Y 标度在多个图形中相同。
变量显示顺序
对于图形上所显示的组,Minitab 使用“最内层”和“最外层”这两个词来指示多个水平的尺度的相对位置。对于水平尺度,最外层是指图形底部的尺度,最内层是指离底部最远的尺度(离水平轴最近)。对于垂直尺度,最外层是指最左侧的尺度,最内层是指离垂直轴最近的尺度。
- 首先为类别变量,Y 在下方
- 图形变量是最外层的组,类别变量是最内层的组。
- 首先为 Y,类别变量在下方
- 图形变量是最内层的组,类别变量是最外层的组。
饼图
用于 饼图 比较每个类别或组中数据的比例。饼图是一个圆圈(“饼图”),它被划分为多个段(“切片”),以表示每个类别中观测值的比例。
类别变量
输入要绘制图表的一列或多列分类数据。
汇总变量 可选
输入要绘制图表的一列或多列汇总值。
显示类型
- 饼形
-
- 环形
- 半圆
扇形区排序依据
- 默认值
- 如果仅 类别变量输入 ,Minitab 将按字母顺序显示切片。如果您还输入 汇总变量,Minitab 将按照与工作表中出现的顺序 类别变量 相同的顺序显示切片。您可以通过为 类别变量.要更改文本列中值的顺序,请转到 更改 Minitab 输出中文本值的显示顺序。
- 增大面积
- 按从小到大的顺序排列扇形区。
- 减小面积
- 按从大到小的顺序排列扇形区。
合并此百分比或以下的扇形区
输入单独切片的最小百分比。小于此百分比值的类别将被组合为一个称为“其他”的扇形区。
散点图
使用散点图可以调查一对连续变量之间的关系。散点图在一个坐标平面中显示多对经过排序的 X 和 Y 变量。
变量
您可以将 x 和 y 变量绘制为单独的对,也可以绘制 x-y 变量的每个组合。y 变量是要解释或预测的变量。x 变量是可以解释或预测 y 变量变化的相应变量。所有列必须是数字,列,而且每个 x-y 变量对包含的行数必须相等。
首先,选择以下选项之一。
- 每个 Y 与每个 X
- 选择此项可为您输入的 x 和 y 变量的每个可能组合显示单独的图形。
- XY 配对
- 选择此项可为您输入的每对 x 和 y 变量显示单独的图形。每个 x-y 变量对必须具有相同的行数。
然后,输入变量。
- Y 变量
- 选择要解释或预测的变量。
- X 变量
- 选择可能解释或预测 Y 变量变化的变量。
组变量
输入定义组的变量。组标签显示在图形图例中。
对数变换
- 对数变换: Y 尺度
- 选择以使用对数基数 10 变换 Y 刻度。
- 对数变换: X 尺度
- 选择以 10 为底的对数变换 X 尺度。
区间散点图
使用分箱散点图可以调查数据集包含许多观测值时一对连续变量之间的关系。
变量
y 变量是要解释或预测的变量。x 变量是可以解释或预测 y 变量变化的相应变量。所有列必须是数字,列,而且每个 x-y 变量对包含的行数必须相等。
- Y 变量
- 选择要解释或预测的变量。
- X 变量
- 选择可能解释或预测 Y 变量变化的变量。
由均值定义的梯度
选择此选项可使用第三个变量的值定义梯度尺度。
梯度类型
选择区间的颜色尺度。
- 发散
- 具有较高值的区间为红色,具有较低值的区间为蓝色。在 梯度沿值对称中,输入一个值以将梯度刻度居中于特定值,而不是分箱数据的频率中心。
-

- 从低到高的顺序
- 具有较高值的区间为深蓝色,具有较低值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较高生产率的区间或者最大化收入。

- 从高到低的顺序
- 具有较低值的区间为深蓝色,具有较高值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较低缺陷率的区间或者最小化收入。

对数变换
- 对数变换: Y 尺度
- 选择以使用对数基数 10 变换 Y 刻度。
- 对数变换: X 尺度
- 选择以 10 为底的对数变换 X 尺度。
气泡图
使用气泡图可以探索两个变量之间的关系,其中每个符号或气泡的大小表示第三个变量的大小。
变量
y 变量是要解释或预测的变量。x 变量是可以解释或预测 y 变量变化的相应变量。所有列必须是数字,列,而且每个 x-y 变量对包含的行数必须相等。
- Y 变量
- 选择要解释或预测的变量。
- X 变量
- 选择可能解释或预测 Y 变量变化的变量。
气泡大小
输入确定气泡大小(面积)的列。
布局
选择布局选项。
- 每个 XY 配对的单独图形
- 为每个 XY 对创建一个单独的散点图。
- 重叠 XY 配对
- 每个 XY 对都叠加在单个散点图上。
组变量
输入定义组的变量。组标签显示在图形图例中。
对数变换
- 对数变换: Y 尺度
- 选择以使用对数基数 10 变换 Y 刻度。
- 对数变换: X 尺度
- 选择以 10 为底的对数变换 X 尺度。
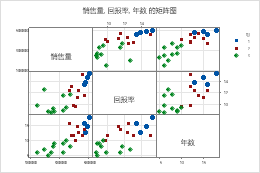
矩阵图
使用矩阵图同时评估几对变量之间的关系。矩阵图是散点图的阵列。您可以选择 图矩阵,以便为每个可能的变量组合创建一个图。或者,您可以选择 每个 Y 与每个 X 以为每个可能的 xy 组合创建一个绘图。
图的矩阵
在 连续变量中,输入具有相同行数的数值数据列。Minitab 对于每个变量组合显示一个散点图。
在此工作表中, 回报率、 销售额 和 年 是图形变量。该图显示了每个可能的图形变量组合之间的关系。
| C1 | C2 | C3 |
|---|---|---|
| 回报率 | 销售 | 年限 |
| 15.4 | 50400200 | 18 |
| 11.3 | 42100650 | 15 |
| 9.9 | 39440420 | 12 |
| ... | ... | ... |
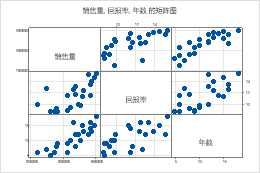
每个 Y 与每个 X
在 Y 变量中,输入要解释或预测的数值数据列。在 X 变量中,输入可能解释 Y 变量变化的数值数据列。
在此工作表中, Rate of Return 和 Sales 是 Y 变量, Years 是 X 变量。图形显示每个 Y 变量与每个 X 变量之间的关系。
| C1 | C2 | C3 |
|---|---|---|
| 回报率 | 销售 | 年限 |
| 15.4 | 50400200 | 18 |
| 11.3 | 42100650 | 15 |
| 9.9 | 39440420 | 12 |
| ... | ... | ... |
布局
选择 完整矩阵 此项可同时显示矩阵的左下半部分和右上半部分。这两个部分显示相同的数据,但是数据的轴相反。例如,出现在矩阵左下角的 x 轴上的变量显示在右上部分的 y 轴上。
完整矩阵
左下
右上
组变量
输入定义组的变量。组由不同的颜色和符号表示。例如,下面的矩阵图显示了变量 Rate of Return、 Sales 和 Years的每个可能组合之间的关系,分为三组。
变量标签位置
对角
边界
尺度
在多图形中使用相同的尺度。
- 相同的 Y 尺度
- 在所有图形中使用相同的 y 尺度。
- 相同的 X 尺度
- 在所有图形中使用相同的 x 尺度。
相关图
用于 相关图 可视化和比较变量对之间线性关系(相关性)的强度和方向。
连续变量
输入包含数据的列。必须输入至少两个数字数据列。每个列中包含的行数必须相等。
梯度类型
选择区间的颜色尺度。
- 自动
- 当您选择 自动 时,梯度类型取决于 Pearson 相关系数的计算。
- 如果系数中有正数和负数,梯度类型 则为 沿 0 对称发散。
- 如果系数都是正数,梯度类型 是 从低到高的顺序。
- 如果系数都是负数,梯度类型 是 从高到低的顺序。
- 发散
- 具有较高值的区间为红色,具有较低值的区间为蓝色。在 梯度沿值对称中,输入一个值以将梯度刻度居中于特定值,而不是分箱数据的频率中心。
-
- 从低到高的顺序
- 具有较高值的区间为深蓝色,具有较低值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较高生产率的区间或者最大化收入。
- 从高到低的顺序
- 具有较低值的区间为深蓝色,具有较高值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较低缺陷率的区间或者最小化收入。
显示相关值
选择在图形的每个矩形中显示 Pearson 相关系数的值。
平行坐标图
使用平行坐标图可以直观地比较多个变量中平行坐标上的多个序列或序列组。
变量
至少输入两列数值数据。
行标签
输入包含每个系列的标签的列。当您将鼠标悬停在图上时,Minitab 将使用此列为图上的系列加标签。如果您未输入组变量Minitab 将使用标签列为平行图创建图例。
布局
选择以下布局选项之一。
- 单个序列
- 创建针对工作表中每行显示一个系列的平行图。工作表必须至少包含两个数字数据列。
- 按组列出单个序列
- 创建一个平行图,该图针对工作表中的每行显示一个系列,并针对分组变量的每个级别使用相同的颜色。工作表必须至少包含两个数字数据列和一个包含这些组的列。
- 汇总组
- 创建一个平行图,该图显示工作表中每个组(而不是每一行)的每个序列的平均值。工作表必须至少包含两个数字数据列和一个包含这些组的列。
组变量
输入定义组的变量。组标签显示在图形图例中。选择按组列出单个序列或汇总组时必须输入列。
Y 尺度
选择 y 刻度的显示方式。
- 范围百分比
-
选择此选项可绘制每个具有唯一 y 尺度的变量。包含每个变量的所有最小值或最大值的序列将是水平的
线。
- 标准单位
-
选择此选项可绘制每个具有唯一 y 尺度的变量。每个尺度的最小值和最大值是您输入的所有数据的整体最小 z 分值和最大 z 分值(转换为每个变量的尺度)。
例如,第一变量的最大值的 z 分值为 2,而另两个变量的最大值的 z 分值为 1。每个变量的 y 尺度的最大值是对应于 z 分值 2 的值。
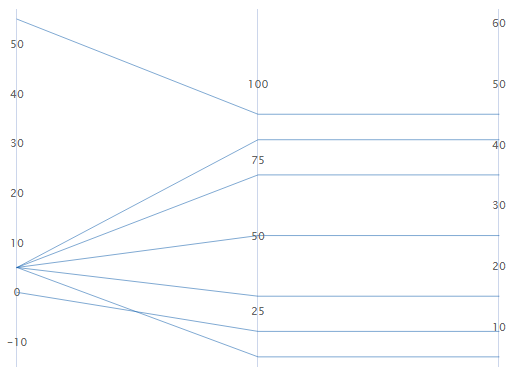
- 原始数据
-
选择此选项可使用单个针对每个变量重复的 y 尺度。尺度的最小值和最大值是您输入的所有数据的整体最小值和最大值。
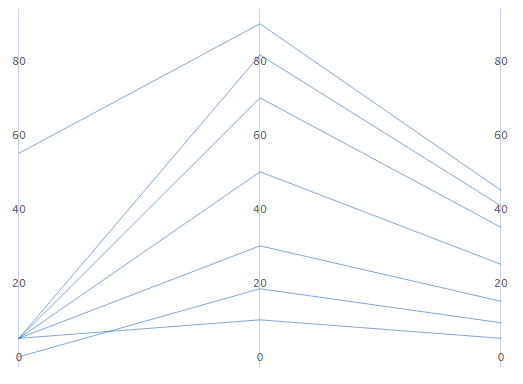
对线条中的变量按最大到最小变异进行排序
如果选择标准单位或原始数据,可以根据变异对变量进行排序。当您有许多变量并且想要查看哪个变量使系列最分散时,这非常有用。如果您未选择此选项,Minitab 会按照您在变量对话框中输入列的顺序对列进行排序。
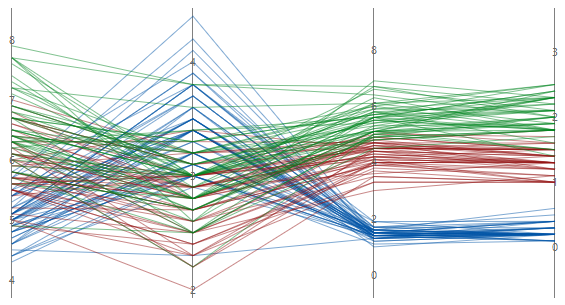
未排序
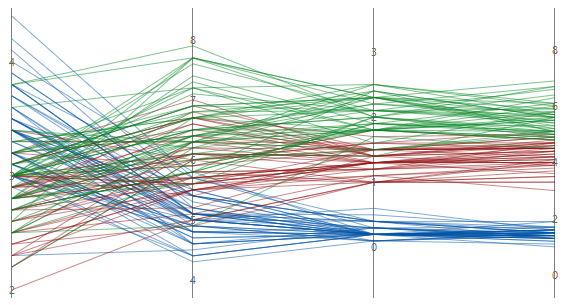
已排序
热图
用于 热图 比较均值或其他汇总统计量,使用颜色渐变来表示不同组的影响。
类别行变量
最多输入五列,其中类别在热图上表示为行。
类别列变量
最多输入五列,其中类别在热图上表示为列。
汇总变量 可选
输入定义热图中矩形颜色渐变的数字或文本列。如果您输入多个列,Minitab 会为您输入的每个变量生成一个单独的热图。
函数
从 函数 中选择 汇总变量 的函数。例如,如果选择 最大值,Minitab 将根据每个矩形中汇总变量的最大值定义热图的颜色渐变。如果在 中 汇总变量输入文本列,则只能选择 等于指定值的百分比、 非缺失值数或 缺失值数。
- 百分位数
- 如果选择 百分位数,则必须在 百分位数值 中输入值。值必须在 0 和 100 之间。Minitab 使用您输入的值来定义热图中的颜色梯度。例如,如果输入 50,Minitab 将使用第 50 个百分位数来定义热图的每个矩形的颜色梯度。
- 两个值之间的百分比
- 如果选择 两个值之间的百分比,则必须在 和 第二个值中 第一个值 输入数值。您为 第一个值 输入的值必须小于或等于您为 第二个值 输入的值。Minitab 根据两个值之间的观测值百分比定义热图的颜色梯度。
- 等于指定值的百分比
- 如果选择 等于指定值的百分比,则必须在 值 中输入一个或多个值。这些值必须与在 汇总变量 中输入的列具有相同的数据类型。Minitab 根据与您输入的值相等的观测值的百分比定义热图的颜色梯度。
梯度类型
- 发散
- 具有较高值的区间为红色,具有较低值的区间为蓝色。在 梯度沿值对称中,输入一个值以将梯度刻度居中于特定值,而不是分箱数据的频率中心。
-
- 从低到高的顺序
- 具有较高值的区间为深蓝色,具有较低值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较高生产率的区间或者最大化收入。
- 从高到低的顺序
- 具有较低值的区间为深蓝色,具有较高值的区间为浅蓝色和浅灰色。您可以使用此选项突出显示具有较低缺陷率的区间或者最小化收入。
Wafer 图
使用 a Wafer 图 比较使用颜色渐变来表示响应变量变化的均值或其他汇总统计量。有关数据考虑、示例和解读的信息,请访问 “晶圆图概览”。
Y 坐标
输入一个数字列,其中包含表示晶圆图上 y 轴的数据。
X 坐标
输入一个数字列,其中包含表示晶圆图上 x 轴的数据。
响应变量
输入一个数字列,用于定义晶圆图中矩形的颜色渐变。从 函数 中选择 响应变量 的函数。例如,如果选择 最大值,Minitab 将根据每个矩形中响应变量的最大值定义晶片图的颜色梯度。
- 百分位数
- 如果选择 百分位数,则必须在 百分位数值 中输入值。值必须在 0 和 100 之间。Minitab 使用您输入的值来定义晶圆图中的颜色梯度。例如,如果您输入 50,Minitab 将使用第 50 个百分位数来定义晶圆图的每个矩形的颜色梯度。
- 两个值之间的百分比
- 如果选择 两个值之间的百分比,则必须在 和 第二个值中 第一个值 输入数值。您为 第一个值 输入的值必须小于或等于您为 第二个值 输入的值。Minitab 根据两个值之间的观测值百分比定义晶片图的颜色梯度。
- 等于指定值的百分比
- 如果选择 等于指定值的百分比,则必须在 值 中输入一个或多个值。这些值必须与在 响应变量 中输入的列具有相同的数据类型。Minitab 根据等于您输入的值的观测值的百分比定义晶片图的颜色梯度。
分组变量
在 中 分组变量 输入分组变量,为分组变量的每个水平创建单独的晶圆图。您输入的列必须与 和 Y 坐标中的 X 坐标 列长度相同。
梯度类型
- 发散
- 具有高值的矩形为红色,具有低值的矩形为蓝色。在 梯度沿值对称中,输入一个值,使渐变比例以特定值为中心,而不是所选函数的中心。例如,企业主选择要由多个商店中多种产品的利润均值定义的梯度。所有者输入 0 作为 , 梯度沿值对称 以便具有盈利产品的矩形与亏损产品的矩形具有不同的颜色。
-
- 从低到高的顺序
- 具有高值的矩形为深蓝色,具有低值的矩形为浅蓝色和浅灰色。您可以使用此选项突出显示具有较高生产率的矩形或者最大化收入。
- 从高到低的顺序
- 具有低值的矩形为深蓝色,具有高值的矩形为浅蓝色和浅灰色。您可以使用此选项突出显示具有较低缺陷率的矩形或者最小化收入。
- 不同的颜色渐变
- 您可以从 5 种备用颜色渐变中进行选择。

梯度极差
注意
如果为函数指定了 两个值之间的百分比 OR 等于指定值的百分比 ,则晶圆图将对梯度使用百分比刻度。在这些情况下,您输入 for 最小值 和 最大值 的值应介于 0 和 1 之间。
列表统计量
当您 列表统计量 有按一个或多个分类变量分类的数据时使用。您可以确定两个或多个类别变量的类别组合的各种统计量。
变量
- 在 类别行变量中,最多输入 3 列,这些列包含定义表行的类别。
- 在 类别列变量中,最多输入 2 列,这些列包含定义表列的类别。
-
在 (可选) 中 汇总变量 ,输入包含要汇总的关联变量的列。关联变量是按类别变量分组的连续变量。
默认情况下,平均值是表显示的唯一统计数据。要显示其他统计信息, 汇总统计量 请从变量名称旁边的下拉列表中选择。某些统计数据要求您输入其他值。- 百分位数
- 在 百分位数值中,输入一个介于 0 和 100 之间的值。例如,如果输入 50,Minitab 将显示第 50 个百分位数。
- 两个值之间的百分比
- 必须在 和 第二个值中 第一个值 输入数值。必须 第一个值 小于或等于 第二个值。Minitab 显示等于两个值或介于这两个值之间的观测值的百分比。这包括等于两个值的观测值。
- 等于指定值的百分比
- 在 值中,输入一个或多个值,这些值与您在 中输入 汇总变量的列的数据类型相同。Minitab 显示等于您输入的值的观测值的百分比。
有关表布局的更多信息,请转到 输出表的排列。
| C1 | C2 | C3 |
|---|---|---|
| 强度 | 机器 | 操作员 |
| 38 | 1 | 1 |
| 40 | 2 | 2 |
| 63 | 3 | 3 |
| 59 | 4 | 1 |
| 76 | 1 | 2 |
| ... | ... | ... |
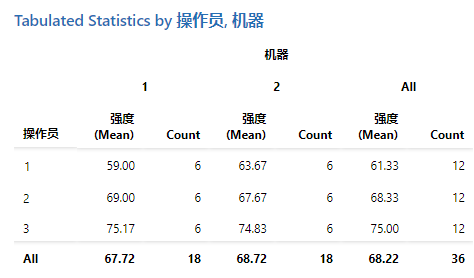
类别变量汇总统计量
- 计数
- 显示行变量和列变量的每个组合的观测计数。
- 行百分比
- 显示每个单元格表示的总观测值数在表格行中的百分比。
- 列百分比
- 显示由每个单元格表示的表格列中总观测值数的百分比。
- 总百分比
- 显示由每个单元格表示的表格中所有观测值的百分比。
显示选项
- 显示边际统计量
- 选择以显示边际统计量。边际统计量提供有关表的行和列的信息,例如总计。
- 显示缺失值
- 选择以显示缺失值。Minitab 将排除具有任何缺失变量的所有行,除非您包括缺失数据。选择 在计算中包括显示的缺失值 以在计算中包括缺失值。有关更多信息,请转到 如何解释表中的缺失值。
时间序列图
使用 时间序列图 可以查找数据中一段时间的模式,如趋势或季节性模式。
连续变量
输入要绘制图表的一列或多列按时间顺序排列的数字数据。
时间尺度标签 可选
使用包含刻度的日期/时间、数字或文本值的列中的值标记 x 轴。例如,在以下时间序列图中,列指定班次和日期。
| C1-T |
|---|
| 轮班和日 |
| S1D1 |
| S2D1 |
| S3D1 |
| ... |
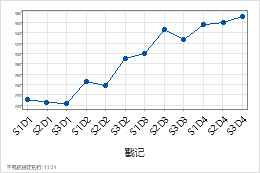
布局
设置以下布局选项。
- 组块连续变量
- 输入字段中的 连续变量 列显示在单个时间序列图上,其中所有变量共享一个 X 轴,并且每个连续变量都显示在其自己的面板中。
- 重叠连续变量
- 输入字段中的 连续变量 列叠加在单个时间序列图上。
Y 尺度
选择 y 刻度的显示方式。
- 原始数据
- 选择此选项可使用单个针对每个变量重复的 y 尺度。尺度的最小值和最大值是您输入的所有数据的整体最小值和最大值。
- 范围百分比
- 选择此选项可绘制每个具有唯一 y 尺度的变量。包含每个变量的所有最小值或最大值的系列将是一条水平线。
- 对数尺度
- 对数尺度通过更改轴来将对数关系线性化,以便同一个距离表示尺度上不同的值变化。此选项仅适用于正数据。
堆叠区域图
用于 堆叠区域图 按时间顺序绘制组的累积总和,并评估每个组对整体的贡献。在区域图上,每个阴影区域都表示该变量及其下方变量的累积合计。例如,以下区域图显示了一家大型零售连锁店在两年内三家商店的月销售额。1月份所有三个集团的销量约为1000辆。
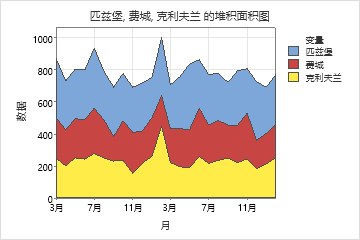
连续变量
输入要绘制图表的一列或多列按时间顺序排列的数字数据。
时间尺度标签 可选
使用包含刻度的日期/时间、数字或文本值的列中的值标记 x 轴。例如,在以下时间序列图中,列指定班次和日期。
| C1-T |
|---|
| 轮班和日 |
| S1D1 |
| S2D1 |
| S3D1 |
| ... |
堆叠顺序
您可以在创建图形时更改变量的堆叠顺序。
- 输入顺序 (第一个位于顶部)
- 按照您在对话框中输入变量的顺序堆叠变量。您输入的第一个变量位于顶部,第二个变量位于第一个变量下方,依此类推。
- 变异程度 (最大位于顶部)
- 按变异程度堆叠变量。变异最大的变量位于顶部,变异第二大的变量位于第一个变量下方,依此类推。
对数变换: Y 尺度
选择以使用对数基数 10 变换 Y 刻度。对数尺度通过更改轴来将对数关系线性化,以便同一个距离表示尺度上不同的值变化。这些选项仅适用于正数据。
KPI
- 选择包含你数据的。 数据连接
- 在 变量中,指定测 KPI 度。
- 选择一个 函数,如均值、和或最大值。
- 你可以选择性地更改 标题。
你还可以自定义其他选项,改变仪 KPI 表盘上的显示方式。关闭 自动 按钮,指定你自己的变量格式。
值格式设置
- 自定义小数位
- 指定变量的小数点数。小数点数最多为12位。
- 规模与布局
- 指定变量的大小和比对方式。
- 冠军位置
- 指定标题显示在变量的上方或下方。
- 文本颜色
- 指定变量的颜色和透明度。不透明度可以是0到100之间的任意数。数字越小,变量越透明。
条件格式
- 选择 条件格式 选项卡。
- 选择 添加。
- 在 中指定条件 运算符。例如,当KPI值达到 大于 某个值时,你想应用格式化。
- 输入一个数字。 值
- 在 条件文本 (可选)中,输入文本,显示在变量 标题 满足条件时显示。
- 在 条件文本颜色中,指定变量满足条件时的颜色和不透明度。不透明度可以是0到100之间的任意数。数字越小,变量越透明。
你可以添加多个条件。如果KPI变量满足多个条件,仪表盘会应用列表中最低的条件。你可以选择省略号![]() 用来将某个条件在列表中的上移或下移。
用来将某个条件在列表中的上移或下移。
表格
- 更改或隐藏标题
- 选择要显示的特定列
- 添加行计数器作为初始列
- 换行文本列
您可以拖动标题单元格的边缘来调整列宽。

表示降序
