Neste tópico
Etapa 1: Descrever o tamanho de sua amostra
Use N para saber quantas observações estão em sua amostra. O Minitab não inclui valores faltantes nesta contagem.
Você deve coletar uma amostra de dados de média a grande. Amostras que tem pelo menos 20 observações, com frequência são adequadas para representar a distribuição dos dados. No entanto, para representar melhor a distribuição com um histograma, alguns profissionais recomendam que você tenha pelo menos 50 observações. Amostras grandes também fornecem estimativas mais precisas dos parâmetros do processo como a média e o desvio padrão.
Estatísticas
| Variável | N | N* | Média | EP Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|---|---|---|---|
| Torque | 68 | 0 | 21,2647 | 0,778784 | 6,42202 | 10 | 16 | 20 | 24,75 | 37 |
Resultados principais: N
Nestes resultados, você tem 68 observações.
Etapa 2: Descreva o centro de seus dados
Use a média para descrever a amostra com um único valor que representa o centro dos dados. Diversas análises estatísticas usam a média como uma média padrão do centro da distribuição dos dados.
A mediana é outra medida do centro da distribuição dos dados. A mediana é normalmente menos influenciada por outliers do que a média. Metade dos valores dos dados são maiores do que o valor da mediana e metade dos valores dos dados são menores do que o valor da mediana.
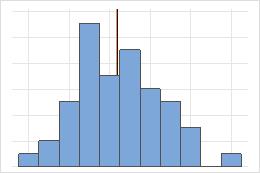
Simétrica
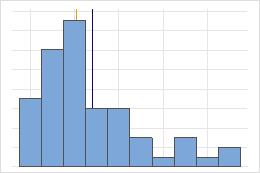
Não simétrica
Para a distribuição simétrica, a média (linha azul) e a mediana (linha laranja) são tão similares que você não pode ver facilmente as linhas. Mas a distribuição não simétrica é assimétrica à direita.
Estatísticas
| Variável | N | N* | Média | EP Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|---|---|---|---|
| Torque | 68 | 0 | 21,2647 | 0,778784 | 6,42202 | 10 | 16 | 20 | 24,75 | 37 |
Principais resultados: média e mediana
Nesses resultados, o torque médio necessário para remover a tampa do creme dental é 21,265, e o torque mediano é 20. Os dados parecem estar assimétricos à direita, o que explica a razão pela qual a média é maior do que a mediana.
Etapa 3: Descrever a dispersão de seus dados
Use o desvio padrão para determinar o grau de dispersão dos dados a partir da média. Um valor de desvio padrão mais alto indica maior dispersão nos dados.
Estatísticas
| Variável | N | N* | Média | EP Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|---|---|---|---|
| Torque | 68 | 0 | 21,2647 | 0,778784 | 6,42202 | 10 | 16 | 20 | 24,75 | 37 |
Resultados principais: StDev
Nestes resultados, o desvio padrão é de 6,422. Com os dados normais, a maior parte das observações está distribuída dentro de 3 desvios padrão em cada lado da média.
Passo 4: Avalie a forma e a dispersão de sua distribuição de dados
Utilize o histograma, o gráfico de valores individuais e o boxplot para avaliar a forma e a dispersão dos dados e identificar os outliers potenciais.
Examinar a dispersão de seus dados para determinar se eles parecem ser assimétricos
Quando os dados são assimétricos, a maioria dos dados está localizada no lado alto ou baixo do gráfico. Muitas vezes, é mais fácil detectar a assimetria com um histograma ou boxplot.
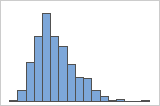
Assimétrico à direita
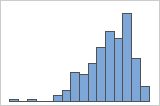
Assimétrico à esquerda
O histograma com dados assimétricos à direita mostra os tempos de espera. A maioria dos tempos de espera são relativamente curtos e apenas alguns tempos de espera são longos. O histograma com dados assimétricos à esquerda mostram dados de tempo de falha. Alguns itens falham imediatamente e muitos outros itens falham posteriormente.
Determinar o quanto seus dados variam
Avalie a dispersão dos pontos para determinar o quanto sua amostra varia. Quanto maior a variação na amostra, mais os pontos irão se dispersar para fora do centro de dados.

Este gráfico de valores individuais que mostra os dados da direita têm mais variações do que os dados à esquerda.
Procurar por dados multimodais
Os dados multimodais têm vários picos, também chamados de modos. Os dados multimodais, muitas vezes, indicam que variáveis importantes ainda não foram contabilizadas.
Se você tiver informações adicionais que lhe permitam classificar as observações em grupos, pode criar uma variável de grupo com estas informações. Em seguida, pode criar o gráfico com grupos para determinar se a variável de grupo representa os picos nos dados.
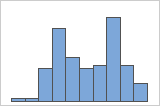
Simples
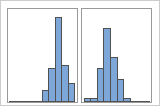
Com grupos
Por exemplo, um gerente de um banco coleta os dados de tempo de espera e cria um histograma simples. O histograma parece ter dois picos. Após uma investigação mais aprofundada, o gerente determina que os tempos de espera para os clientes que estão descontando cheques é menor do que os tempos de espera para os clientes que estão se candidatando a empréstimos imobiliários. O gerente acrescenta uma variável de grupo para a tarefa do cliente e, em seguida, cria um histograma com grupos.
Identificar outliers
Outliers, que são valores de dados que estão distantes de outros valores de dados, podem afetar fortemente os resultados de sua análise. Muitas vezes, os outliers são mais fáceis de serem identificados em um boxplot.
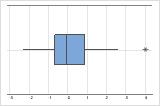
Em um boxplot, asteriscos (*) denotam outliers.
Tente identificar a causa de todos os outliers. Corrija todos os erros de entrada de dados ou de medição. Considere a remoção de valores de dados para eventos anormais de ocorrência única (também chamados de causas especiais). Depois, repita a análise. Para obter mais informações, acesse Identificação de outliers.
Etapa 5. Comparar os dados de diferentes grupos
Se você tiver uma Por variável que identifique os grupos em seus dados, pode usá-la para analisar os dados por grupo ou por nível de grupo.
Estatísticas
| Variável | Máquina | N | N* | Média | EP Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Torque | 1 | 36 | 0 | 18,6667 | 0,732467 | 4,39480 | 10 | 15,25 | 17 | 21,75 | 30 |
| 2 | 32 | 0 | 24,1875 | 1,25839 | 7,11852 | 14 | 17,5 | 24 | 31 | 37 |
Nestes resultados, as estatísticas de resumo são calculados separadamente por máquina. É possível ver facilmente as diferenças no centro e a dispersão dos dados para cada máquina. Por exemplo, a Máquina 1 tem um torque médio reduzido e menor variação do que a Máquina 2. Para determinar se a diferença entre as médias é significativa, é possível executar um teste t de 2 amostras.