Neste tópico
Boxplot
Um boxplot fornece um resumo gráfico da distribuição de uma amostra. O boxplot mostra a forma, a tendência central e a variabilidade dos dados.
Interpretação
Utilize um boxplot para examinar a dispersão dos dados e identificar todos os outliers potenciais. Os boxplots são melhores quando o tamanho amostral for superior a 20.
- Dados Assimétricos
-
Examine a dispersão de seus dados para determinar se eles parecem ser assimétricos. Quando os dados são assimétricos, a maioria dos dados está localizada no lado alto ou baixo do gráfico. Muitas vezes, é mais fácil detectar a assimetria com um histograma ou boxplot.
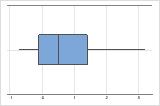
Assimétrico à direita
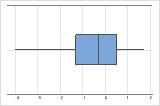
Assimétrico à esquerda
O boxplot com dados assimétricos à direita mostra os tempos de espera. A maioria dos tempos de espera são relativamente curtos e apenas alguns tempos de espera são longos. O boxplot com dados assimétricos à esquerda mostram dados de tempo de falha. Alguns itens falham imediatamente e muitos outros itens falham posteriormente.
- Outliers
-
Outliers, que são valores de dados que estão distantes de outros valores de dados, podem afetar fortemente os resultados de sua análise. Muitas vezes, os outliers são mais fáceis de serem identificados em um boxplot.
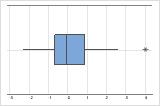
Em um boxplot, asteriscos (*) denotam outliers.
Tente identificar a causa de todos os outliers. Corrija todos os erros de entrada de dados ou de medição. Considere a remoção de valores de dados para eventos anormais de ocorrência única (também chamados de causas especiais). Depois, repita a análise. Para obter mais informações, acesse Identificação de outliers.
Histograma
Um histograma divide valores de amostra para muitos intervalos e representa a frequência de valores de dados em cada intervalo com uma barra.
Interpretação
Utilize um histograma para avaliar a forma e a dispersão dos dados. Os histogramas são melhores quando o tamanho amostral for superior a 20.
- Dados Assimétricos
-
Você pode usar um histograma dos dados sobrepostos por uma curva normal para analisar a normalidade de seus dados. Uma distribuição normal é simétrica e em forma de sino, como indicada pela curva. Muitas vezes, é difícil de avaliar a normalidade com amostras pequenas. É melhor usar um gráfico de probabilidade para determinar o ajuste de distribuição.
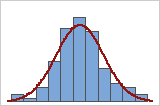
Bom ajuste
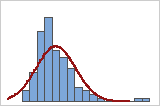
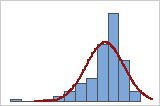
Ajuste ruim
- Outliers
-
Outliers, que são valores de dados que estão distantes de outros valores de dados, podem afetar fortemente os resultados de sua análise. Muitas vezes, os outliers são mais fáceis de serem identificados em um boxplot.
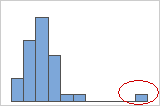
Em um histograma, barras isoladas em ambas as extremidades do gráfico identificam possíveis outliers.
Tente identificar a causa de todos os outliers. Corrija todos os erros de entrada de dados ou de medição. Considere a remoção de valores de dados para eventos anormais de ocorrência única (também chamados de causas especiais). Depois, repita a análise. Para obter mais informações, acesse Identificação de outliers.
- Dados multimodais
-
Os dados multimodais têm vários picos, também chamados de modos. Os dados multimodais, muitas vezes, indicam que variáveis importantes ainda não foram contabilizadas.
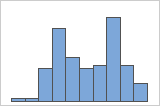
Simples
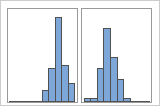
Com grupos
Por exemplo, um gerente de um banco coleta os dados de tempo de espera e cria um histograma simples. O histograma parece ter dois picos. Após uma investigação mais aprofundada, o gerente determina que os tempos de espera para os clientes que estão descontando cheques é menor do que os tempos de espera para os clientes que estão se candidatando a empréstimos imobiliários. O gerente acrescenta uma variável de grupo para a tarefa do cliente e, em seguida, cria um histograma com grupos.
Se você tiver informações adicionais que lhe permitam classificar as observações em grupos, pode criar uma variável de grupo com estas informações. Em seguida, pode criar o gráfico com grupos para determinar se a variável de grupo representa os picos nos dados.
Gráfico de valores individuais
Um gráfico de valores individuais exibe os valores individuais na amostra. Cada círculo representa uma observação. Um gráfico de valores individuais é especialmente útil quando você tem relativamente poucas observações e também precisa avaliar o efeito de cada observação.
Interpretação
Utilize um gráfico de valores individuais para examinar a dispersão dos dados e identificar os outliers potenciais. Os gráficos de valores individuais são melhores quando o tamanho amostral for inferior a 50.
- Dados Assimétricos
-
Examine a dispersão de seus dados para determinar se eles parecem ser assimétricos. Quando os dados são assimétricos, a maioria dos dados está localizada no lado alto ou baixo do gráfico. Muitas vezes, é mais fácil detectar a assimetria com um histograma ou boxplot.
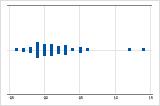
Assimétrico à direita
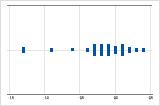
Assimétrico à esquerda
O gráfico de valores individuais com dados assimétricos à direita mostra os tempos de espera. A maioria dos tempos de espera são relativamente curtos e apenas alguns tempos de espera são longos. O gráfico de valores individuais com dados assimétricos à esquerda mostram dados de tempo de falha. Alguns itens falham imediatamente e muitos outros itens falham posteriormente.
- Outliers
-
Outliers, que são valores de dados que estão distantes de outros valores de dados, podem afetar fortemente os resultados de sua análise. Muitas vezes, os outliers são mais fáceis de serem identificados em um boxplot.
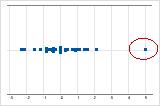
Em um gráfico de valores individuais, os valores de dados anormalmente baixos ou altos indicam possíveis outliers.
Tente identificar a causa de todos os outliers. Corrija todos os erros de entrada de dados ou de medição. Considere a remoção de valores de dados para eventos anormais de ocorrência única (também chamados de causas especiais). Depois, repita a análise. Para obter mais informações, acesse Identificação de outliers.
Q1
Quartis são os três valores — o primeiro quartil a 25% (Q1), o segundo quartil a 50% (Q2 ou mediana) e o terceiro quartil a 75% (Q3)— que dividem uma amostra de dados ordenados em quatro partes iguais.
O primeiro quartil o 25o percentil e indica que 25% dos dados são menores ou iguais a este valor.
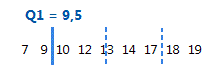
Para estes dados ordenados, o primeiro quartil (Q1) é 9,5. Ou seja, 25% dos dados são menores ou iguais a 9,5.
IIQ
O intervalo interquartil (IIR) é a distância entre o primeiro quartil (Q1) e o terceiro quartil (Q3). 50% dos dados estão dentro deste intervalo.
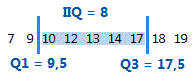
Para estes dados ordenados, o intervalo interquartil é 8 (17,5–9,5 = 8). Ou seja, a metade de 50% dos dados está entre 9,5 e 17,5.
Interpretação
Utilize o intervalo interquartil para descrever a dispersão dos dados. Como a dispersão dos dados aumenta, o IIQ torna-se maior.
Máximo
O valor máximo é o maior valor de dados.
Nesses dados, o máximo é 19.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
Interpretação
Use o máximo para identificar um possível outlier ou um erro de entrada de dados. Uma das maneiras mais simples para avaliar a dispersão de seus dados é comparar o mínimo e o máximo. Se o valor máximo for muito elevado, mesmo quando se considerar o centro, a dispersão e o formato dos dados, investigue a causa do valor extremo.
Mediana
A mediana é o ponto médio do conjunto de dados. Este valor do ponto médio é o ponto em que metade das observações estão acima do valor e metade das observações estão abaixo do valor. A mediana é determinada por classificar as observações e encontrar a observação que está no número [N + 1] / 2 na ordem de grandeza. Se o número de observações for ímpar, a mediana é o valor médio das observações que são classificadas com números de N / 2 e [N / 2] + 1.
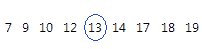
Para esses dados ordenados, a mediana é 13. Isto é, metade dos valores é menor ou igual a 13, e metade dos valores é maior ou igual a 13. Se você adicionar outra observação igual a 20, a mediana será 13,5, que é a média entre a 5a observação (13) e a 6a observação (14).
Interpretação
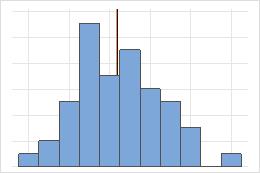
Simétrica
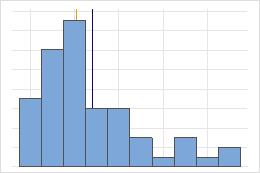
Não simétrica
Para a distribuição simétrica, a média (linha azul) e a mediana (linha laranja) são tão similares que você não pode ver facilmente as linhas. Mas a distribuição não simétrica é assimétrica à direita.
Mínimo
O mínimo é o menor valor de dados.
Em nesses dados, o mínimo é 7.
| 13 | 17 | 18 | 19 | 12 | 10 | 7 | 9 | 14 |
Interpretação
Use o mínimo para identificar um possível outlier ou um erro de entrada de dados. Uma das maneiras mais simples para avaliar a dispersão de seus dados é comparar o mínimo e o máximo. Se o valor mínimo for muito baixo, mesmo quando se considerar o centro, a dispersão e o formato dos dados, investigue a causa do valor extremo.
Intervalo
O intervalo é a diferença entre o maior e o menor valores de dados na amostra. O intervalo representa o menor intervalo que contém todos os valores de dados.
Interpretação
Utilize um intervalo para entender a quantidade de dispersão nos dados. Um valor grande valor no intervalo indica uma maior dispersão nos dados. Um valor pequeno no intervalo indica que há menor dispersão nos dados. Como o intervalo é calculado utilizando apenas dois valores de dados, ele é ainda mais útil nos conjuntos de dados pequenos.
Q3
Quartis são os três valores — o primeiro quartil a 25% (Q1), o segundo quartil a 50% (Q2 ou mediana) e o terceiro quartil a 75% (Q3)— que dividem uma amostra de dados ordenados em quatro partes iguais.
O terceiro quartil é o 75o percentil e indica que 75% dos dados são menores ou iguais a este valor.
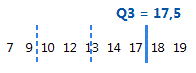
Para estes dados ordenados, o terceiro quartil (Q3) é 17,5. Ou seja, 75% dos dados são menores ou iguais a 17,5.
Média
A média é a média dos dados, que é a soma de todas as observações divididas pelo número de observações.
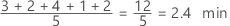
Interpretação
Use a média para descrever a amostra com um único valor que representa o centro dos dados. Diversas análises estatísticas usam a média como uma média padrão do centro da distribuição dos dados.
Simétrica
Não simétrica
Para a distribuição simétrica, a média (linha azul) e a mediana (linha laranja) são tão similares que você não pode ver facilmente as linhas. Mas a distribuição não simétrica é assimétrica à direita.
EP Média
O erro padrão da média (SE Média) estima a variabilidade entre a amostra média que você obteria se você tivesse extraído repetidas amostras da mesma população. Considerando-se que o erro padrão da média estima a variabilidade entre as amostras, o desvio padrão mede a variabilidade dentro de uma única amostra.
Por exemplo, você tem um tempo médio de entrega de 3,80 dias, com um desvio padrão de 1,43 dias, a partir de uma amostra aleatória de 312 prazos de entrega. Estes números produzem um erro padrão da média de 0,08 dias (1,43 dividido pela raiz quadrada de 312). Se você extraiu várias amostras aleatórias do mesmo tamanho da mesma população, o desvio padrão dessas médias diferentes de amostra seria de cerca de 0,08 dias.
Interpretação
Use o erro padrão da média para determinar o quão precisamente a média da amostra estima a média da população.
Um valor menor do erro padrão da média indica uma estimativa mais precisa da média da população. Normalmente, um desvio padrão maior resulta em um erro padrão maior da média e uma estimativa menos precisa da média da população. A amostra de tamanho maior resulta em um erro padrão menor da média e uma estimativa mais precisa da média da população.
O Minitab utiliza o erro padrão da média para calcular o intervalo de confiança.
TrMean
A média dos dados sem os 5% maiores e os 5% menores valores.
Use médias aparadas para eliminar o impacto de valores muito maiores ou muito menores da média. Quando os dados contêm outliers, a média aparada pode ser uma medida melhor da tendência central do que a média.
CumN
| Série | Contagem | CumN | Cálculo |
|---|---|---|---|
| 1 | 49 | 49 | 49 |
| 2 | 58 | 107 | 49 + 58 |
| 3 | 52 | 159 | 49 + 58 + 52 |
| 4 | 60 | 219 | 49 + 58 + 52 + 60 |
| 5 | 48 | 267 | 49 + 58 + 52 + 60 + 48 |
| 6 | 55 | 322 | 49 + 58 + 52 + 60 + 48 + 55 |
N*
Número de valores faltantes na amostra. O número de valores faltantes se refere às células que contêm o símbolo de valor faltante *.
| Contagem total | N | N* |
|---|---|---|
| 149 | 141 | 8 |
N
O número de valores não faltantes na amostra.
| Contagem total | N | N* |
|---|---|---|
| 149 | 141 | 8 |
Contagem Total
O número total de observações na coluna. Use para representar a soma de N faltantes e N não faltantes.
| Contagem total | N | N* |
|---|---|---|
| 149 | 141 | 8 |
CumPct
A porcentagem acumulada é a soma acumulada das percentagens para cada grupo de Por variável. No exemplo a seguir, a Por variável tem 4 grupos: Linha 1, Linha 2, Linha 3 e Linha 4.
| Grupo (por variável) | Percentual | CumPct |
|---|---|---|
| Linha 1 | 16 | 16 |
| Linha 2 | 20 | 36 |
| Linha 3 | 36 | 72 |
| Linha 4 | 28 | 100 |
Percentual
O percentual de observações em cada grupo de Por variável. No exemplo a seguir, existem quatro grupos: Linha 1, Linha 2, Linha 3 e Linha 4.
| Grupo (por variável) | Percentual |
|---|---|
| Linha 1 | 16 |
| Linha 2 | 20 |
| Linha 3 | 36 |
| Linha 4 | 28 |
Curtose
A curtose indica como as caudas de uma distribuição diferem da distribuição normal.
Interpretação
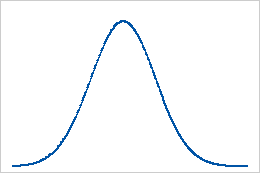
Linha de base: valor da curtose de 0
Normalmente os dados distribuídos estabelecem a linha de base para a curtose. Um valor de curtose de 0 indica que os dados seguem a distribuição normal perfeitamente. O valor da curtose que se desvia significativamente de 0 pode indicar que os dados não estão normalmente distribuídos.
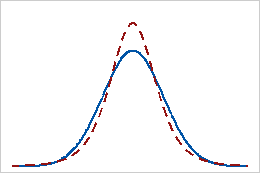
Curtose positiva
Uma distribuição com um valor de curtose positiva indica que a distribuição tem caudas mais pesadas do que a distribuição normal. Por exemplo, os dados que se seguem à distribuição T têm um valor de curtose positivo. A linha contínua mostra a distribuição normal e a linha pontilhada mostra uma distribuição com um valor de curtose positivo.
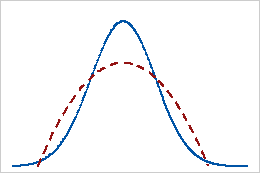
Curtose negativa
Uma distribuição com um valor de curtose negativa indica que a distribuição tem caudas mais leves do que a distribuição normal. Por exemplo, os dados que seguem uma distribuição beta com primeiro e segundo parâmetros de forma igual a 2 têm um valor de curtose negativo. A linha contínua mostra a distribuição normal e a linha pontilhada mostra uma distribuição com um valor de curtose negativo.
Assimetria
A assimetria é a medida em que os dados não são simétricos.
Interpretação
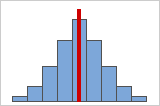
Figura A
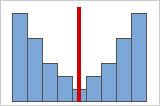
Figura B
Distribuições simétricas ou não assimétricas
Conforme os dados tornam-se simétricos, seu valor de assimetria aproxima-se de zero. A Figura A mostra dados de distribuição normal, que por definição exibe assimetria relativamente pequena. Ao traçar uma linha abaixo do meio deste histograma de dados normais é fácil de ver que os dois lados refletem um ao outro. Mas a falta de assimetria simplesmente não significa normalidade. A Figura B mostra uma distribuição onde os dois lados ainda refletem um ao outro, apesar de os dados estarem longe de serem uma distribuição normal.
Distribuições com assimetria positiva ou à direita
Dados com assimetria positiva ou à direita são assim chamados por causa da "cauda" dos pontos de distribuição à direita, e porque seu valor de assimetria será maior do que 0 (ou positiva). Dados salariais são, frequentemente, assimétricos desta maneira: vários funcionários em uma empresa ganham relativamente pouco, enquanto cada vez menos pessoas ganham altos salários.
Distribuições com assimetria negativa ou à esquerda
Assimetria à esquerda ou dados assimétricos negativos são assim chamados porque a "cauda" da distribuição aponta para a esquerda, e porque ela produz um valor de assimetria negativo. Os dados da taxa de falha são frequentemente assimétricos à esquerda. Considere as lâmpadas: muito poucas vão queimar imediatamente, a grande maioria durará por um longo tempo.
CoefVar
O coeficiente de variação (CoefVar) é uma medida da dispersão que descreve a variação nos dados em relação à média. O coeficiente de variação é ajustado de modo que os valores estão em uma escala sem unidade. Devido a esse ajuste, é possível usar o coeficiente de variação, em vez de o desvio padrão para comparar a variação nos dados que tem unidades diferentes ou que tem médias muito diferentes.
Interpretação
Quanto maior for o coeficiente de variação, maior será a dispersão nos dados.
| Pacote grande | Pacote pequeno |
|---|---|
| CoefVar = 100 * 0,4 xícaras / 16 xícaras = 2.5 | CoefVar = 100 * 0,08 xícaras / 1 xícara = 8 |
StDev
O desvio padrão é a medida mais comum de dispersão, ou o quanto os dados estão dispersos sobre a média. O símbolo σ (sigma) é frequentemente usado para representar o desvio padrão de uma população, enquanto s é usado para representar o desvio padrão de uma amostra. A variação que é aleatória ou natural de um processo é frequentemente referida como ruído.
Como o desvio padrão está nas mesmas unidades que os dados, ele é normalmente mais fácil de interpretar do que a variância.
Interpretação
Use o desvio padrão para determinar o grau de dispersão dos dados a partir da média. Um valor de desvio padrão mais alto indica maior dispersão nos dados. Uma boa regra de ouro de uma distribuição normal é que aproximadamente 68% dos valores estão dentro de um desvio padrão da média, 95% dos valores estão dentro de dois desvios padrão e 99,7% dos valores estão dentro de três desvios padrão.
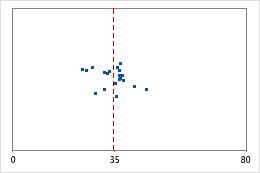
Hospital 1
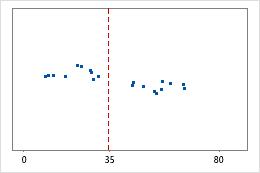
Hospital 2
Tempos de alta de hospital
Os administradores controlam o tempo gasto na alta de pacientes tratados nos departamentos de emergência de dois hospitais. Apesar de os tempos médios de alta serem quase os mesmos (35 minutos), os desvios padrão são significativamente diferentes. O desvio padrão do hospital 1 é de cerca de 6. Em média, o tempo de alta de um paciente se desvia da média (linha tracejada) em cerca de 6 minutos. O desvio padrão do hospital 2 é de cerca de 20. Na média, um tempo de alta de um paciente se desvia da média (linha tracejada) em cerca de 20 minutos.
Variância
A variância mede o quanto os dados estão dispersos em relação à sua média. A variância é igual ao desvio padrão ao quadrado.
Interpretação
Quanto maior a variância, maior a dispersão nos dados.
Como a variância (σ2) é uma quantidade quadrada, suas unidades também são quadradas, o que torna a variância difícil de usar, na prática. O desvio padrão é normalmente mais fácil de interpretar porque ele está nas mesmas unidades que os dados. Por exemplo, uma amostra de tempos de espera em uma parada de ônibus pode ter uma média de 9 minutos2. Como a variância não está nas mesmas unidades que os dados, com frequência, ela é exibida com sua raiz quadrada, o desvio padrão. Uma variância de 9 minutos2 é equivalente a um desvio padrão de 3 minutos.
Modo
O modo é o valor que ocorre mais frequentemente em um conjunto de observações. O Minitab também exibe quantos pontos de dados são iguais ao modo.
A média e mediana exigem um cálculo, mas o modo é determinado pela contagem do número de vezes que cada valor ocorre num conjunto de dados.
Interpretação
O modo pode ser utilizado com a média e mediana para proporcionar uma caracterização geral da sua distribuição de dados. O modo também pode ser usado para identificar problemas em seus dados.
Por exemplo, uma distribuição que tem mais do que um modo pode identificar que a sua amostra inclui dados a partir de duas populações. Se os dados contiverem dois modos, a distribuição é bimodal. Se os dados contiverem mais de dois modos, a distribuição é multimodal.
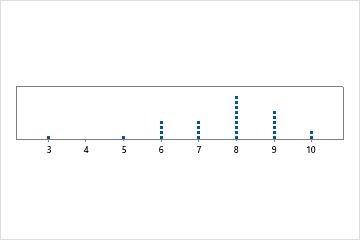
Monomodal
Há apenas um modo, 8, que ocorre com maior frequência.
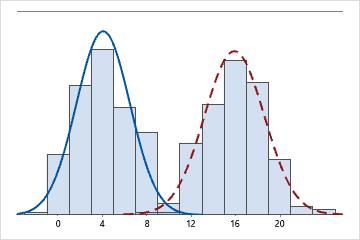
Bimodal
Existem dois modos, 4 e 16. Os dados parecem representar duas populações diferentes.
MSSD
O MSSD é a média da diferença sucessiva ao quadrado. O MSSD é uma estimativa da variância. Um possível uso do MSSD é testar se uma sequência de observações é aleatória. No controle de qualidade, uma possibilidade de utilização de MSSD é estimar a variância quando o tamanho do subgrupo = 1.
Soma
A soma é o total de todos os valores de dados. A soma também é usada em cálculos estatísticos, como a média e o desvio padrão.
Soma dos Quadrados
A soma dos quadrados sem correção são calculados elevando-se ao quadrado cada valor na coluna, e calculando-se a soma desses valores ao quadrado. Por exemplo, se a coluna contiver x1, x2, ... , xn, a soma dos quadrados é calculada como (x12 + x22 + ... + xn2). Ao contrário da soma dos quadrados corrigida, a soma dos quadrados não corrigida inclui erro. Os valores dos dados são elevados ao quadrado sem subtrair primeiro a média.