Neste tópico
Etapa 1: Determine um intervalo de confiança para a diferença nas médias de população
Primeiro, considere a diferença nas médias das amostras e depois examine o intervalo de confiança.
A diferença é uma estimativa da diferença nas médias da população. Como a diferença média está baseada em dados das amostras e não na população total, é improvável que a diferença da amostra seja igual à diferença da população. Para estimar melhor a diferença da população, use o intervalo de confiança da diferença.
O intervalo de confiança fornece um intervalo de valores prováveis para a diferença entre duas médias de população. Por exemplo, um nível de confiança de 95% indica que, se você extrair 100 amostras aleatórias da população, poderia esperar que, aproximadamente, 95 das amostras produza intervalos que contêm a diferença da população. O intervalo de confiança ajuda a avaliar a significância prática de seus resultados. Use seu conhecimento especializado para determinar se o intervalo de confiança inclui valores que tenham significância prática para a sua situação. Se o intervalo for muito amplo para ser útil, pense em aumentar o tamanho da amostra. Para obter mais informações, vá para Como obter um intervalo de confiança mais preciso.
Estimativa da diferença
| Diferença | IC de 95% para a Diferença |
|---|---|
| 21,00 | (14,22; 27,78) |
Principais resultados: Estimativa para diferença, IC de 95% para diferença
Nesses resultados, a estimativa da diferença da população em médias, em taxas hospitalares é de 21. Você pode ter 95% de confiança de que a média da população para a diferença está entre 14,22 e 27,78.
Etapa 2: Determine se a diferença é estatisticamente significativa
- Valor de p ≤ α: A diferença entre as médias é estatisticamente significativa (rejeite H0)
- Se o valor de p for menor ou igual ao nível de significância, você deve rejeitar a hipótese nula. É possível concluir que a diferença entre as médias da população não é igual à diferença hipotética. Se você não especificar uma diferença hipotética, o Minitab testa se não há diferença entre as médias (Diferença hipotética = 0)
- Valor de p > α: A diferença entre as médias não é estatisticamente significativa (não deve rejeitar H0)
- Se o valor de p for maior do que o nível de significância, você não deve rejeitar a hipótese nula. Não há evidências suficientes para concluir que a diferença entre as médias da população é estatisticamente significativa. Certifique-se de que o teste tenha poder suficiente para detectar uma diferença que seja significativa na prática. Para obter mais informações, acesse Poder e tamanho de amostra para teste t para 2 amostra.
Teste
| Hipótese nula | H₀: μ₁ - µ₂ = 0 |
|---|---|
| Hipótese alternativa | H₁: μ₁ - µ₂ ≠ 0 |
| Valor-T | GL | Valor-p |
|---|---|---|
| 6,31 | 32 | 0,000 |
Resultados principais: valor-p
Nestes resultados, a hipótese nula indica que a diferença na classificação média entre dois hospitais é 0. Como o valor-p é menor do que 0,00, que é menor que o nível de significância de 0,05, a decisão é pela rejeição da hipótese nula e conclui-se que as classificações dos hospitais são diferentes.
Etapa 3: Verifique se há problemas nos dados
Problemas com os dados, como assimetrias ou outliers, podem afetar desfavoravelmente seus resultados. Use gráficos para procurar assimetrias (ao examinar a dispersão dos dados de cada amostra) e para identificar os outliers potenciais.
Examine a dispersão de seus dados para determinar se eles parecem ser assimétricos.
Quando os dados são assimétricos, a maior parte dos dados está localizada no lado alto ou baixo do gráfico. Frequentemente, a assimetria é mais fácil de detectar com um histograma ou boxplot.
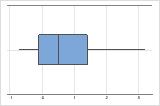
Assimétricos à direita
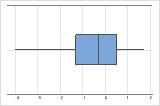
Assimétricos à esquerda
O boxplot com dados assimétricos à direita mostra os tempos de espera. A maioria dos tempos de espera são relativamente curtos e apenas alguns tempos de espera são longos. O boxplot com dados assimétricos à esquerda mostra os dados de tempos de falha. Alguns itens falham imediatamente e muitos outros itens falham posteriormente.
Os dados que são severamente assimétricos podem afetar a validade do valor-p se as amostras forem pequenas (ambas as amostras são menores que 15 valores). Se seus dados forem severamente assimétricos e você tiver uma pequena amostra, considere aumentar o tamanho amostral.
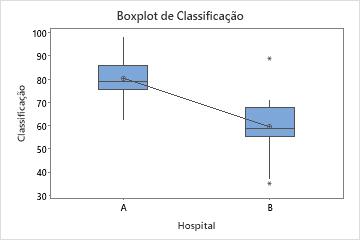
Saída da amostra
Nestes boxplots, os dados para Hospital B parecem ser severamente assimétricos.
Identificar outliers
Outliers, que são valores de dados que estão longe dos outros valores de dados, podem afetar fortemente os resultados da análise. Geralmente, outliers são a maneira mais fácil de identificar em um boxplot.
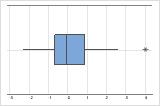
Em um boxplot, os asteriscos (*) identificam outliers.
Tente identificar a causa de todos os outliers. Corrija quaisquer erros de entrada de dados ou de medição. Considere remover valores de dados que estejam associados a eventos anormais, que ocorrem somente uma vez (também chamados de causas especiais). Em seguida, repita a análise. Para obter mais informações, acesse Identificação de outliers.
Saída da amostra
Nestes boxplots, os dados para Hospital B parecem ter 2 outliers.