Neste tópico
- Estatísticas
- Teste de hipótese para a diferença nas taxas para a aproximação normal
- Teste de hipótese para a diferença nas taxas para o método exato
- Teste de hipótese para a diferença nas taxas com o método de taxa combinada
- Teste de hipótese para uma diferença na média para o método de aproximação normal
- Teste de hipótese para a diferença nas diferenças para o método exato
- Teste de hipótese para a diferença nas médias para o método da média combinada
- Intervalo de confiança para a diferença nas taxas
- Limites de confiança para a diferença nas taxas
- Intervalo de confiança para a diferença nas médias
- Limites de confiança para a diferença nas médias
Estatísticas
| Termo | Descrição |
|---|---|
| taxa de ocorrência para a amostra i |
 |
| Termo | Descrição |
|---|---|
| número médio de ocorrências na amostra i |
 |
Teste de hipótese para a diferença nas taxas para a aproximação normal
Fórmula
O teste de aproximação normal baseia-se na seguinte estatística de Z, que é aproximadamente distribuída como uma distribuição normal padrão sob a hipótese nula.
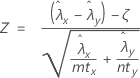
O Minitab usa as equações de valor de p para as respectivas hipóteses alternativas:
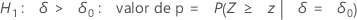
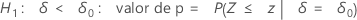

Notação
| Termo | Descrição |
|---|---|
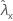 | valor observado da taxa para a amostra de X |
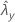 | valor observado da taxa para a amostra de Y |
| ζ | valor verdadeiro da diferença entre as taxas de população de duas amostras |
| ζ0 | valor hipotético da diferença entre as taxas da população de duas amostras |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
| tx | comprimento da amostra X |
| ty | comprimento da amostra Y |
Teste de hipótese para a diferença nas taxas para o método exato
Fórmula
Quando a diferença hipotética é igual a 0, o Minitab usa um procedimento exato para testar a hipótese nula a seguir:
H0: ζ = λx – λy = 0 ou H0: λx = λy
O procedimento exato baseia-se no fato a seguir, assumindo-se que a hipótese nula é verdadeira:
S | W ~ Binomial(w, p)
em que:


W = S + U


-
H1: ζ > 0: valor de p = P(S ≥ s | w = s + u, p = p0)
-
H1: ζ < 0: valor de p = P(S ≤ s | w = s + u, p = p0)
- H1: ζ ≠ 0:
- se P(S ≤ s | w = s + u, p = p0) ≤ 0,5 ou P(S ≥ s | w = s + u, p = p0) ≤ 0,5
então, o valor de p = 2 × min {P(S ≤ s | w = s + u, p = p0), P(S ≥ s | w = s + u, p = p0)}
- senão, o valor de p = 1,0
- se P(S ≤ s | w = s + u, p = p0) ≤ 0,5 ou P(S ≥ s | w = s + u, p = p0) ≤ 0,5
em que:

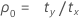
Notação
| Termo | Descrição |
|---|---|
 | valor observado da taxa para a amostra de X |
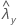 | valor observado da taxa para a amostra de Y |
| λx | valor verdadeiro da taxa para a população X |
| λy | valor verdadeiro da taxa para a população Y |
| ζ | valor verdadeiro da diferença entre as taxas de população de duas amostras |
| tx | comprimento da amostra X |
| ty | comprimento da amostra Y |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
Teste de hipótese para a diferença nas taxas com o método de taxa combinada
Quando você testar uma diferença de zero com a seguinte hipótese nula, você tem a opção de usar uma taxa combinada para ambas as amostras:

Fórmula
O procedimento de taxa combinada se baseia na seguinte estatística de Z, que é aproximadamente distribuída como uma distribuição normal padrão sob a seguinte hipótese nula:
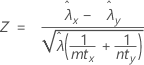
em que:
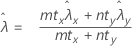
O Minitab usa as equações de valor de p para as respectivas hipóteses alternativas:

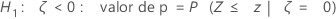

Notação
| Termo | Descrição |
|---|---|
 | valor observado da taxa para a amostra de X |
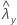 | valor observado da taxa para a amostra de Y |
| λx | valor verdadeiro da taxa para a população X |
| λy | valor verdadeiro da taxa para a população Y |
| ζ | valor verdadeiro da diferença entre as taxas de população de duas amostras |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
| tx | comprimento da amostra X |
| ty | comprimento da amostra Y |
Teste de hipótese para uma diferença na média para o método de aproximação normal
Fórmula
O teste de aproximação normal baseia-se na seguinte estatística de Z, que é aproximadamente distribuída como uma distribuição normal padrão sob a hipótese nula.
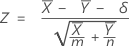
O Minitab usa as equações de valor de p para as respectivas hipóteses alternativas:
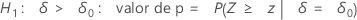
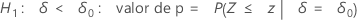

Notação
| Termo | Descrição |
|---|---|
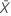 | valor observado do número médio de ocorrências na amostra X |
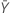 | valor observado do número médio de ocorrências na amostra Y |
| δ | valor verdadeiro da diferença entre as médias da população de duas amostras |
| δ 0 | valor hipotético da diferença entre as médias da população de duas amostras |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
Teste de hipótese para a diferença nas diferenças para o método exato
Fórmula

O procedimento exato baseia-se no fato a seguir, assumindo-se que a hipótese nula é verdadeira:
S | W ~ Binomial(w, p)
em que:


W = S + U
O Minitab usa as equações de valor de p para as respectivas hipóteses alternativas:
H1: δ > 0: valor de p = P(S ≥ s | w = s + u, δ = 0)
H1: δ < 0: valor de p = P(S ≤ s | w = s + u, δ = 0)
-
se P(S ≤ s|w = s + u, δ = 0) ≤ 0,5
ou P(S ≥ s|w = s + u, δ = 0) ≤ 0,5
então:

- senão, o valor de p = 1,0
Um teste bilateral não é um teste de igualdade de cauda, a menos que m = n.
Notação
| Termo | Descrição |
|---|---|
| μx | o verdadeiro valor do número médio de ocorrências na população X |
| μy | o verdadeiro valor do número médio de ocorrências na população Y |
| δ | valor verdadeiro da diferença entre as populações médias de duas amostras |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
Teste de hipótese para a diferença nas médias para o método da média combinada
Fórmula

O procedimento de média combinada se baseia no seguinte valor de Z, que é aproximadamente distribuída como uma distribuição normal padrão sob a seguinte hipótese nula:
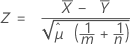
em que:
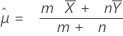
O Minitab usa as equações de valor de p para as respectivas hipóteses alternativas:
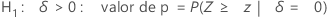
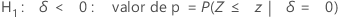
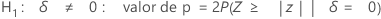
Notação
| Termo | Descrição |
|---|---|
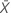 | valor observado do número médio de ocorrências na amostra X |
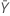 | valor observado do número médio de ocorrências na amostra Y |
| µx | o verdadeiro valor do número médio de ocorrências na população X |
| µy | o verdadeiro valor do número médio de ocorrências na população Y |
| δ | valor verdadeiro da diferença entre as populações médias de duas amostras |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
Intervalo de confiança para a diferença nas taxas
Fórmula
Um intervalo de confiança de 100(1 – α)% para a diferença entre as taxas de duas populações de Poisson é dada por:
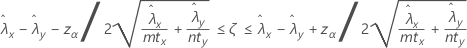
Notação
| Termo | Descrição |
|---|---|
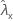 | valor observado da taxa para a amostra de X |
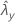 | valor observado da taxa para a amostra de Y |
| ζ | valor verdadeiro da diferença entre as taxas de população de duas amostras |
| zx | o ponto percentil superior x da distribuição normal padrão, em que 0 < x < 1 |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
| tx | comprimento da amostra X |
| ty | comprimento da amostra Y |
Limites de confiança para a diferença nas taxas
Fórmula
Quando você especifica um teste "maior que", um limite de confiança inferior de 100(1 – α)% para a diferença entre as taxas de duas populações de Poisson é dada por:
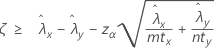
Quando você especifica um teste "menor que", um limite de confiança superior de 100(1 – α)% para a diferença entre as taxas de duas populações de Poisson é dada por:
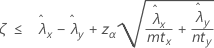
Notação
| Termo | Descrição |
|---|---|
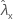 | valor observado da taxa para a amostra de X |
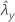 | valor observado da taxa para a amostra de Y |
| ζ | valor verdadeiro da diferença entre as taxas de população de duas amostras |
| zx | o ponto percentil superior x da distribuição normal padrão, em que 0 < x < 1 |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
| tx | comprimento da amostra X |
| ty | comprimento da amostra Y |
Intervalo de confiança para a diferença nas médias
Fórmula
Um intervalo de confiança de 100(1 – α)% para a diferença entre as taxas de duas populações médias de Poisson é dada por:
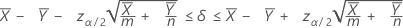
Notação
| Termo | Descrição |
|---|---|
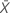 | valor observado do número médio de ocorrências na amostra X |
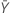 | valor observado do número médio de ocorrências na amostra Y |
| δ | valor verdadeiro da diferença entre as populações médias de duas amostras |
| zx | o ponto percentil superior x da distribuição normal padrão, em que 0 < x < 1 |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |
Limites de confiança para a diferença nas médias
Fórmula
Quando você especifica um teste "maior que", um limite de confiança inferior de 100(1 – α)% para a diferença entre as médias de duas populações de Poisson é dada por:
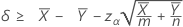
Quando você especifica um teste "menor que", um limite de confiança superior de 100(1 – α)% para a diferença entre as médias de duas populações de Poisson é dada por:
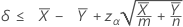
Notação
| Termo | Descrição |
|---|---|
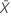 | valor observado do número médio de ocorrências na amostra X |
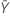 | valor observado do número médio de ocorrências na amostra Y |
| δ | valor verdadeiro da diferença entre as populações médias de duas amostras |
| zx | o ponto percentil superior x da distribuição normal padrão, em que 0 < x < 1 |
| m | tamanho amostral da amostra X |
| n | tamanho amostral da amostra Y |