Neste tópico
Etapa 1: Determine um intervalo de confiança para a média da população
Primeiro, considere a média da amostra e depois examine o intervalo de confiança.
A média dos dados das amostras é uma estimativa da média da população. Como a média é baseada em dados da amostra e não na população total, é improvável que a média da amostra seja igual à média da população. Para estimar melhor a média da população, use o intervalo de confiança.
O intervalo de confiança fornece um intervalo de valores possíveis para a média da população. Por exemplo, um nível de confiança de 95% indica que, se você extrair 100 amostras aleatórias da população, poderia esperar que, aproximadamente, 95 das amostras produza intervalos que contêm a média da população. O intervalo de confiança ajuda a avaliar a significância prática de seus resultados. Use seu conhecimento especializado para determinar se o intervalo de confiança inclui valores que tenham significância prática para a sua situação. Se o intervalo for muito amplo para ser útil, pense em aumentar o tamanho da amostra. Para obter mais informações, vá para Como obter um intervalo de confiança mais preciso.
Estatísticas Descritivas
| N | Média | DesvPad | EP Média | IC de 95% para μ |
|---|---|---|---|---|
| 20 | 16,460 | 2,258 | 0,581 | (15,321; 17,599) |
Principais resultados: média, IC de 95%
Nestes resultados, a estimativa da média da população para porcentagem de gordura é de 16,46%. Você pode ter 95% de confiança de que a média da população está entre 15,321% e 17,599%.
Etapa 2: Determine se os resultados do teste são estatisticamente significativos
- Valor de p ≤ α: A diferença entre as médias é estatisticamente significativa (rejeite H0)
- Se o valor de p for menor ou igual ao nível de significância, você deve rejeitar a hipótese nula. É possível concluir que a diferença entre a média da população e a média hipotética é estatisticamente significativa. Use seu conhecimento especializado para determinar se a diferença é praticamente significativa. Para obter mais informações, acesse Significância estatística e prática.
- Valor de p > α: A diferença entre as médias não é estatisticamente significativa (não deve rejeitar H0)
- Se o valor de p for maior do que o nível de significância, você não deve rejeitar a hipótese nula. Não há evidências suficientes para concluir que a diferença entre a média da população e a média hipotética é estatisticamente significativa. Certifique-se de que o teste tenha poder suficiente para detectar uma diferença que seja significativa na prática. Para obter mais informações, acesse Poder e tamanho de amostra para teste Z para 1 amostra.
Estatísticas Descritivas
| N | Média | DesvPad | EP Média | IC de 95% para μ |
|---|---|---|---|---|
| 20 | 16,460 | 2,258 | 0,581 | (15,321; 17,599) |
Teste
| Hipótese nula | H₀: μ = 15 |
|---|---|
| Hipótese alternativa | H₁: μ ≠ 15 |
| Valor-Z | Valor-p |
|---|---|
| 2,51 | 0,012 |
Resultados principais: valor-p
Nestes resultados, a hipótese nula afirma que a porcentagem média de gordura é de 15%. Como o valor-p é 0,012, que é menor que o nível de significância de 0,05, a decisão é rejeitar a hipótese nula e concluir que o percentual de gordura médio da população é diferente de 15%.
Etapa 3: Verifique se há problemas nos dados
Problemas com os dados, como assimetrias ou outliers, podem afetar desfavoravelmente seus resultados. Use gráficos para procurar assimetrias e para identificar os outliers potenciais.
Examine a dispersão de seus dados para determinar se eles parecem ser assimétricos.
Quando os dados são assimétricos, a maior parte dos dados está localizada no lado alto ou baixo do gráfico. Frequentemente, a assimetria é mais fácil de detectar com um histograma ou boxplot.
Assimétricos à direita
Assimétricos à esquerda
O histograma com dados assimétricos à direita mostra os tempos de espera. A maioria dos tempos de espera são relativamente curtos e apenas alguns tempos de espera são longos. O histograma com dados assimétricos à esquerda mostra os dados de tempos de falha. Alguns itens falham imediatamente e muitos outros itens falham posteriormente.
Os dados que são severamente assimétricos podem afetar a validade do valor-p se a amostra for pequena (menor que 20 valores). Se seus dados forem severamente assimétricos e você tiver uma pequena amostra, considere aumentar o tamanho amostral.
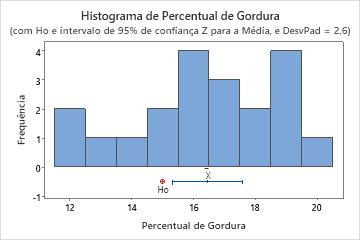
Neste histograma, os dados não parecem estar severamente assimétricos.
Identificar outliers
Outliers, que são valores de dados que estão longe dos outros valores de dados, podem afetar fortemente os resultados da análise. Geralmente, outliers são a maneira mais fácil de identificar em um boxplot.
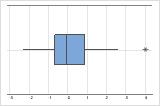
Em um boxplot, os asteriscos (*) identificam outliers.
Tente identificar a causa de todos os outliers. Corrija quaisquer erros de entrada de dados ou de medição. Considere remover valores de dados que estejam associados a eventos anormais, que ocorrem somente uma vez (também chamados de causas especiais). Em seguida, repita a análise. Para obter mais informações, acesse Identificação de outliers.
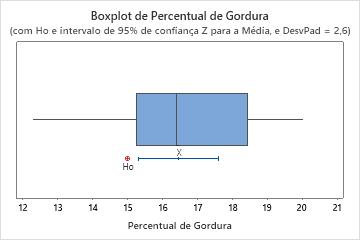
Neste boxplot, não existem outliers.