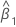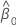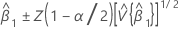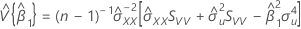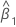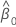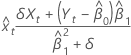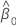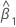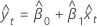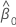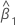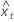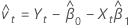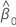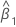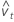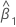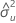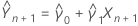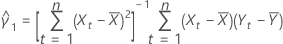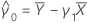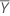Na regressão ortogonal, a melhor linha de ajuste é aquela que minimiza as distâncias ortogonais ponderadas dos pontos traçados para a linha. Se a razão de variância de erro for 1, as distâncias ponderadas são distâncias euclidianas.
Notação
Termo
Descrição
Yt
resposta observada
β0
intercepto
β1
inclinação
Xt
preditora observada
xt
valor verdadeiro e não observado da preditora
et, ut
erros de medição; et, ut são independentes com média 0 e variâncias de erro de δe2 e δu2
Matriz de covariância da amostra
Permita que a média da amostra seja (, ) e a matriz de covariância da amostra seja:
mZZ é uma matriz simétrica 2X2:
Notação
Termo
Descrição
Zt
(Yt, Xt)
n
tamanho da amostra
Variâncias dos erros
A matriz de covariância da amostra é uma matriz 2 x 2:
Se o elemento mXY da matriz de covariância da amostra não é igual a 0, então:
Se mXY = 0 e mYY < δmXX,
Se mXY = 0 e mYY > δmXX, as estimativas de parâmetro restantes são indefinidas.
Notação
Termo
Descrição
estimativa da variância de erro para X
estimativa da variância de erro para Y
δ
razão de variâncias de erro
mXY
elemento da matriz de covariância da amostra
mYY
elemento da matriz de covariância da amostra
mXX
elemento da matriz de covariância da amostra
Coeficientes
Se o elemento mXY da matriz de covariância da amostra não é igual a 0, então:
Se mxy = 0 e myy < δm xx','
Se mxy = 0 e myy > δmxx, as estimativas de parâmetro restantes são indefinidas.
Notação
Termo
Descrição
estimativa da inclinação
estimativa do intercepto
mxy
elemento da matriz de covariância da amostra
myy
elemento da matriz de covariância da amostra
δ
razão de variâncias de erro
média de valores de resposta
média de valores da preditora
Matriz de covariância da distribuição aproximada
Uma estimativa da matriz de covariância da distribuição aproximada do intercepto e da inclinação:
em que:
e
Se mXY não for igual a 0:
Se mXY é igual a 0 e mYY < δmXX:
Notação
Termo
Descrição
estimativa da inclinação
estimativa do intercepto
mXY
elemento da matriz de covariância da amostra
mYY
elemento da matriz de covariância da amostra
mXX
elemento da matriz de covariância da amostra
δ
razão de variâncias de erro
média de valores de resposta
média de valores da preditora
Intervalo de confiança para intercepto
O intervalo de confiança de 100(1 - α)% para β0 é:
onde:
Z (1 - α / 2) é o percentil 100 * (1 - α / 2 ) para a distribuição normal padrão
e
, que é um elemento na matriz de covariância da distribuição aproximada
Notação
Termo
Descrição
estimativa da inclinação
estimativa do intercepto
α
nível de significância
Intervalo de confiança para inclinação
O intervalo de confiança de 100(1 - α)% para β1 é:
em que:
Z(1 - α / 2) é o percentil 100 * (1 - α / 2) da distribuição normal padrão
e
Notação
Termo
Descrição
estimativa da inclinação
estimativa do intercepto
α
nível de significância
Valores ajustados de x
O valor ajustado da preditora x na regressão ortogonal é:
Notação
Termo
Descrição
δ
razão de variâncias de erro
Yt
tésimo valor de resposta
estimativa do intercepto
estimativa da inclinação
Valores ajustados para y
O valor ajustado para a resposta y na regressão ortogonal é:
Notação
Termo
Descrição
estimativa do intercepto
estimativa da inclinação
tésimo valor ajustado para x
Resíduos
O resíduo de uma observação na regressão ortogonal é:
Notação
Termo
Descrição
Yt
tésimo valor de resposta
intercepto
Xt
tésimo valor da preditora
inclinação
Resíduos padronizados
O resíduo padronizado é útil na identificação de outliers. Ele é calculado como:
onde
Notação
Termo
Descrição
de resíduos
desvio padrão do resíduo
δ
razão da variância do erro
estimativa da inclinação
estimativa da variância de erro para X
Preditora de Y
A preditora de Yn + 1 é:
em que:
e
Notação
Termo
Descrição
Xt
tésimo valor da preditora
média de valores da preditora
Yt
tésimo valor de resposta
média de valores de resposta
Desvio padrão para o erro de predição
em que:
Notação
Termo
Descrição
myy
variância da amostra de Y
mxy
covariância da amostra entre as variáveis aleatórias X e Y
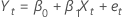
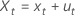
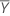 ,
, 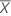 ) e a matriz de covariância da amostra seja:
) e a matriz de covariância da amostra seja:

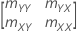


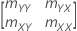
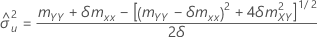
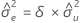

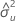

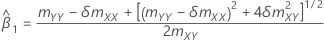
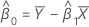


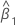
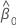
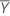
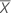
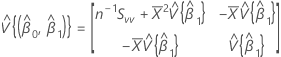
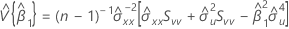

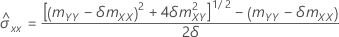
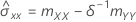

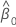
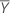
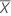
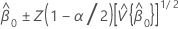
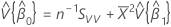 , que é um elemento na matriz de covariância da distribuição aproximada
, que é um elemento na matriz de covariância da distribuição aproximada