Neste tópico
Função de ligação
O Minitab fornece três funções de ligação: logit (o padrão), normit e gompit. As funções de ligação permitem ajustar uma ampla variedade de modelos de resposta ordinal. O logit é o inverso da função de distribuição logística acumulada padrão. A função normit, também conhecida como probit, é o inverso da função de distribuição normal acumulada padrão. A função gompit, também conhecida como log-log complementar, é o inverso da função de distribuição Gompertz.
Fórmula
g(χk) = θk +x'β, k = 1, ..., K-1
Uma função de ligação é o inverso de uma função de distribuição. As funções de ligação e suas distribuições correspondentes são resumidas a seguir:
| Nome | Função de ligação | Distribuição |
|---|---|---|
| logit | g(χ) = loge(χ/ (1 – χ)) | logística |
| normit (probit) |
g(χ) = Φ–1(χ) |
normal |
| gompit (log-log complementar) | g(χ) =loge (–loge(1 – χ)) | Gompertz |
Notação
| Termo | Descrição |
|---|---|
| K | número de categorias distintas da resposta |
| χk | probabilidade acumulada até e incluindo a categoria k, (π1+ ...+ πk) |
| g(χk) | vetor das variáveis preditoras |
| θk | constante associada à késimacategoria de resposta distinta |
| x | um vetor das variáveis preditoras |
| β | um vetor dos coeficientes associados às preditoras |
Padrão de fator/covariável
Descreve um conjunto único de valores de fator/covariável em um conjunto de dados. O Minitab calcula probabilidades de evento, resíduos e outras medidas diagnósticas para cada padrão de fator/covariável.
Por exemplo, se um conjunto de dados inclui os fatores sexo e raça e a covariável idade, a combinação dessas preditoras pode conter tantos padrões de covariáveis diferentes quanto de indivíduos. Se um conjunto de dados só inclui os fatores raça e sexo, cada um codificado em dois níveis, só há quatro padrões de fator/covariáveis possíveis. Se você inserir seus dados como frequências, ou como sucessos, tentativas ou falhas, cada linha conterá um padrão de fator/covariável.
Probabilidade de evento
As probabilidades de evento são as πk para k = 1, 2, ..., K.
Fórmula
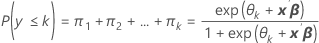
Notação
| Termo | Descrição |
|---|---|
| k | é igual a 1, ..., K – 1 |
| θk | constante |
| β | vetor de coeficientes da equação do logit |
Probabilidade de evento acumulado
A probabilidade de que a resposta caia na categoria k ou abaixo, para cada k possível. A késima probabilidade acumulada é:
Fórmula
P(y k) = p1 + ... + pk,k = 1, ... , K
k) = p1 + ... + pk,k = 1, ... , K
As probabilidades acumuladas reflete a ordem da resposta. Para um modelo com k categorias de resposta:
P(y 1) <P(y
1) <P(y 2)
2)  …
… P(y
P(y K) = 1
K) = 1

Coeficiente
O Minitab usa o modelo de chances proporcionais onde um vetor das preditoras, x, tem um parâmetro β que descreve o efeito do x nas log de chances da resposta na categoria k ou abaixo. O Minitab supõe um efeito idêntico de x para todas as categorias K – 1, portanto somente 1 coeficiente é calculado para cada preditora. O coeficiente da preditora indica que para qualquer k fixo, a mudança estimada no logit da resposta quando a preditora estiver em um nível comparado ao nível de referência.
O Minitab estima uma constante para cada categoria K – 1. Use as estimativas de parâmetro para calcular as probabilidades estimadas para cada categoria usando o modelo para as probabilidades acumuladas:
Fórmula
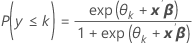
Os coeficientes estimados são calculados usando-se um método de mínimos quadrados reponderados iterativo, que é equivalente à estimativa de máxima verossimilhança.1,2
Referências
- D.W. Hosmer and S. Lemeshow (2000). Applied Logistic Regression. 2a. ed. John Wiley & Sons, Inc.
- P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Erro padrão de coeficientes
O erro padrão assintótico, que indica a precisão do coeficiente estimado. Quanto menor o erro padrão, mais precisa é a estimativa.
Consulte [1] e [2] para obter mais informações.
- A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
- P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Z
A estatística-Z usada para determinar se a preditora está significativamente relacionada à resposta. Valores absolutos maiores de Z indicam uma relação significativa. O valor-p indica on Z cai na distribuição normal.
Fórmula
Z = βi / erro padrão
A fórmula da constante é:
Z = θk / erro padrão
Para pequenas amostras, o teste de razão de verossimilhança pode ser um teste mais confiável de significância.
valor-p (P)
Usado nos testes de hipóteses para ajudá-lo a decidir se deve rejeitar ou não rejeitar uma hipótese nula. O valor-p é a probabilidade de se obter uma estatística de teste que seja pelo menos tão extrema quanto o valor calculado real, se a hipótese nula for verdadeira. Um valor cortado comumente usado para o valor-p é 0,05. Por exemplo, se o valor-p calculado de uma estatística de teste for menor do que 0,05, você rejeita a hipótese nula.
Razão de chances
O Minitab usa um modelo de chances proporcional para regressão logística ordinal. Somente um parâmetro e um razão de chances são calculados para cada preditora. A razão de chances utiliza probabilidades acumuladas e seus complementos. Para uma preditora com 2 níveis x1 e x2, a razão de chances acumuladas é:
Fórmula
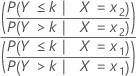
Intervalo de confiança
Fórmula
O intervalo de confiança da amostra maior para βi é:
β i + Zα /2* (erro padrão)
Para obter o intervalo de confiança das razões de chances, exponencie os limites inferior e superior do intervalo de confiança. O intervalo fornece a amplitude no qual as chances podem se encaixar para cada mudança de unidade na preditora.
Notação
| Termo | Descrição |
|---|---|
| α | nível de significância |
Log-verossimilhança
Derivado das funções de densidade de probabilidade individual, a expressão é maximizada para resultar de valores ótimos de β. O log-verossimilhança não pode ser usado sozinho como uma medida de ajuste porque ele depende do tamanho da amostra, mas pode ser usado para comprar dois modelos.
Para regressão logística ordinal, há n vetores multinomiais independentes, cada um comk categorias. Essas observações são denotadas por y1, ..., yn, onde yi = (yi1, ..., yik) e Σjyij = mi está fixa para cada i. A partir da iésima observação yi, a contribuição para a log-verossimilhança é:
Fórmula
L(πi ; yi) = Σkyik log πik
A log-verossimilhança total é uma soma das contribuições de cada uma das observações n:
L(π ; y) = Σi L(πi; yi)
Notação
| Termo | Descrição |
|---|---|
| πik | probabilidade da iésima observação para a késima categoria |
Matriz de variância-covariância
Uma matriz quadrada com as dimensões p + K – 1. A variância de cada coeficiente está na célula diagonal e a covariância de cada par de coeficientes está na célula fora da diagonal apropriada. A variância é o erro padrão do coeficiente quadrado.
A matriz de variância-covariância é assintótica e é obtida da iteração final do inverso da matriz de informação.
Notação
| Termo | Descrição |
|---|---|
| p | número de preditoras |
| K | número de categorias na resposta |
Pearson
Uma estatística de resumo baseada nos resíduos de Pearson que indica quão bem o modelo se ajusta aos seus dados. A Pearson não é útil quando o número de valores distintos da covariável é aproximadamente igual ao número de observações, mas é útil quando você tem observações repetidas no mesmo nível das covariáveis. Valores maiores de estatísticas de teste χ2 e valores inferiores do valor-p indicam que o modelo pode não se ajustar bem aos dados.
A fórmula é:
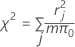
onde r = Pearson residual, m = número de ensaios no jésimo padrão de fator/covariável, e π0 = valor hipotético para a proporção.
Deviance
Um estatística de resumo baseada nos resíduos Deviance que indica quão bem o modelo se ajusta aos seus dados. O Deviance não é útil quando o número de valores distintos é aproximadamente igual ao número de observações, mas o teste é útil quando você tem observações repetidas no mesmo nível das covariáveis. Valores maiores de D e valores inferiores de valor-p indicam que o modelo pode não se ajustar bem aos dados. Os graus de liberdade para o teste é (k - 1)*J − (p) onde k é o número de categorias na resposta, J é o número de padrões de fator/covariável distintos e p é o número de coeficientes.
A fórmula é:
D =2 Σ yik log p ik− 2 Σ yik log π ik
onde πik = probabilidade da iésima observação para a késima categoria.
Medidas de associação
Pares concordantes e discordantes indicam quão bem o modelo prediz os dados. Quanto mais pares concordantes você tem, melhor é a capacidade preditiva do modelo.
A tabela de pares concordantes, discordantes e empatados é calculada ao formar todos os pares possíveis de observações com valores de resposta diferentes. Suponha que os valores de resposta sejam 1, 2 e 3. O Minitab pareia cada observação com o valor de resposta 1 com todas as observações com valores de resposta de 2 e 3 e depois pareia todas as observações com o valor de resposta 2 com todas as observações com valores de resposta 1 e 3. O número total de pares é igual ao número de observações com resposta de 1 multiplicado pelo número de observações com a resposta de 2 mais o número de observações com resposta de 1 multiplicado pelo número de observações com a resposta de 3 mais o número de observações com resposta de 2 multiplicado pelo número de observações com a resposta de 3.
Para determinar se os pares são concordantes ou discordantes, o Minitab calcula as probabilidade acumuladas preditas de cada observação e compara esses valores para cada par de observações.
- Concordante
- Para pares que incluem o menor valor de resposta (no exemplo acima, que é 1), um par é concordante se a probabilidade acumulada até o menor valor de resposta for maior para a observação com o menor valor de resposta do que para a observação com o maior valor de resposta. Para pares com os maiores valores de resposta (no exemplo acima, os pares com 2 e 3), um par é concordante se a probabilidade acumulada de até 2 for maior para a observação com o valor de resposta 2 do que a observação com o valor de resposta 3.
- Discordante
- Para pares que incluem o menor valor de resposta (no exemplo acima, que é 1), um par é discordante se a probabilidade acumulada até o menor valor de resposta for maior para a observação com o maior valor de resposta do que para a observação com o menor valor de resposta. Para pares com os maiores valores de resposta (no exemplo acima, pares com 2 e 3), um par é discordante se a probabilidade acumulada de até 2 for maior para a observação com o valor de resposta 3 do que a observação com o valor de resposta 2.
- Empates
- Um par está empatado se as observações tiverem probabilidades acumuladas iguais.
Fórmula
Na tabela de concordantes, discordantes e pares empatados, o Minitab calcula as seguintes medidas de resumo:



Notação
| Termo | Descrição |
|---|---|
| nc | número de pares concordantes |
| nd | número de pares discordantes |
| nt | número de pares empatados |
| N | número de observações total |