Neste tópico
Coeficientes
Existem dois métodos para encontrar as estimativas de verossimilhança máxima dos coeficientes. Um método é para maximizar diretamente a função de verossimilhança com respeito aos coeficientes. Essas expressões são não-lineares nos coeficientes. O método alternativo é usar uma abordagem iterativa repesada de quadrados mínimos (IRWLS), que é o método que o Minitab usa para obter as estimativas dos coeficientes. McCullagh e Nelder1 mostram que os dois métodos são equivalentes. Contudo, o método iterativo por mínimos quadrados reponderados é mais fácil de implementar. Para detalhes, consulte 1.
Método de aproximação de uma etapa para alguns casos de validação cruzada k-fold
Para alguns projetos de grande amostra com muitas dobras de validação cruzada, o Minitab usa um método de aproximação de uma etapa no algoritmo de validação cruzada para diminuir o tempo de cálculo (ver Pregibon2 e Williams3). Para esses desenhos, em vez de encaixar o modelo de treinamento para uma dobra com o algoritmo IRWLS para a convergência total, as estatísticas de validação cruzada para a dobra vêm dos parâmetros de regressão do primeiro passo iterativo do algoritmo.
A tabela a seguir mostra quais projetos recebem estatísticas de validação cruzada a partir da aproximação de 1 passo.
| Tamanho de amostra (n) | Número de colunas na matriz de design (p) | Número de dobras (k) |
|---|---|---|
| 200 < n ≤ 500 | 150 < p ≤ 300 | k > 200 |
| p > 300 | k > 100 | |
| 500 < n ≤ 1000 | 100 < p ≤ 300 | k > 300 |
| p > 300 | k > 150 | |
| 1000 < n ≤ 10,000 | p ≤ 50 | k > 1.000 |
| 50 < p ≤ 200 | k > 200 | |
| 200 < p ≤ 400 | k > 50 | |
| p > 400 | k > 10 | |
| 10,000 < n ≤ 50,000 | p ≤ 50 | k > 200 |
| 50 < p ≤ 200 | k > 100 | |
| p > 200 | k > 20 | |
| 50,000 < n ≤ 100,000 | p ≤ 50 | k > 100 |
| 50 < p ≤ 150 | k > 50 | |
| p > 150 | k > 20 | |
| n > 100.000 | Qualquer valor de p | k > 100 |
Algoritmo de aproximação de um passo
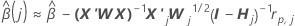
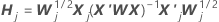
Notação
| Termo | Descrição |
|---|---|
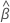 | os coeficientes estimados se encaixam com o conjunto de dados completo |
| X | a matriz de design para o conjunto de dados completo |
| X' | o transverso da matriz de design para o conjunto de dados completo |
| W | a matriz de peso para o conjunto de dados completo |
| X'j | a matriz de design para os dados na dobra jth |
| Wj | a matriz de peso para os dados na dobra jth |
| Eu | a matriz de identidade |
| rp.j | o vetor de resíduos Pearson do modelo para o conjunto de dados completos para os dados na dobra jth |
[1] P. McCullagh e J. A. Nelder (1989). Modelos Lineares Generalizados, 2nd Ed., Chapman & Hall/CRC, Londres.
[2] D. Pregibon (1981). Diagnósticos de regressão logística. The Annals of Statistics, 9(4), 705-724.
[3] D. A. Williams (1987). Diagnósticos de modelo linear generalizados utilizando o desvio e exclusões de caso único, Estatísticas Aplicadas, 36(2), 181-191.
Erro padrão de coeficientes
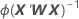
W é uma matriz diagonal onde os elementos diagonais são dados pela seguinte fórmula:
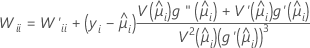
onde

Esta matriz de variância-covariância está baseada na matriz Hessiana observada em oposição à matriz de informação de Fisher. O Minitab usa a matriz Hessiana observada porque o modelo que resulta é mais robusto contra qualquer especificação incorreta média condicional.
Se a ligação canônica for usada, a matriz Hessiana observada e a matriz de informações de Fisher são idênticas.
Notação
| Termo | Descrição |
|---|---|
| yi | o valor de resposta da iésima linha |
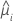 | a resposta média estimada da iésima linha |
| V(·) | a função de variância dada na tabela a seguir |
| g(·) | a função de ligação |
| V '(·) | o primeiro derivativo da função de variância |
| g'(·) | o primeiro derivativo da função de ligação |
| g''(·) | o segundo derivativo da função de ligação |
A função de variância depende do modelo:
| Modelo | Função de variância |
| Binomial | 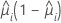 |
| Poisson | 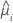 |
Consulte [1] e [2] para obter mais informações.
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Z
A estatística-Z usada para determinar se a preditora está significativamente relacionada à resposta. Valores absolutos maiores de Z indicam uma relação significativa. A fórmula é:
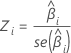
Notação
| Termo | Descrição |
|---|---|
| Zi | A estatística de teste para uma distribuição normal padrão |
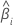 | O coeficiente estimado |
 | O erro padrão do coeficiente estimado |
Para pequenas amostras, o teste de razão de verossimilhança pode ser um teste mais confiável de significância. Os valores-p da razão de verossimilhança estão na tabela deviance. Quando o tamanho amostral é grande o bastante, os valores-p das estatísticas Z aproximam os valores-p das estatísticas da razão de verossimilhança.
valor-p (P)
Usado nos testes de hipóteses para ajudá-lo a decidir se deve rejeitar ou não rejeitar uma hipótese nula. O valor-p é a probabilidade de se obter uma estatística de teste que seja pelo menos tão extrema quanto o valor calculado real, se a hipótese nula for verdadeira. Um valor cortado comumente usado para o valor-p é 0,05. Por exemplo, se o valor-p calculado de uma estatística de teste for menor do que 0,05, você rejeita a hipótese nula.
Razões de chances para regressão logística binária
A razão de chances é fornecida somente se você selecionar a função de ligação do logit para um modelo com uma resposta binária. Neste caso, a razão de chances é útil na interpretação da relação entre uma preditora e uma resposta.
A razão de chances (q) pode ser qualquer número não negativo. A razão de chances de 1 serve como a linha de base para comparação. Se τ = 1, não há associação entre a resposta e a preditora. Se τ < 1, as chances do evento são maiores para o nível de referência do fator (ou para níveis mais altos de uma preditora contínua). Se τ > 1, as chances do evento são menores para o nível de referência do fator (ou para níveis menores de uma preditora contínua). Os valores mais distantes de 1 representam graus mais fortes de associação.
Observação
Para o modelo de regressão logística binária com uma covariável ou fator, as chances estimadas de sucesso são:
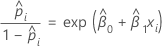
A relação exponencial fornece uma interpretação para β: as chances aumentam multiplicativamente por eβ1 para cada aumento de uma unidade em x. A razão de chances é equivalente a exp(β1).
Por exemplo, se βfor 0,75, a razão de chances é exp(0,75), que é 2,11. Isso indica que há um aumento de 111% nas chances de sucesso para cada aumento de uma unidade em x.
Notação
| Termo | Descrição |
|---|---|
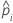 | a probabilidade estimada de um sucesso para a iésima linha nos dados |
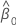 | o coeficiente intercepto estimado |
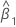 | o coeficiente estimado para preditora x |
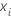 | o ponto de dados para a iésima linha |
Intervalo de confiança
O grande intervalo de confiança da amostra de um coeficiente estimado é:
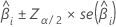
Para regressão logística binária, o Minitab fornece intervalos de confiança para as razões de chances. Para obter o intervalo de confiança das razões de chances, exponencie os limites inferior e superior do intervalo de confiança. O intervalo fornece o intervalo no qual as chances podem se encaixar para mudança de unidade na preditora.
Notação
| Termo | Descrição |
|---|---|
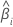 | o iésimo coeficiente |
 | a probabilidade acumulada inversa da distribuição normal padrão em 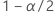 |
 | o nível de significância |
 | o erro padrão do coeficiente estimado |
Matriz de variância-covariância
Uma matriz d x d, onde d é o número de preditoras mais um. A variância de cada coeficiente está na célula diagonal e a covariância de cada par de coeficientes está na célula fora da diagonal apropriada. A variância é o erro padrão do coeficiente quadrado.
A matriz de variância-covariância é da iteração final do inverso da matriz de informação. A matriz de variância-covariância tem a seguinte forma:
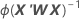
W é uma matriz diagonal onde os elementos diagonais são dados pela seguinte fórmula:

onde

Esta matriz de variância-covariância está baseada na matriz Hessiana observada em oposição à matriz de informação de Fisher. O Minitab usa a matriz Hessiana observada porque o modelo que resulta é mais robusto contra qualquer especificação incorreta média condicional.
Se a ligação canônica for usada, a matriz Hessiana observada e a matriz de informações de Fisher são idênticas.
Notação
| Termo | Descrição |
|---|---|
| yi | o valor de resposta da iésima linha |
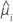 | a resposta média estimada da iésima linha |
| V(·) | a função de variância dada na tabela a seguir |
| g(·) | a função de ligação♣ |
| V '(·) | o primeiro derivativo da função de variância |
| g'(·) | o primeiro derivativo da função de ligação |
| g''(·) | o segundo derivativo da função de ligação |
A função de variância depende do modelo:
| Modelo | Função de variância |
| Binomial | 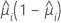 |
| Poisson | 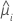 |
Consulte [1] e [2] para obter mais informações.
[1] A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
[2] P. McCullagh and J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.