Observação
Este comando está disponível com o Módulo de análise preditiva. Clique aqui saber mais sobre como ativar o módulo.
Uma equipe de pesquisadores coleta dados da venda de propriedades residenciais individuais em Ames, Iowa. Os pesquisadores querem identificar as variáveis que afetam o preço de venda. As variáveis incluem o tamanho do lote e várias características do imóvel residencial.
Após a exploração inicial com Regressão CART® para identificar os preditores importantes, a equipe usa Regressão Random Forests® para criar um modelo mais intensivo a partir do mesmo conjunto de dados. Os equipe compara a tabela de sumário do modelo e o gráfico R2 dos resultados para avaliar qual modelo proporciona um resultado de predição melhor.
Esses dados foram adaptados com base em um conjunto de dados públicos contendo informações sobre os dados habitacionais de Ames. Dados originais de DeCock, Truman State University.
- Abra os dados amostrais Habitação_Ames.MWX.
- Selecione .
- Em Resposta, insira ‘Preço de venda’.
- Em Preditores contínuos, digite ‘frontage lot' – 'ano vendido’.
- Em Preditores categóricos, digite ‘tipo' – 'Condição de venda’.
- Clique em Opções.
- Em Número de preditores para divisão do nó, selecione K por cento do número total de preditores; K = e insira 30. Os pesquisadores querem usar mais do que o número padrão de preditores para esta análise.
- Clique em OK em cada caixa de diálogo.
Interprete os resultados
Método
| Validação do modelo | Validação com dados usando método out-of-bag |
|---|---|
| Número de amostras bootstrap | 300 |
| Tamanho amostral | O mesmo que o tamanho dos dados de treinamento de 2930 |
| Número de preditores selecionados para divisão de nós | 30% do número total de preditores = 23 |
| Tamanho mínimo do nó interno | 5 |
| Linhas usadas | 2930 |
Informações da Resposta
| Média | DesvPad | Mínimo | Q1 | Mediana | Q3 | Máximo |
|---|---|---|---|---|---|---|
| 180796 | 79886,7 | 12789 | 129500 | 160000 | 213500 | 755000 |
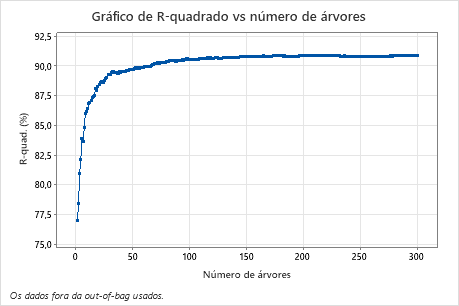
O gráfico R-quadrado vs número de árvores mostra toda a curva sobre o número de árvores cultivadas. O valor de R2 aumenta rapidamente à medida que o número de árvores aumenta e se achata em aproximadamente 91%.
Sumário do modelo
| Preditores totais | 77 |
|---|---|
| Preditores importantes | 68 |
| Estatísticas | Out-of-Bag |
|---|---|
| R-quadrado | 90,90% |
| Raiz do quadrado médio do Erro (RMSE) | 24097,3281 |
| Quadrado médio do erro (MSE) | 5,80681E+08 |
| Desvio absoluto médio (DAM) | 14746,8323 |
| Erro percentual absoluto médio (MAPE) | 0,0895 |
A tabela de resumo do modelo mostra que os valores de R2 são ligeiramente melhorados em relação aos valores de R2 da análise CART® correspondente.
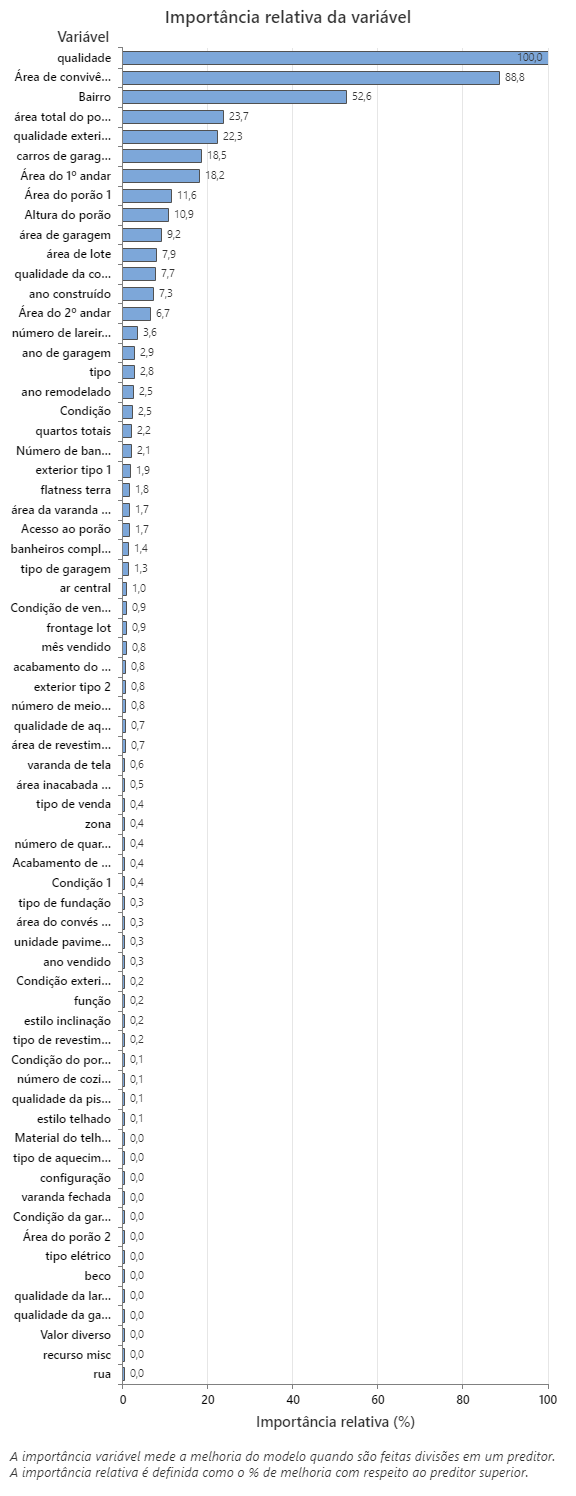
O gráfico de importância relativa da variável representa os preditores por ordem de seu efeito sobre a melhoria do modelo quando as divisões são feitas em um preditor sobre a sequência de árvores. A variável preditora mais importante para predizer o preço de venda é Quality. Se a importância da principal variável preditora, Qualidade, é de 100%, então a próxima variável importante, Área de Vida SF, tem uma contribuição de 88,8%. Isso significa que a metragem quadrada da vida é 88,8% tão importante quanto a qualidade geral da propriedade. A próxima variável mais importante é o Bairro, que tem uma contribuição de 52,6%.
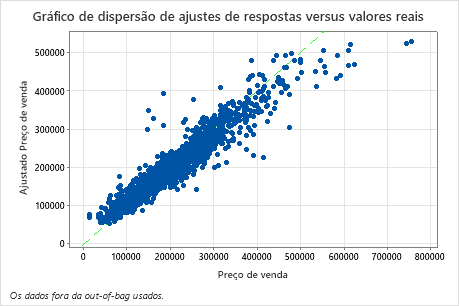
O gráfico de dispersão do preço de venda ajustado versus preço de venda real mostra a relação entre os valores ajustados e reais para os dados OOB. Você pode passar o mouse sobre os pontos no gráfico para ver mais facilmente os valores representados graficamente. Neste exemplo, muitos pontos ficam aproximadamente perto da linha de referência de y=x, mas vários pontos podem precisar de investigação para ver discrepâncias entre valores ajustados e reais.