Observação
Este comando está disponível com o Módulo de análise preditiva. Clique aqui saber mais sobre como ativar o módulo.
Um modelo de Random Forests® é uma abordagem para resolver problemas de classificação e regressão. A abordagem é ao mesmo tempo mais precisa e mais robusta para mudanças nas variáveis preditoras do que uma única árvore de classificação ou regressão. Uma descrição ampla e geral do processo é que o Minitab Statistical Software constrói uma única árvore a partir de uma amostra por bootstrap. O Minitab seleciona aleatoriamente um número menor de preditores do número total de preditores para avaliar o melhor divisor em cada nó. O Minitab repete esse processo para cultivar muitas árvores. No caso de classificação, a classificação de cada árvore é um voto para a classificação predita. Para uma determinada linha de dados, a classe com mais votos é a classe predita para essa linha no conjunto de dados.
Para construir uma árvore de classificação, o algoritmo usa o critério de Gini para medir a impureza dos nódulos. Para o aplicativo de desktop, cada árvore cresce até que um nó seja impossível de dividir ou um nó atinja o número mínimo de casos para dividir um nó interno. O número mínimo de casos é uma opção para a análise. Para o aplicativo web, a análise adiciona a restrição de que cada árvore tem um limite de 4.000 nós terminais. Para obter mais detalhes sobre a construção de uma árvore de classificação, vá para Métodos de divisão de nós em Classificação CART®. Detalhes específicos para Random Forests® a seguir.
Amostras por bootstrap
Para construir cada árvore, o algoritmo seleciona uma amostra aleatória com substituição (amostra por bootstrap) do conjunto de dados completo. Normalmente, cada amostra por bootstrap é diferente e pode conter um número diferente de linhas únicas do conjunto de dados original. Se você usar apenas a validação fora da sacola, então o tamanho padrão da amostra por bootstrap será o tamanho do conjunto de dados original. Se você dividir a amostra em um conjunto de treinamento e um conjunto de teste, então o tamanho padrão da amostra por bootstrap será o mesmo que o tamanho do conjunto de treinamento. Em ambos os casos, você tem a opção de especificar que a amostra por bootstrap é menor do que o tamanho padrão. Em média, uma amostra por bootstrap contém cerca de 2/3 das linhas de dados. As linhas únicas de dados que não estão na amostra por bootstrap são os dados fora da sacola para validação.
Seleção aleatória de preditores
Em cada nó na árvore, o algoritmo seleciona aleatoriamente um subconjunto do número total de preditores, 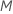 , para avaliar como divisores. Por padrão, o algoritmo escolhe
, para avaliar como divisores. Por padrão, o algoritmo escolhe  preditores para avaliar em cada nó. Você tem a opção de escolher um número diferente de preditores para avaliar, de 1 a
preditores para avaliar em cada nó. Você tem a opção de escolher um número diferente de preditores para avaliar, de 1 a 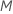 . Se você escolher
. Se você escolher 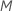 preditores, então o algoritmo avaliará cada preditor em cada nó, resultando em uma análise com o nome “bootstrap forest”.
preditores, então o algoritmo avaliará cada preditor em cada nó, resultando em uma análise com o nome “bootstrap forest”.
Em uma análise que utiliza um subconjunto de preditores em cada nó, os preditores avaliados são geralmente diferentes em cada nó. A avaliação de diferentes preditores torna as árvores na floresta menos correlacionadas umas com as outras. As árvores menos correlacionadas criam um efeito de aprendizagem lento para que as predições melhorem à medida que você constrói mais árvores.
Validação com dados fora da sacola
As linhas únicas de dados que não fazem parte do processo de construção de árvores para uma determinada árvore são os dados fora da sacola. Cálculos para medidas de desempenho do modelo, como a probabilidade média de registro, fazem uso dos dados fora da sacola. Para obter mais detalhes, vá para Métodos e fórmulas para o sumário do modelo em Classificação Random Forests®.
Para uma determinada árvore na floresta, um voto de classe para uma linha nos dados fora da sacola é a classe predita para a linha da única árvore. A classe predita para uma linha em dados fora da sacola é a classe com o maior voto em todas as árvores da floresta.
A probabilidade de classe predita para uma linha nos dados fora da sacola é a razão do número de votos para a classe e o total de votos para a linha. A validação do modelo usa as classes preditas, as probabilidades de classe preditas e os valores reais de resposta para todas as linhas que aparecem pelo menos uma vez nos dados fora da sacola.
Determinação da classe predita para uma linha no conjunto de treinamento
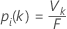
em que Vk é o número de árvores que votam nessa linha i e está na classe k, e F é o número de árvores na floresta.