Observação
Este comando está disponível com o Módulo de análise preditiva. Clique aqui saber mais sobre como ativar o módulo.
Uma equipe de pesquisadores coleta e publica informações detalhadas sobre fatores que afetam doenças cardíacas. As variáveis incluem idade, sexo, níveis de colesterol, frequência cardíaca máxima e muito mais. Este exemplo é baseado em um conjunto de dados públicos que fornece informações detalhadas sobre doenças cardíacas. Os dados originais são de archive.ics.uci.edu.
Após a exploração inicial com Classificação CART® para identificar os preditores importantes, os pesquisadores usam Classificação TreeNet® e Classificação Random Forests® para criar modelos mais aprofundados a partir do mesmo conjunto de dados. Os pesquisadores comparam a tabela de sumário do modelo e o gráfico ROC dos resultados para avaliar qual modelo proporciona um resultado de predição melhor. Para os resultados das demais análises, vá para Exemplo de Classificação CART® e Exemplo de Ajuste de modelo com Classificação TreeNet®.
- Abra os dados amostrais, BinarioDeDoencasCardiacas.MWX.
- Selecione .
- Na lista suspensa, selecione Resposta binária.
- Em Resposta, digite 'Doença cardíaca'.
- Em Evento de resposta, selecione Sim para indicar que a doença cardíaca foi identificada no paciente.
- Em Preditores contínuos, insira Idade, 'Pressão Arterial de descanso', Colesterol, 'Max Heart Rate', e 'Pico Antigo'.
- Em Preditores categóricos, insira Sexo, 'Tipo de dor torácica', 'Açúcar no sangue em jejum', 'Resto ECG', 'Exercício Angina', Inclinação, 'Principais Navios', e Thal.
- Clique em OK.
Interprete os resultados
Para esta análise, o número de observações é de 303. Cada uma das 300 amostras por bootstrap usa as 303 observações para criar uma árvore. Os dados incluem uma boa divisão de não eventos e eventos.
Método
| Validação do modelo | Validação com dados usando método out-of-bag |
|---|---|
| Número de amostras bootstrap | 300 |
| Tamanho amostral | O mesmo que o tamanho dos dados de treinamento de 303 |
| Número de preditores selecionados para divisão de nós | Raiz quadrada do número total de preditores = 3 |
| Tamanho mínimo do nó interno | 2 |
| Linhas usadas | 303 |
Informações de resposta binária
| Variável | Classe | Contagem | % |
|---|---|---|---|
| Doença cardíaca | Sim (Evento) | 139 | 45,87 |
| Não | 164 | 54,13 | |
| Todos | 303 | 100,00 |
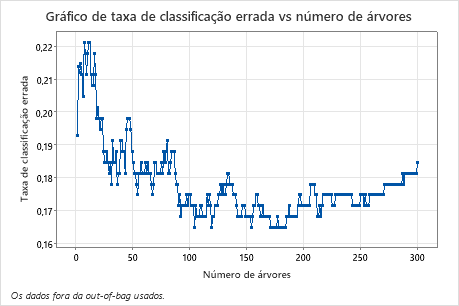
A taxa de classificação errada vs número de árvores mostra toda a curva sobre o número de árvores cultivadas. A taxa de classificação errada é de aproximadamente 0,18.
Sumário do modelo
| Preditores totais | 13 |
|---|---|
| Preditores importantes | 13 |
| Estatísticas | Out-of-Bag |
|---|---|
| -Log da Verossimilhança Média | 0,4004 |
| Área sob a curva ROC | 0,9028 |
| IC de 95% | (0,8693; 0,9363) |
| Elevação | 2,1079 |
| Taxa de classificação errada | 0,1848 |
Sumário do modelo
| Preditores totais | 13 |
|---|---|
| Preditores importantes | 13 |
| Número de árvores cultivadas | 500 |
| Número ótimo de árvores | 351 |
| Estatísticas | Treinamento | Teste |
|---|---|---|
| -Log da Verossimilhança Média | 0,2341 | 0,3865 |
| Área sob a curva ROC | 0,9825 | 0,9089 |
| IC de 95% | (0,9706; 0,9945) | (0,8757; 0,9421) |
| Elevação | 2,1799 | 2,1087 |
| Taxa de classificação errada | 0,0759 | 0,1750 |
A tabela de sumário do modelo mostra que o log-verossimilhança negativo médio é de 0,3994. Essas estatísticas indicam um modelo semelhante ao que o Minitab TreeNet® cria quando cultiva 500 árvores. Além disso, as taxas de classificação errada são semelhantes.
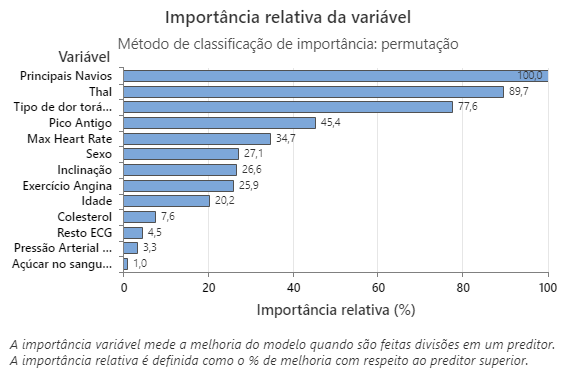
O gráfico de importância relativa da variável representa os preditores por ordem de seu efeito sobre a melhoria do modelo quando as divisões são feitas em um preditor sobre a sequência de árvores. A variável preditora mais importante é Vasos principais. Se a contribuição da variável preditora superior, Vasos principais,, for de 100%, então a próxima variável importante, Thal, tem uma contribuição de 89,7%. Isso significa que Thal é 89,7% tão importantes quanto Vasos principais neste modelo de classificação.
Matriz de confusão
| Classe predita (Out-of-Bag) | ||||
|---|---|---|---|---|
| Classe real | Contagem | Sim | Não | % Correto |
| Sim (Evento) | 139 | 109 | 30 | 78,42 |
| Não | 164 | 26 | 138 | 84,15 |
| Todos | 303 | 135 | 168 | 81,52 |
| Estatísticas | Out-of-Bag (%) |
|---|---|
| Taxa de positivo verdadeiro (sensibil. ou poder) | 78,42 |
| Taxa de positivo falso (erro tipo I) | 15,85 |
| Taxa de negativo falso (erro tipo II) | 21,58 |
| Taxa de negativo verdadeiro (especificidade) | 84,15 |
A matriz confusão mostra se o modelo separa as classes bem e corretamente. Neste exemplo, a probabilidade de um evento ser predito corretamente é de 78,42%. A probabilidade de que um não evento ser predito corretamente é de 84,15%.
Classificação errada
| Out-of-Bag | |||
|---|---|---|---|
| Contagem | Classificado errado | % de erro | |
| Classe real | |||
| Sim (Evento) | 139 | 30 | 21,58 |
| Não | 164 | 26 | 15,85 |
| Todos | 303 | 56 | 18,48 |
A taxa de classificação errada ajuda a indicar se o modelo irá predizer novas observações com exatidão. Para predição de eventos, o erro de classificação errada do é de 21,58%. Para a predição de não evento, o erro de classificação errada é de 15,85% e, no geral, o erro de classificação errada é de 18,48%.
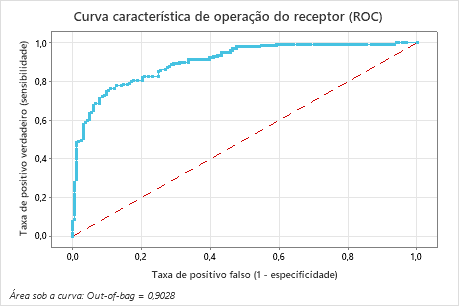
A área sob a curva ROC para esses dados é de aproximadamente 0,9028, o que mostra uma leve melhora em relação ao modelo Classificação CART®. O modelo Classificação TreeNet® tem um teste AUROC de 0,9089, de modo que esses dois métodos produzem resultados semelhantes.
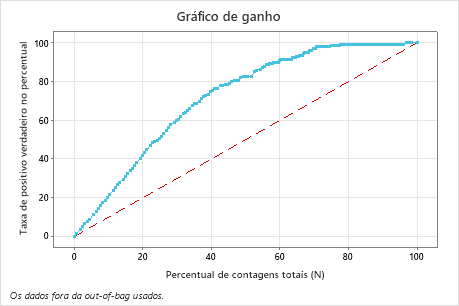
Neste exemplo, o gráfico de ganho mostra um aumento acentuado acima da linha de referência, em seguida, um achatamento. Neste caso, aproximadamente 40% dos dados representam aproximadamente 78% dos positivos verdadeiros. Essa diferença é o ganho extra com o uso do modelo.
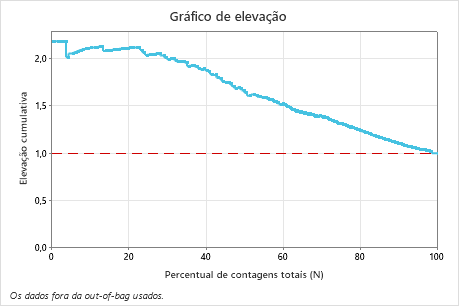
Neste exemplo, o gráfico de elevação mostra um grande aumento acima da linha de referência que cai gradualmente.